Содержание
Алгоритмы ранжирования
Категория: Дорвеи.
Алгоритм ранжирования — способ, при помощи которого определяется ценность определенной страницы в системе поиска.
Итак, что же влияет на наш результат?
- Рейтинг сайта
- Плотность ключевых слов в тексте
- Уникальность и релевантность контента
- Объем текстов
- Мета-теги страниц
- Количество и качество внешних ссылок
- Поведенческие факторы внутри сайта
- Релевантность отдаваемого контента
- Траст
- Возраст сайта
У каждой Поисковой системы свои алгоритмы! У гугла одни, у яндекса другие, у бинга третьи.
Бинг — это гугл застрявший году так в 2007, т.е. рулят ссылки в больших объемах. В целом качество ссылок не так важно.
Гугл огромен, ежемесячно серверы Google обрабатывают порядка 100 млрд запросов, ежедневно гугл обрабатывает 500 млн поисковых запросов.
Первая и пожалуй основная цель поисковых систем — отдавать пользователю «Релевантный» ответ.
Т.е. вводим в поиск «Слон», нам отдается ответ о слонах.
По этому рекомендуется использовать в своих дорвеях «Релевантный контент». Копипаст, мешанину, что угодно. Но релевантный.
У поисковых систем есть свои поисковые роботы. Пауки, цель которых находить новые страницы и заносить в свою базу данных.
Бывают так же «дятлы», которые простукивают Ваш сайт, чтобы определить, что он доступен.
Роботы не анализируют Ваш контент, они передают на сервера, где и происходит обработка.
Быстробот яндекса
Быстробот — это алгоритм яндекса, который дает бонус «новому контенту».
Быстробот любят дорвейщики и особенно активно используют в сложных нишах. Рядом с материалами, добавленными быстророботом, система пишет, сколько часов назад был опубликован файл.
Свежая новость имеет высокие шансы попасть в ТОП 10, поскольку ее релевантность рассчитывается на основании внутренних факторов.
Когда документ проиндексирует основной бот, на нее начинают распространяться основные алгоритмы ранжирования. В результате страница может потерять свои позиции.
В результате страница может потерять свои позиции.
Есть люди, которые работают чисто на быстробота. Делают дорвеи по определенных ключам, они вылазят в топ, висят сутки-двое, позиции уходят, делают новые и так по циклу. Тут в целом важно лишь 1 правило, что бы количество денег потраченное на трафик было меньше, чем доход с этого трафика.
Яндекс параноидальный, индексирует дольше гугла или бинга. У яндекса есть такое понятие как АПЫ, а еще он перешел на ИКС, как метрику. Если закинуть сайт в яндекс вебмастер есть большой шанс поймать метку «Дорвей»
Яндекс очень зацикленный на поведенческих факторах! По этому, если Вы хотите, что бы ваш сайт долго жил и давал трафик, поведенческие на дорвее, должны быть максимально приближены к белому сайту
Ссылочное под бинг
Бинг — это застрявший году в 2007 гугл. Не важно, какого качества ссылки, важно что бы их было мно-о-ого, ну или о-о-очень много. Как раз под бинг можно расчехлить все свои хрумеры, gsa, спамилки. Бинг не настолько популярен как гугл, по этому нужно учитывать, что по ключу с которого идет трафик в гугл, не факт, что будет так же идти трафик в Бинг. Я бы вообще брал здесь ВЧ и СЧ ключевые слова, если вы намерены работать чисто под бинг.
Бинг не настолько популярен как гугл, по этому нужно учитывать, что по ключу с которого идет трафик в гугл, не факт, что будет так же идти трафик в Бинг. Я бы вообще брал здесь ВЧ и СЧ ключевые слова, если вы намерены работать чисто под бинг.
Достаточно плохо заходят дешевые домены вроде .win .loan и прочие до 1$.
Мало кто знает, но у бинга тоже есть своя вебмастер консоль Опять же сильно выражено явление рандома… При прочих равных, 2 одинаковых сайта могут занять абсолютно разные позиции. Один может быть в топе, а другой в жо…
Google — гигант
Как бы это парадоксально не звучало, считают гугл самым «Стабильным» поисковиком. Он индексирует огромные объемы и вполне можно затеряться среди армии белых сайтов. Пауки гугла работают на ура, индексация здесь очень быстрая.
Важно понимать, что индексация в гугл не равно трафик. У вас может быть проиндексировано 40.000 страниц, которые будут давать 20 уников, а может быть проиндексировано 20, которые будут давать больше.
Для проверки индексации есть бесплатная программа XSEOchecker очень удобная и простая!
Выдача динамична и постоянно меняется. Есть в дорвейном лексиконе такое понятие как «Трясет выдачу». Так вот это и означает, что позиции разных сайтов постоянно меняются. Критические изменения можно увидеть на сайте Algoroo
Во времена максимальной тряски рекомендуется переждать и не генерить в этот отрезок времени.
При этом изменения могут затронуть например только какие-то определенные ниши, определенные страны. По этому часто бывает, что у кого то трафик упал, у кого то вырос, а у кого то ничего не изменилось. Это тоже в порядке вещей!
Так же тут отмечаются выходы и обновления поисковых алгоритмов!
1. Панда
Понижает позиции сайтов с низкокачественным контентом.
Определяет спамный, автоматически сгенерированный, бесполезный, низкокачественный контент и понижает его в выдаче. Алгоритм в первую очередь нацеленный на борьбу с нами.
