Содержание
Robots.txt — инструкция для SEO
25413 222
| SEO | – Читать 12 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ROBOTS.TXT
Ильхом Чакканбаев
Автор блога Seopulses.ru
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
Содержание
1. Зачем robots.txt нужен на сайте
2. Где можно найти файл robots.txt и как его создать или редактировать
3. Как создать и редактировать robots.txt
4. Инструкция по работе с robots.txt
5. Синтаксис в robots.txt
6. Директивы в Robots.txt
— Disallow
— Allow
— Sitemap
— Clean-param
— Crawl-delay
7. Как проверить работу файла robots. txt
txt
— В Яндекс.Вебмастер
— В Google Search Console
Заключение
Зачем robots.txt нужен на сайте
Командами robots.txt называются директивы, которые разрешают либо запрещают сканировать отдельные участки веб-ресурса. С помощью файла вы можете разрешать или ограничивать сканирование поисковыми роботами вашего веб-ресурса или его отдельных страниц, чем можете повлиять на позиции сайта. Пример того, как именно директивы будут работать для сайта:
На картинке видно, что доступ к определенным папкам, а иногда и отдельным файлам, не допускает к сканированию поисковыми роботами. Директивы в файле носят рекомендательный характер и могут быть проигнорированы поисковым роботом, но как правило, они учитывают данное указание. Техническая поддержка также предупреждает вебмастеров, что иногда требуются альтернативные методы для запрета индексирования:
Какие страницы нужно закрыть от индексации
| Читать |
Где можно найти файл robots. txt и как его создать или редактировать
txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как провести анализ индексации сайта
| Читать |
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
WordPress;
Для Opencart;
Webasyst.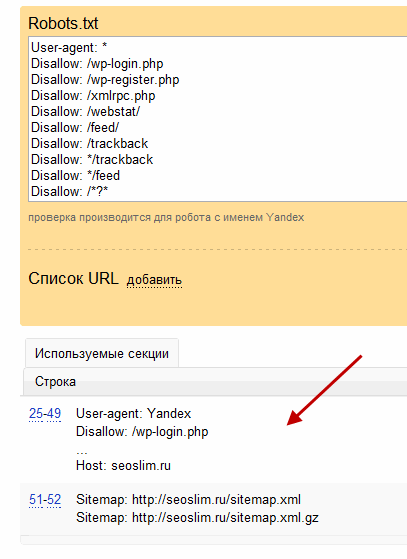
Самые распространенные SEO-ошибки на сайте: инфографика
| Читать |
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
User-agent: Yandex — для обращения к поисковому роботу Яндекса;
User-agent: Googlebot — в случае с краулером Google;
User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Обращения в robots.txt для Яндекса:
Чтобы обозначить обращение для поисковых роботов данной системы применяют такие значения:
Yandex Bot — основной робот, который будет индексировать ваш ресурс;
Yandex Media — робот, который специализируется на сканировании мультимедийной информации;
Yandex Images — индексатор для Яндекс.Картинок;
Yandex Direct — робот, который сканирует страницы веб-площадок, имеющих отношение к рекламе в Яндексе;
Yandex Blogs — робот для поиска в блогах и форумах, который индексирует комментарии в постах;
Yandex News — бот собирающий данные по Яндекс Новостям;
Yandex Pagechecker — робот, который обращается к странице с целью валидировать микроразметку.
Обращения в robots.txt для Google:
Имена используемые для краулеров от Google:
Googlebot — краулер, индексирующий страницы веб-сайта;
Googlebot Image — сканирует изображения и картинки;
Googlebot Video — сканирует всю видео информацию;
AdsBot Google — анализирует качество размещенной рекламы на страницах для компьютеров;
AdsBot Google Mobile — анализирует качество рекламы мобильных версий сайта;
Googlebot News — оценивает страницы для использования в Google Новости;
AdsBot Google Mobile Apps — расценивает качество рекламы для приложений на андроиде, аналогично AdsBot.
Полный список роботов Яндекс и Google.