За что можно получить пессимизацию
- Неуникальный контент (плагиат)
- Дублированный контент на разных страницах одного сайта
- Автоматически сгенерированный контент
- Контент, переспамленный ключевыми запросами
- Спамный контент, сгенерированный пользователями (например, комментарии)
- Недостаточное количество контента на странице (по отношению к рекламным блокам, например)
- Плохой пользовательский опыт
2. Пингвин (Google Penguin)
Пингвин (Google Penguin)
Понижает в ранжировании сайты со спамными ссылочными профилями и сайты, манипулирующие ссылочной массой.
В определенные моменты времени, за «Спамные неестественные ссылки» был шанс, что выкинет вообще из выдачи. Но от данной идеи в гугле отказались, я так понимаю из за того, что таким образом просто можно было бы «топить» конкурентов и теперь спамные ссылки просто не учитываются или учитываются минимально.
У гугла есть свой собственный инструмент, с помощью которого можно «Отказаться» от ссылок.
Ссылки\траст пожалуй до сих пор один из самых основных алгоритмов влияющих на топовые позиции.
3. Антипиратский апдейт (Google’s Pirate Update)
Понижает в ранжировании сайты, которые регулярно получают жалобы за содержание пиратского (защищенного авторским правом) контента.
Тут все понятно! Если допустим кто то выложил фильм, а у него есть копирайт.
На сайт можно пожаловаться на нарушение авторских прав, DMCA.
Этим иногда злоупотребляют конкуренты.
Наиболее затрагиваемый контент фильмы, музыка, книги, доступные для скачивания или просмотра. Торрент-треккеры и сайты-агрегаторы ссылок на файлообменники, формально они не хранят запрещенные файлы, но предоставляют информацию о том, как их скачать из сети.
Накладывается за содержание на сайте пиратского контента или информации о том, как получить такой контент в обход правообладателя.
4. Колибри (Hummingbird)
Его цель предоставлять более релевантные результаты, основываясь на смысловой составляющей поискового запроса.
Другими словами теперь мало напичкать страницу нужным ключом, что бы он вышел в топ. Гугл так же смотрит соответствие по смыслу, ищет похожие тематические фразы, синонимы.
Другими словами алгоритм борется с «Переспамом» ключевых слов.
5. Голубь (Pigeon)
Предоставляет более релевантные результаты локального поиска.
Алгоритм региональной выдачи. Вы можете присвоить своему сайту определенный регион и ранжироваться там выше.
Несмотря на ожидания многих специалистов, в основном коснулся только англоязычного сегмента. После выхода этого алгоритма местонахождение пользователя и его расстояние до объекта, предлагаемого как результат выдачи, стали учитываться как факторы ранжирования.
6. Mobile Friendly Update
Повышает оптимизированные для мобильных устройств страницы в результатах поиска на мобильном устройстве.
Другими словами гугл работает над тем, что бы пользователям было удобно пользоваться интернетом. А пожалуй 70% текущей выдачи становится мобильной. Для борьбы с неудобными сайтами был введен этот алгоритм.
Проверить оптимизирован ли ваш сайт под мобильные устройства можно здесь.
Можно использовать к примеру Boostrap шаблоны. Я действительно иногда проверяю свои шаблоны на оптимизацию и те, что не проходят удаляю!
7. RankBrain
Его цель предоставить пользователю лучшие результаты, основанные на релевантности и машинном обучении.
Я думаю не открою никому америку, если расскажу, что гугл, да и вообще поисковые системы, социальные сети, крупнейшие гиганты следят за Вами.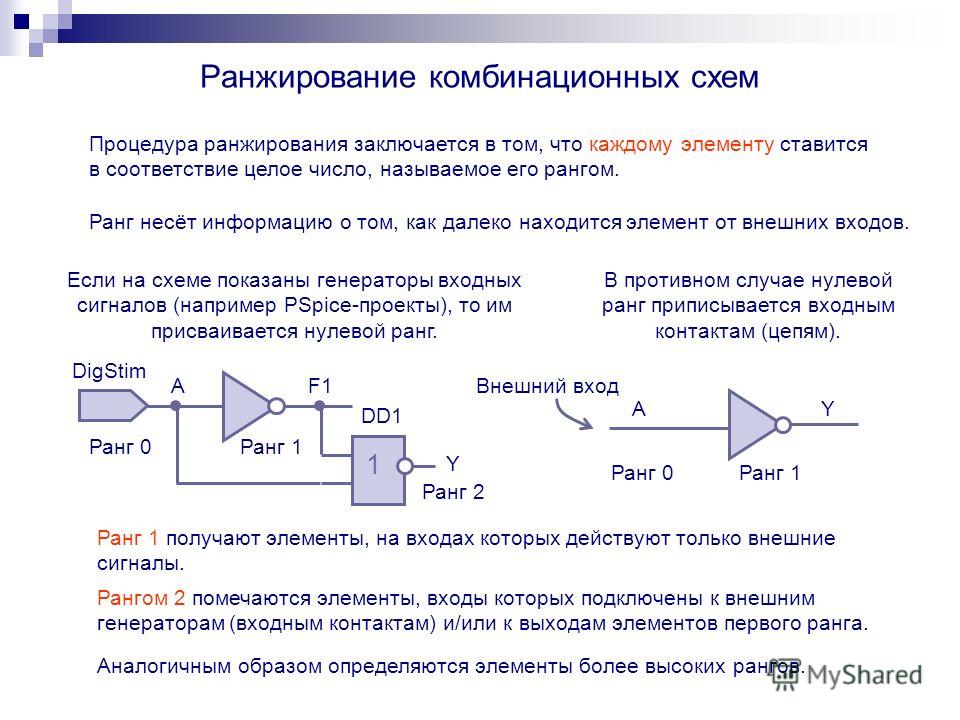 )
)
Данный алгоритм анализирует поведение пользователей на Вашем сайте, в результате чего определяет достоин ли Ваш сайт быть на той позиции, где он находится или же нет. Мое личное мнение, что используются различные гугл плагины, браузер Crome, гугл метрики, включая гугл аналитикс.
Другими словами, чем дольше залипают на сайте ваши пользователи, чем меньше из них потом снова возвращается в гугл с этим же запросом, тем лучше для вашего сайта/дорвея.
8. Опоссум (Possum)
Цель его предоставлять лучшие, более релевантные результаты локальной выдачи, основываясь на местонахождении пользователя.
Благодаря этому алгоритму местонахождение пользователя стало еще более важным фактором для показа того или иного результата из Local Business — чем ближе пользователь к адресу компании, тем с большей вероятностью данный результат будет присутствовать в выдаче.
Если я ищу кафе и сам нахожусь на тверской у меня включена галочка «Определять мое местоположение», гугл может показать мне ближайшие кафе.
9. Фред (Fred)
Цель отфильтровывать низкокачественные страницы из результатов поиска, чьей целью является прибыль от размещения рекламы и ссылок на другие сайты
Пожалуй каждому из нас однажды попадались сайты, на которых 70-80% контента — это реклама.
Она повсюду, ее настолько много, что мы с трудом можем найти то, за чем пришли!
Именно для борьбы с подобными сайтами и был создан данный алгоритм.
В первую очередь могут пострадать:
- Сайты, злоупотребляющие баннерной, pop-up и другими видами рекламы
- Сайты со статьями написанными специально для роботов поисковых систем с целью генерации трафика
- Сайты с большим количеством исходящих ссылок
Другими словами, слишком сильно не грешим с рекламой, не переусердствуем с внешней перелинковкой!
И как бы все не звучало страшно и не казалось, что все алгоритмы нацелены на Вас, на деле всегда все работает иначе! Алгоритмы — это нейросеть, они не идеальны, алгоритмы можно и нужно «Щупать» искать слабые места, что бы потом максимально забить выдачу своими сайтами.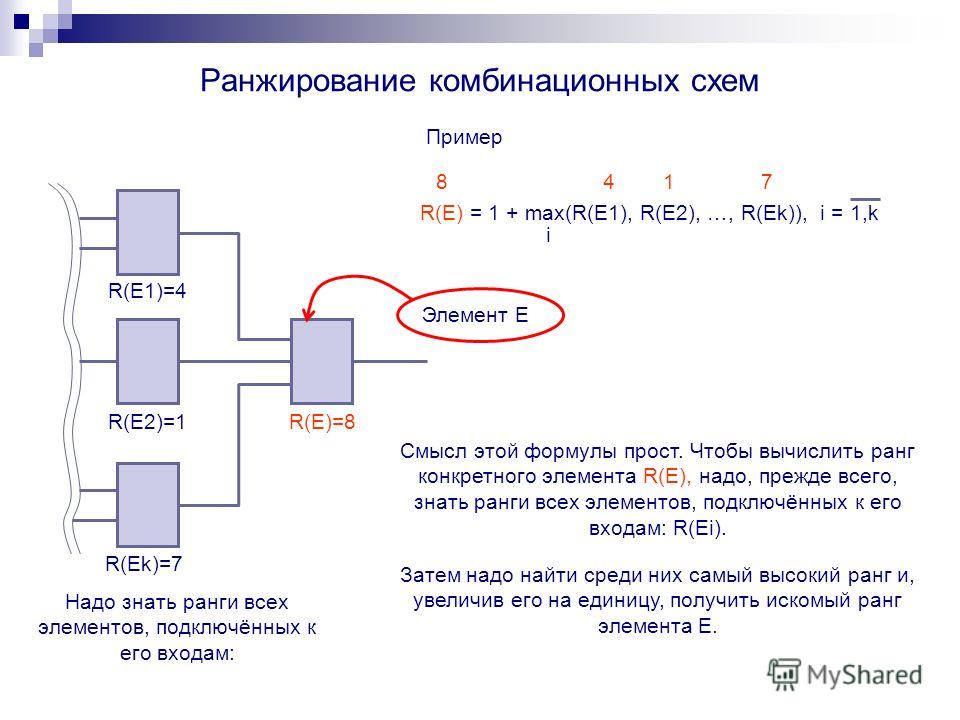 Знание алгоритмов — дает знание о том, как их можно обойти!
Знание алгоритмов — дает знание о том, как их можно обойти!
И это лишь основные факторы ранжирования, считается, что всего их более 200 и любая мелочь +- может повлиять на Ваш результат.
Алгоритмы ранжирования Google
Алгоритмы ранжирования Яндекс
Рекомендации для WebmasterА Google
Рекомендации для WebmasterА Яндекс
Существуют так же такие региональные поисковики как — seznam — Чехия или baidu — Китай.
Вывод:
Если вкратце пройтись. Дорвеи не должны быть переспамлены ссылками. Контент в идеале должен быть «Релевантным». Поисковики пусть еще и не до конца понимают смысл, но понимают, когда там что то не то.