Синтаксис в robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
# — отвечает за комментирование;
* — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
По умолчанию указывается при любого правила в файле;
$ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Почему сайт не индексируется или
как проверить индексацию сайта в Google и Яндекс
| Читать |
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category2/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
Следует указывать полный URL, когда относительный адрес использовать запрещено;
На нее не распространяются остальные правила в файле robots.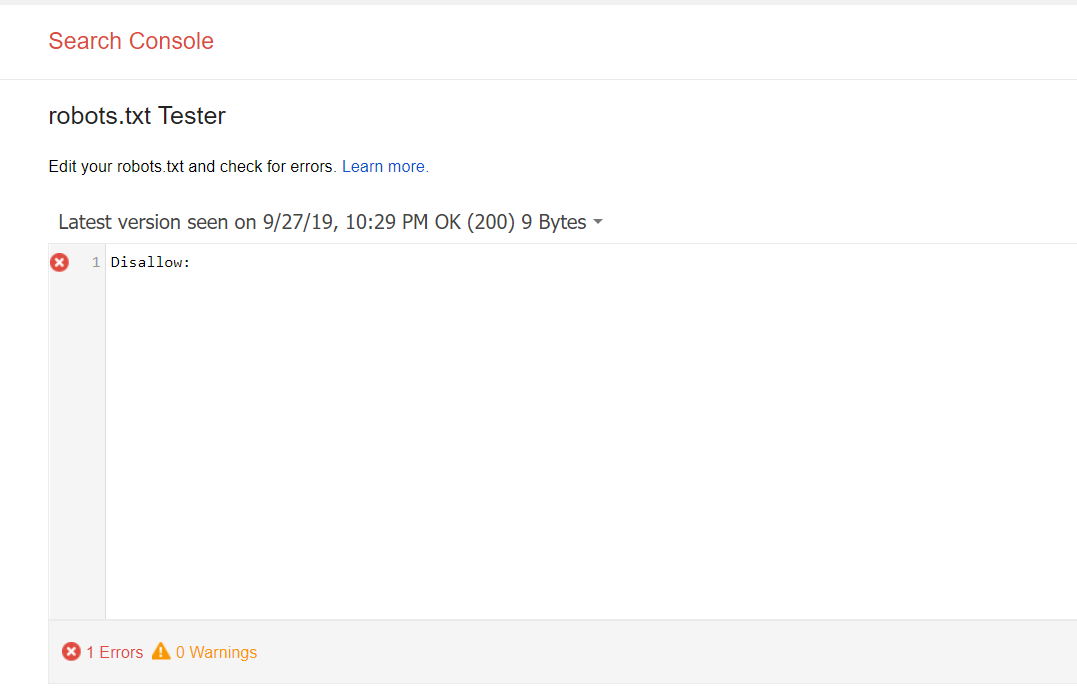 txt;
txt;
XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
Sitemap.xml или карта сайта: как создать и настроить для Google и Яндекс
| Читать |
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www. example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь.