Времена, когда можно было взять текстовку из электронных книг и это заходило. Контент не должен быть переспамлен ключами. Очень даже полезно добавлять тематические ключи из этой тематики. Агрессивная реклама, когда ее слишком много — может быть пессимизированна. Слишком много спамных ссылок могут либо перестать учитываться, либо навредить позициям.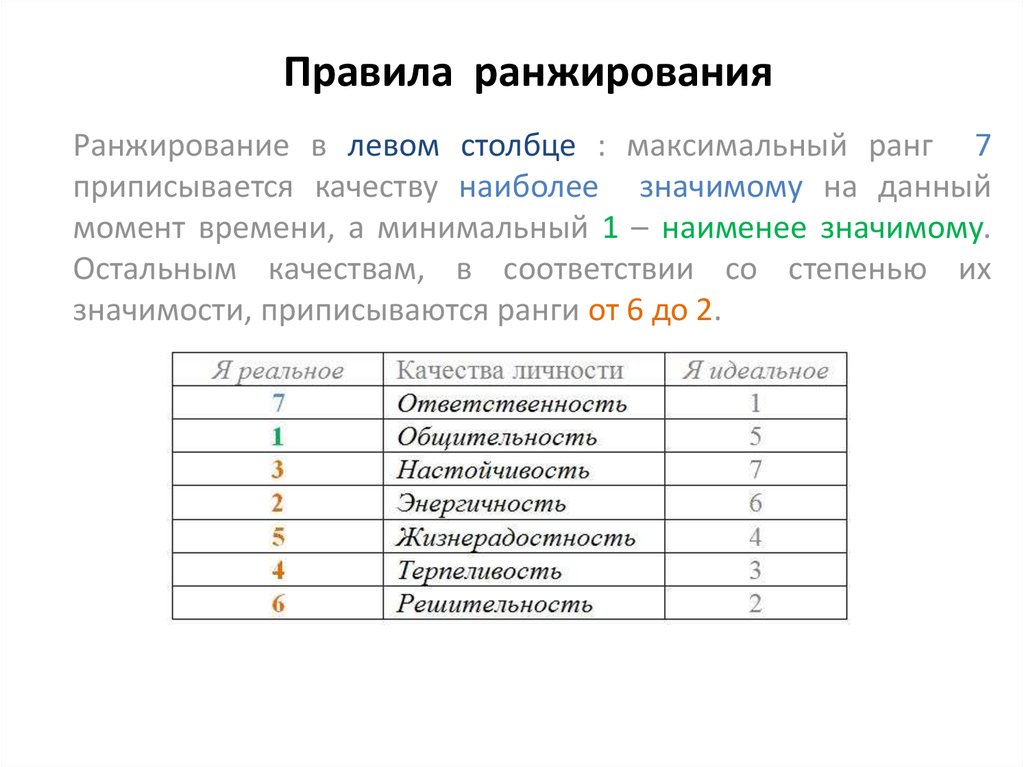 Плохие поведенческие так же влияют на позиции. Дорвей в идеале должен быть оптимизирован под мобильную выдачу, проверить это можно здесь! Не забываем про «Локальную выдачу».
Плохие поведенческие так же влияют на позиции. Дорвей в идеале должен быть оптимизирован под мобильную выдачу, проверить это можно здесь! Не забываем про «Локальную выдачу».
Ну и конечно же в первую очередь сражаемся с пандой, цель которой как раз подъедать дорвеи и не давать им прорваться высоко.
Вся правда про алгоритм ранжирования как есть.
Подпишись на “Где Трафик”
2к+
Аналитика
29 июл, 2022
2к+
0
Алгоритм LinkedIn: как он работает в 2022 году
Хола, котаны! Как и все другие социальные сети, LinkedIn полагается на алгоритмы при показах контента аудитории. И, как и любой другой алгоритм, он опирается на множество факторов для принятия решений. Чтобы не потеряться и быть уверенным, что твою рекламу точно увидит нужный человек, тебе нужно шарить в этих факторах. Как ты понял, сегодня говорим о том, что за волшебная формула при которой LinkedIn работает на тебя. Полное руководство по алгоритму соцсети в 2022 году. Погнали!
LinkedIn
,
алгоритмы
,
алгоритм ранжирования
,
алгоритмы LinkedIn
,
Профиль в LinkedIn
,
Линкедин
Прочитай за 14 минут
Свежие новости
26 апр, 2022
2к+
0
Instagram будет повышать в выдаче оригинальный контент
Утро, котаны! Глава Instagram Адам Моссери поделился новыми апдейтами Instagram: теги продуктов, расширенные теги и новый алгоритм ранжирования с фокусом на оригинальный контент. Похоже, Инсте не очень нравится продвигать за свой счет копипасту из ТикТок. Давай посмотрим, какие изменения ждать в скором времени.
Instagram
,
SMM
,
Видео контент
,
Инстаграм
,
Reels
,
Контент-маркетинг
,
алгоритм ранжирования
,
IGTV
,
TikTok
,
Instagram Reels
Прочитай за 4 минуты
Аналитика
01 ноя, 2021
5к+
0
Как работают алгоритмы Twitter: особенности работы с платформой Твиттер
Хола, котаны! Маркетинг в Twitter — это непросто. Алгоритм ранжирования – уникальный инструмент в борьбе за внимание пользователя. В среднем в день отправляется 500 миллионов твитов, поэтому освоение алгоритмов Twitter не даст вам потеряться в шуме. Сегодня мы разберемся, как одни посты попадают в топ, а другие залегают на морское дно, но прежде давайте рассмотрим алгоритм ранжирования в Twitter.
Twitter
,
алгоритмы
,
трафик из твиттера
,
алгоритм
,
Твиттер
,
алгоритм ранжирования
,
Twitter Media
Прочитай за 12 минут
Аналитика
18 окт, 2021
5к+
0
Как работают рекомендации Ютуб
Хола, котаны! С момента своего запуска в 2005 году YouTube стал больше, чем просто платформой для загрузки, обмена и просмотра видео. Сейчас это вторая по величине поисковая система в мире. У YouTube есть несколько алгоритмов ранжирования контента на главной странице, в результатах поиска и предлагаемых видео. Попасть в реки легче, если знаете, как работают алгоритмы YouTube и подгоняете под них контент. В этой статье мы разберем, как работают алгоритмы YouTube и как вы можете извлечь из них максимальную пользу.
алгоритмы Google
,
YouTube
,
ключевые слова
,
рекомендации
,
алгоритм основной выдачи
,
алгоритмы
,
Видео контент
,
Видеосеть
,
алгоритм ранжирования
,
YouTube Analytics
,
как работать с аналитикой
,
реклама в ютуб
Прочитай за 11 минут
Свежие новости
16 сен, 2019
2к+
0
Google изменяет алгоритм ранжирования в поисковой выдаче
Привет, котаны! Google решил, что пришло время поддержать создателей оригинального контента и новостей. Им будет отдано предпочтение в поисковой выдаче, и для этого компания изменит алгоритм ранжирования.
Google
,
контент
,
поисковая выдача
,
алгоритм ранжирования
,
Контент
Прочитай за 3 минуты
Свежие новости
19 ноя, 2018
1к+
0
Яндекс представил усовершенствованный поиск «Андромеда»
Привет, котаны! Команда Яндекса объявила о масштабном обновлении поискового алгоритма под названием «Андромеда». У алгоритма 3 главных направления: быстрые ответы, «Коллекции» и помощь при выборе источников. А нативность — отличительная черта нового поиска.
Яндекс
,
рекомендации
,
поисковая выдача
,
быстрые ответы
,
алгоритм ранжирования
,
Андромеда
,
нативность
Прочитай за 3 минуты
Аналитика
06 июн, 2018
3к+
0
SEO теперь сложнее? Как изменилась поисковая оптимизация за последние несколько лет?
Хола, парни! Сегодня поговорим о SEO. Поисковая оптимизация хоть и воспринимается многими как танцы с бубном, тем не менее является не самым дорогим источником продвижения. И если вы все-таки задумываетесь о том, чтобы привлекать органический трафик на свой сайт, необходимо получить представление о работе поисковых систем. Ниже публикуем перевод статьи Барри Шварца об обновлениях поисковиков за последние годы.
алгоритмы Google
,
Google
,
SEO
,
контент
,
SEO-контент
,
SEO-оптимизация
,
алгоритм основной выдачи
,
google Тренды
,
алгоритм ранжирования
Прочитай за 6 минут
Свежие новости
30 мая, 2018
3к+
0
Как работает алгоритм ранжирования постов в Facebook, Twitter, Instagram, LinkedIn и Pinterest
Алгоритм ранжирования – уникальный инструмент в борьбе за внимание пользователя и, не удивительно, что социальные гиганты улучшают его из года в год. Необходимо понимать как работают платформы, чтобы оптимизировать свой контент. Поговорим о ранжировании простыми словами и разберемся, как одни посты попадают в топ ленты, а другие тонут на дне морском.
инфографика
,
Инфографика
,
алгоритмы Facebook
,
алгоритм ранжирования
,
алгоритмы Twitter
,
алгоритмы Instagram
,
алгоритмы LinkedIn
,
алгоритмы Pinterest
Прочитай за 5 минут
алгоритмов ранжирования — знайте свои методы решения многокритериальных решений! | Мохит Маянк
Давайте рассмотрим некоторые из основных алгоритмов для решения сложных задач принятия решений, зависящих от множества критериев.
Мы обсудим, зачем нам нужны такие методы, и рассмотрим доступные алгоритмы в крутом пакете skcriteria python
Фото Джошуа Голда из Unsplash
Обновление — март 2022 г.: рекомендуется использовать v0.2.11 пакета для кода, обсуждаемого в статье. Репозиторий кода здесь.
Предположим, вам нужно принять решение — например, купить дом, машину или даже гитару. Вы не хотите выбирать случайным образом или быть предвзятым из-за чьего-то предложения, но хотите принять взвешенное решение. Для этого вы собрали некоторую информацию о объекте, который хотите купить (допустим, это автомобиль). Итак, у вас есть список автомобилей N с информацией об их ценах. Как обычно, мы не хотим тратить больше, мы можем просто отсортировать автомобили по их цене (в порядке возрастания) и выбрать лучший (с наименьшей ценой), и все готово! Это было принятие решения по одному критерию. Но увы, если жизнь так проста 🙂 Еще хотелось бы, чтобы у машины был хороший пробег, двигатель получше, разгон побыстрее (если хочется погонять) и еще кое-что. Здесь вы хотите выбрать автомобиль с наименьшей ценой, но с наибольшим пробегом и ускорением и так далее. Эта проблема не может быть так легко решена простой сортировкой. Введите многокритериальные алгоритмы принятия решений!