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Хотите узнать, как использовать Serpstat для поиска ошибок на сайте?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Как проверить работу файла robots.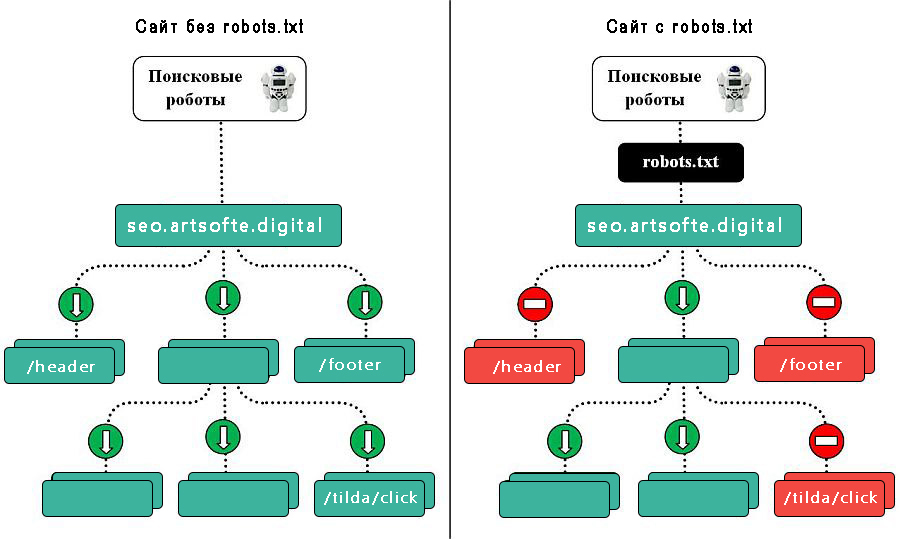 txt
txt
В Яндекс.Вебмастер
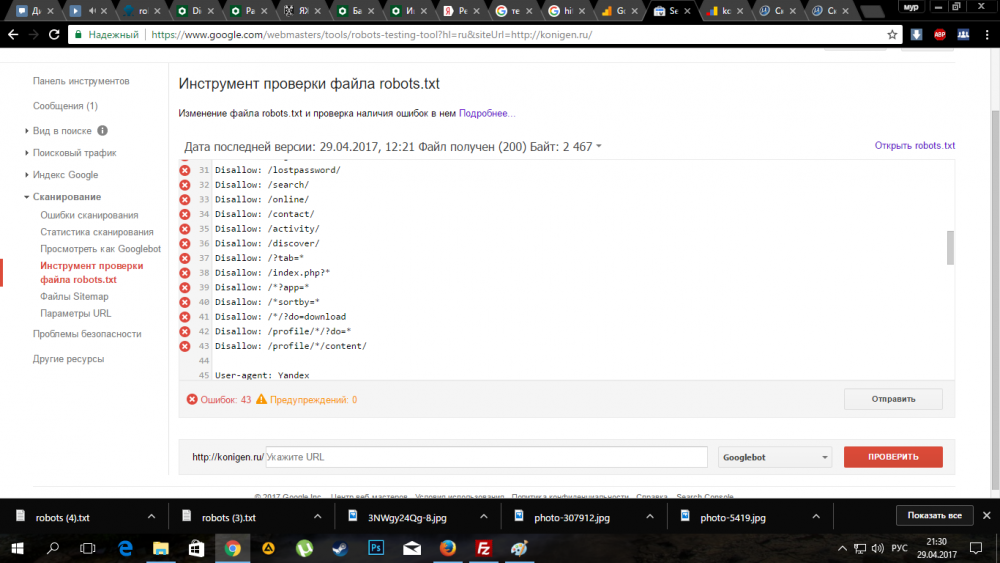
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
Сам файл;
Кнопку, открывающую его;
Симулятор для проверки сканирования.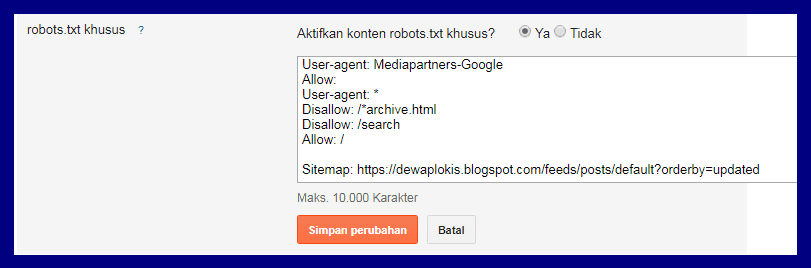
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Заключение
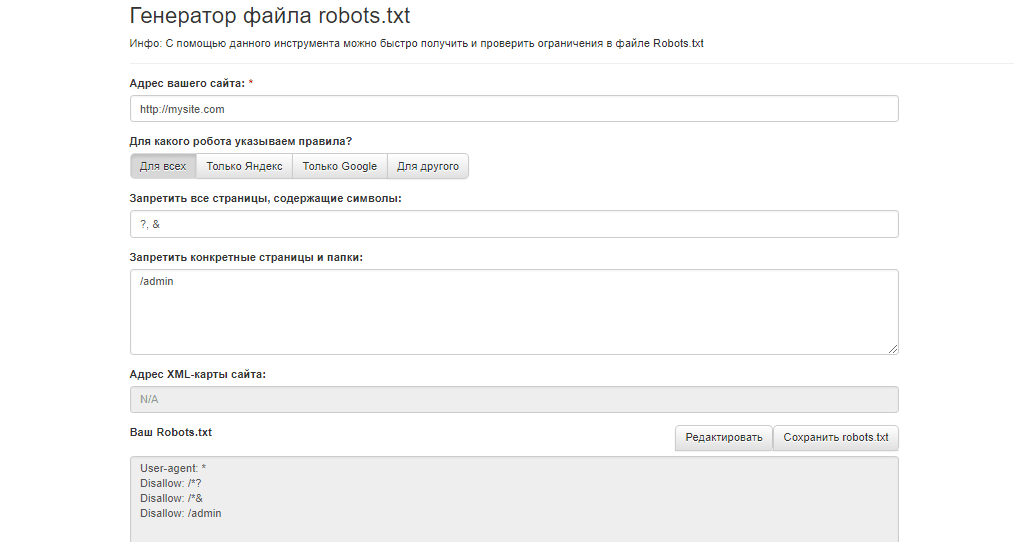
Robots.txt необходим для ограничения сканирования определенных страниц вашего сайта, которые не нужно включать в индекс, так как они носят технический характер. Для создания такого документа можно воспользоваться Блокнотом или Notepad++.