Давайте выберем один набор данных, чтобы было проще визуализировать результат, понять, что на самом деле происходит за кулисами, и, наконец, развить интуицию. Для этого я выбираю набор данных cars. Для каждого автомобиля мы сосредоточимся на подмножестве атрибутов и выберем только 10 строк (уникальные автомобили), чтобы облегчить себе жизнь. Посмотрите на выбранные данные,
10 строк из набора данных cars
Объяснение некоторых атрибутов,
- миль на галлон: мера того, как далеко может проехать автомобиль, если в его бак залить всего один галлон бензина или дизельного топлива (пробег) .
- рабочий объем: рабочий объем двигателя является мерой объема цилиндра, охватываемого всеми поршнями поршневого двигателя. Больше рабочий объем означает больше мощности.

- ускорение: мера того, сколько времени требуется автомобилю для достижения скорости от 0. Чем выше ускорение, тем лучше автомобиль для дрэг-рейсинга 🙂 атрибуты не совпадают. Цена играет в тысячах $, ускорение в десятках секунд и так далее.
- Рассматривать один атрибут за раз и пытаться максимизировать или минимизировать его (согласно требованию) для получения оптимизированной оценки.
- Введите веса для каждого атрибута, чтобы получить оптимизированные взвешенные оценки.
- Объедините взвешенные баллы (каждого атрибута), чтобы получить окончательный балл для объекта (здесь автомобиля).
- как есть : прямое умножение весов для получения оптимизированного результата
- сумма : нормализация весов по логике суммирования (обсуждалась выше), затем умножение.
- max : нормализовать по максимальной логике, затем умножить.
- сумма : сложить все отдельные баллы вместе
- продукт : перемножить все индивидуальные баллы. Фактически, многие реализации добавляют логарифм значения вместо того, чтобы брать произведения, это делается для обработки очень меньшего результата при умножении небольших значений.
-
WeightedSum— логика объединения индивидуальных оценок представляет собой сумму -
WeightedProduct— логика объединения индивидуальных оценок представляет собой произведение (сумма логарифмических) -
wnorm— определить логику нормализации веса
описание каждого из числовых столбцов (атрибутов) выбранных данных
2. Логика наилучшего для каждого атрибута также различается. Здесь мы хотим найти автомобиль с высокими значениями расхода топлива, объема и ускорения. При этом невысокие значения по весу и цене. Это понятие высокого и низкого можно вывести как максимизацию и минимизацию атрибутов соответственно.
3. Может быть дополнительное требование, когда мы не считаем все атрибуты равными. Например, если я хочу машину для гонок и скажу, что меня спонсирует миллиардер, то меня не будут так сильно волновать расход на галлон и цена. Я хочу самую быструю и легкую машину. Но что, если я студент (отсюда, скорее всего, с ограниченным бюджетом) и много путешествую, то вдруг расход и цена становятся самым важным атрибутом, и мне наплевать на объем двигателя. Эти понятия важности атрибутов можно вывести как веса, присвоенные каждому атрибуту. Скажем, цена важна на 30%, а водоизмещение всего на 10% и так далее.
Разобравшись с требованиями, давайте попробуем посмотреть, как мы можем решить подобные проблемы.
Большинство основных многокритериальных решателей имеют общую методологию, которая пытается,
После этого мы преобразовали требования в один числовой атрибут (окончательная оценка), и, как и ранее, мы можем сортировать по нему, чтобы получить лучший автомобиль (на этот раз мы сортируем по убыванию, так как мы хотим выбрать автомобиль с максимальным счет). Давайте рассмотрим каждый шаг на примерах.
Увеличить и уменьшить
Помните первый пункт из раздела набора данных, атрибуты имеют очень разные единицы и распределения, которые нам нужно обработать. Одним из возможных решений является нормализация каждого атрибута в пределах одного диапазона. И мы также хотим, чтобы направление добра было одинаковым (независимо от логики). Следовательно, после нормализации значения, близкие к максимальному диапазону (скажем, 1), должны означать, что автомобиль хорош по этому атрибуту, а более низкие значения (скажем, около 0) означают, что они плохие. Мы делаем это с помощью следующей формулы,
логика нормализации для максимизации и минимизации значений атрибута
Посмотрите на первое уравнение для максимизации, одним из примеров является обновление миль на галлон каждого автомобиля путем деления его на сумму миль на галлон всех автомобилей (сумма нормализации). Мы можем изменить логику, просто учитывая максимальное количество миль на галлон или другие формулы. Намерение состоит в том, что после применения этого к каждому атрибуту диапазон каждого атрибута будет одинаковым, и мы можем сделать вывод, что значение, близкое к 1, означает хорошее.
Формула для минимизации почти такая же, как и для максимизации, мы просто инвертируем ее (1 делим на максимизацию) или отражаем ее (путем вычитания из 1), чтобы фактически изменить направление добра (иначе 1 будет означать плохое, а 0 будет значит хорошо). Посмотрим, как это выглядит на практике,
Пример тепловой карты нормализации суммы исходных данных. Проверьте значение «миль на галлон» для «Форд Торино». Первоначально это 17, но после нормализации суммы должно быть 17/156 = 0,109. Точно так же «цена» равна 20k, после обратного преобразования она будет равна 1/(20k/287872) = 14,4
Применение весов
Нам просто нужно наложить вес на оптимизированные оценки, что можно легко сделать, умножив веса на оптимизированная оценка. Здесь также мы можем ввести различные типы нормализации,
логика изменения веса
Объединить баллы
Наконец, мы объединим баллы, чтобы сделать их одним. Это можно сделать двумя разными способами:
Существует очень хороший пакет Python с именем skcriteria, который предоставляет множество алгоритмов для решения проблемы принятия решений по нескольким критериям. На самом деле два алгоритма внутри модуля skcriteria.madm.simple :
И оба эти метода принимают два параметра в качестве входных данных, логика (минимизация всегда обратна той же логике максимизации).
Чтобы выполнить ранжирование наших данных, сначала нам нужно загрузить их как их0013 skcriteria.Data объект,
загрузка данных в объект данных
После загрузки данных все, что нам нужно сделать, это вызвать соответствующую функцию принятия решений с объектом данных и настройками параметров. В выходных данных есть один дополнительный столбец рангов, чтобы показать окончательный рейтинг с учетом всех упомянутых критериев.
пример логики weightedSum с нормализацией суммы значений
Мы можем даже экспортировать окончательный счет на dec.e_.points и ранги на дес.ранг_ .
Давайте сравним результат различных алгоритмов принятия решений (с разными параметрами) на нашем наборе данных. Для этого я использую реализации weightedSum и weightedProduct (один раз с max , а затем с нормализацией значения sum ). Я также реализовал функцию normalize_data , которая по умолчанию выполняет нормализацию minmax и вычитания. Затем я применяю суммирование на выходе.
5 различных многокритериальных решателей
Наконец, я строю параллельные графики координат, где каждая ось (вертикальная линия) обозначает один тип решателя, а значения обозначают ранг автомобиля этим решателем. Каждая строка предназначена для одной машины и идет слева направо, она показывает путь — как меняется ранг машины, когда вы переключаетесь между разными решателями.
Путешествие автомобиля при смене решателя решений
Несколько очков,
- Ford Torino занимает 1-е место (автомобиль с наивысшим баллом) для решателей 4/5. Minmax отдает предпочтение Chevrolet Malibu.
- Impala — универсальный низкоранговый 🙁
- Обе реализации
weightedProductприсваивают одинаковый рейтинг всем автомобилям. Здесь ничего интересного. самые разнообразные рейтинги для лучших 4 парней.
Основная причина дисперсии результата при изменении нормализации (от суммы до максимума) связана с переводом исходных данных. Этот перевод изменяет диапазон данных (например, масштабирует все между x и y ), а в случае инверсии также изменяет линейность (скажем, равные шаги 1 в исходных данных не соответствуют преобразованным данным). Это станет более ясно из следующего результата:
различных подходов к нормализации и преобразованных данных
. Здесь входные данные состоят из чисел от 1 до 9 (обратите внимание, разница между любыми двумя последовательными числами равна 1, т.е. шаг одинаков). Первый подход (minmax) переводит данные между 0 и 1, а шаг остается тем же. Теперь посмотрим на логику минимизации ( _inverse ) подхода 2 и 3. Здесь в начале (низкие исходные значения) шаг составляет почти половину последнего элемента, но ближе к концу (высокое исходное значение) шаг очень мал, хотя в исходном данные мы двигаем с одинаковым шагом 1.
Из-за этого в случае минимизации очень высокий балл дается «хорошим» автомобилям (с низкими значениями) и даже малому примесному веществу (при минимизации высокое значение = низкая оценка) и приводит к резкому снижению оценки. Мы как бы очень придираемся, либо ты лучший, либо получи половину балла 🙂 С другой стороны, для более высоких значений мелкие примеси не имеют значения. Если автомобиль уже плохой по этому атрибуту, то нам все равно, будет ли его значение 7, 8 или 9.и снижение балла гораздо меньше! Мы можем использовать это понимание, чтобы выбрать правильный решатель с правильным параметром в соответствии с нашими потребностями.
Эта статья только коснулась поверхности многокритериальной области принятия решений. Даже в пакете skcriteria есть гораздо больше алгоритмов, таких как TOPSIS и MOORA, у которых совершенно другая интуиция для решения этих проблем. Но даже тогда во многих из них используется понятие добра и идея обработки отдельных признаков, чтобы в конечном итоге соединить их все вместе. Так что, возможно, мы рассмотрим больше алгоритмов в другой статье.
Но главный вывод из этой статьи должен заключаться в том, чтобы понять, почему и что делают лица, принимающие решения. Что каждое такое решение можно манипулировать несколькими критериями. А также то, что у нас может быть разное представление о доброте и важности, приписываемой каждому критерию. Наконец, у нас есть различные варианты решателей, которые можно построить путем перестановки логики и параметров, и почти все они дают разные и интересные результаты в зависимости от наших потребностей!
[1] Пакет Python Skcriteria
Код и данные из статьи доступны здесь.
Чтобы прочитать больше подобных статей, подпишитесь на меня в LinkedIn или посетите мой веб-сайт.
Удачи.
Как работают алгоритмы ранжирования Reddit | Амир Салихефендич | Взлом и Гонзо
Это продолжение статьи о том, как работает алгоритм ранжирования Hacker News. На этот раз я рассмотрю, как работают истории и комментарии Reddit.
Первая часть этого поста будет посвящена тому, как оцениваются истории Reddit? Вторая часть этого поста будет посвящена рейтингу комментариев, который не использует тот же рейтинг, что и истории (в отличие от Hacker News). Алгоритм ранжирования комментариев Reddit весьма интересен, и автором его идеи является Рэндалл Манро (автор xkcd!)