Пропишите к каким поисковым роботам вы обращаетесь и дайте им команду, как описано выше.
Далее, проверьте его правильность через встроенные инструменты Google и Яндекс. Если не возникает ошибок, сохраните файл в корневую папку и еще раз проверьте его доступность, перейдя по ссылке http://yoursiteadress.com/robots.txt. Активная ссылка говорит о том, что все сделано правильно.
Помните, что директивы носят рекомендательный характер, а для того чтобы полностью запретить индексирование страницы нужно воспользоваться другими методами.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4.71 из 5 на основе 13 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
SEO
Анатолий Бондаренко
Основные ошибки в оптимизации сайта и как их выявить
SEO
Ilkhom Chakkanbaev
Идеальная оптимизация страницы сайта: наглядное руководство [Инфографика]
SEO
Анастасия Кочеткова
Краулинговый или рендеринговый бюджет: не вместо, а вместе
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
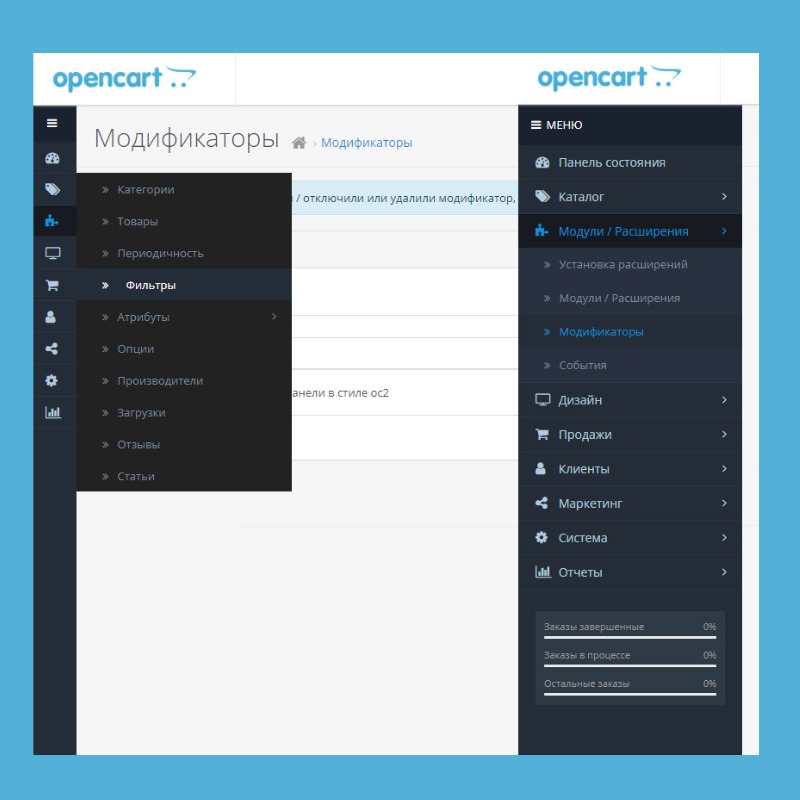
▷ Що таке файл Robots.txt — як створити та налаштувати правила в файлі Robots.txt, приклади використання
Що таке Robots.txt?
Robots.txt — текстовий файл, в якому вказуються правила сканування сайту для пошукових систем. Файл знаходиться в кореневій папці і є звичайним текстовим документом в форматі .txt.