Reddit имеет открытый исходный код, и код находится в свободном доступе. Reddit реализован на Python, и их код находится здесь. Их алгоритмы сортировки реализованы в Pyrex, языке для написания расширений Python C. Они использовали Pyrex из соображений скорости. Я переписал их реализацию Pyrex на чистый Python, так как его легче читать.
Алгоритм истории по умолчанию, называемый горячим ранжированием, реализован следующим образом:
# Переписанный код из /r2/r2/lib/db/_sorts.pyxиз DateTime Import DateTime, TimeDelta
из Math Import LogEPOCH = DATETIME (1970, 1, 1)
DEF EPOCH_SECONDS (DATE):
TD = DATE -EPOCH 90812 90812 90812 90812 90812 90812 90812 90812 90812 90812 90812 90812 90812 90812 90812 return td.def score(ups, downs):
return ups-downs
9 def
9 def дауны, дата):
с = счет(взлеты, падения)
order = log(max(abs(s), 1), 10)
sign = 1 если с > 0 иначе -1 если с < 0 иначе 0
секунды = epoch_seconds(date) - 1134028003
return round(знак * порядок + секунды / 45000, 7)
В математической записи горячий алгоритм выглядит так:
Эффекты времени подачи :
- Время отправки сильно влияет на рейтинг, и алгоритм будет ранжировать новые истории выше, чем старые
- Оценка не будет уменьшаться с течением времени, но новые истории будут получать более высокие баллы, чем старые. Этот подход отличается от алгоритма Hacker News, который со временем уменьшает оценку на
Вот визуализация оценки статьи, которая имеет одинаковое количество голосов за и против, но разное время подачи:
Шкала логарифмов
Горячий рейтинг Reddit использует функцию логарифма, чтобы взвесить первые голоса выше, чем остальные. Обычно это относится:
- Первые 10 голосов имеют тот же вес, что и следующие 100 голосов, которые имеют тот же вес, что и следующие 1000 и т. д.
Вот визуализация:
Без использования логарифмической шкалы оценка будет выглядеть так:
Эффекты отрицательных голосов
Reddit — один из немногих сайтов, на которых есть отрицательные голоса. Как вы можете прочитать в коде, «оценка» истории определяется как:
Значение этого может быть визуализировано следующим образом:
Это оказывает большое влияние на истории, которые получают много положительных и отрицательных голосов (например, спорные истории). ), так как они получат более низкий рейтинг, чем истории, которые просто получают положительные отзывы. Это могло бы объяснить, почему котята (и другие не вызывающие споров истории) занимают такое высокое место 🙂
Заключение рейтинга историй Reddit
- Время отправки — очень важный параметр, как правило, новые истории будут иметь более высокий рейтинг, чем старые
- Первые 10 голосов засчитываются так же высоко, как и следующие 100. история, набравшая 10 голосов «за», и история, набравшая 50 голосов «за», будет иметь одинаковый рейтинг
- Спорные истории, получившие одинаковое количество голосов «за» и «против», получат более низкий рейтинг по сравнению с историями, получившими в основном «за»
Рэндалл Манро из xkcd автор идеи лучшего рейтинга Reddit. Он написал об этом отличный пост в блоге:
- новая система сортировки комментариев Reddit
Вы должны прочитать его сообщение в блоге, так как оно очень понятно объясняет алгоритм. Схема его сообщения в блоге выглядит следующим образом:
- Использование горячего алгоритма для комментариев не так уж разумно, так как он, кажется, сильно предвзято относится к комментариям, опубликованным ранее
- В системе комментариев вы хотите ранжировать лучшие комментарии выше всех время их подачи
- Решение для этого было найдено в 1927 Эдвина Б. Уилсона, и он называется «интервал оценки Уилсона», интервал оценки Уилсона может быть преобразован в «доверительную сортировку»
- Доверительная сортировка рассматривает подсчет голосов как статистическую выборку гипотетического полного голосования всеми — как в опрос общественного мнения
- Как не сортировать по среднему рейтингу более подробно описывается рейтинг доверия, определенно рекомендуется к прочтению!
Копание в коде ранжирования комментариев
Алгоритм доверительной сортировки реализован в _sorts. pyx, я переписал их реализацию Pyrex на чистый Python (также обратите внимание, что я удалил их оптимизацию кэширования):
Доверительная сортировка использует интервал баллов Уилсона, и математическая запись выглядит следующим образом:
В приведенной выше формуле параметры определяются следующим образом:
- p — наблюдаемая доля положительных оценок
- n — общее количество оценок
- zα/2 – квантиль (1-α/2) стандартного нормального распределения
Подытожим вышеизложенное следующим образом: гипотетическое полное голосование всеми
У Рэндалла есть отличный пример того, как сортировка достоверности ранжирует комментарии в его сообщении в блоге:
но так как данных не очень много, система будет держать их ближе к низу.
Эффекты времени подачи: нет!
Самое замечательное в доверительной сортировке то, что время отправки не имеет значения (во многом в отличие от горячей сортировки или алгоритма ранжирования Hacker News). Комментарии ранжируются по достоверности и по выборке данных — т. е. чем больше голосов получает комментарий, тем точнее становится его оценка.
Визуализация
Давайте визуализируем сортировку достоверности и посмотрим, как она ранжирует комментарии. Мы можем использовать пример Рэндалла:
Как видите, сортировка достоверности не зависит от того, сколько голосов получил комментарий, а от того, сколько голосов он получил по сравнению с общим количеством голосов и размером выборки!
Применение вне рейтинга
Как отмечает Эван Миллер, интервал оценки Уилсона имеет приложения вне рейтинга.