Пошукові системи спочатку сканують вміст файлу Robots.txt і тільки потім інші сторінки сайту. Якщо файл Robots.txt відсутня – пошуковим системам дозволено сканувати всі сторінки сайту.
Содержание
- Що таке Robots.txt?
- Для чого потрібен файл Robots.txt
- Як створити текстовий файл Robots.
 txt
txt - Вимоги до файлу Robots.txt
- Обмеження документа Robots.txt
- Позначення і види директив
- У якому порядку виконуються правила
- Приклади використання файлу Robots.txt
- Найбільш поширені помилки
- Довідкові матеріали
 txt
txtДля чого потрібен файл Robots.txt
- Вказати пошуковим системам правила сканування і індексації сторінок сайту. Для кожного пошукача можна задати як різні правила, так і однакові.
- Вказати пошуковим системам посилання на xml-карту сайту, щоб роботи могли без проблем її знайти і просканувати.
Основним завданням robots.txt є управління доступу до сторінок сайту пошуковим системам і іншим роботам. На сайті може перебувати конфіденційна інформація, наприклад, особисті дані користувачів або внутрішні документи компанії. Завдяки директивам в файлі Robots.txt можна заборонити до них доступ пошуковим системам і їх не знайдуть.
Варто пам’ятати про те, що пошукові системи враховують правила в файлі Robots. txt по-різному. Для Google вміст файлу є рекомендацією по скануванню сайту, а для Яндекса – прямий директивою.
txt по-різному. Для Google вміст файлу є рекомендацією по скануванню сайту, а для Яндекса – прямий директивою.
Тобто, якщо сторінка закрита в файлі Robots.txt, вона все одно може потрапити в індекс пошукової системи Google, адже для нього це рекомендації по скануванню, а не індексації.
Щоб не допустити індексації певних сторінок сайту потрібно використовувати метатег robots або X-Robots-Tag.
Яндекс сприймає вміст файлу Robots.txt як директиви і завжди їх виконує.
Тут потрібна картинка, що Яндекс кориться вимогам, а Google ухиляється. Треба намалювати.
Як створити текстовий файл Robots.txt
- Створіть текстовий документ у форматі .txt.
- Поставте йому ім’я robots.txt.
- Вкажіть вміст файлу.
- Додайте його в кореневий каталог сайту, щоб він був доступний за адресою /robots.txt.
- Перевірте коректність файлу через інструмент Яндекса или Google.
Файл Robots.txt повинен обов’язково знаходитися за адресою robots. txt. Якщо він буде розміщений по іншому url-адресою, пошукова система буде його ігнорувати і вважати, що все дозволено для сканування і індексації.
txt. Якщо він буде розміщений по іншому url-адресою, пошукова система буде його ігнорувати і вважати, що все дозволено для сканування і індексації.
Вірно:
https://inweb.ua/robots.txt
Невірно:
https://inweb.ua/robots.txt
https://inweb.ua/ua/robots.txt
https://inweb.ua/robot.txt
Для популярних CMS є плагіни для редагування файлу Robots.txt:
- WordPress – Clearfy Pro .
- Opencart – редактор Robots.txt .
- Bitrix – є можливість редагувати через адміністративну панель за замовчуванням. Маркетинг & gt; Пошукова оптимізація & gt; Налаштування robots.txt.
За допомогою зазначених модулів можна легко змінювати директиви через адміністративну панель, без використання ftp.
Вимоги до файлу Robots.txt
Щоб пошукові системи виявили і слідували директивам необхідно дотримуватись наступних правил:
- Розмір файлу не перевищує 500кб;
- Це TXT-файл з назвою robots – robots.txt;
- Файл розміщений в кореневому каталозі сайту;
- Файл доступний для роботів – код відповіді сервера – 200. Перевірити можна за допомогою сервісу або інструментів Google Search Console і Яндекс Вебмастера.
- Якщо файл не відповідає вимогам – сайт вважається відкритим для сканування і індексації.
 Перевірити можна за допомогою сервісу або інструментів Google Search Console і Яндекс Вебмастера.
Перевірити можна за допомогою сервісу або інструментів Google Search Console і Яндекс Вебмастера.Якщо ж пошукова система, при запиті файлу /robots.txt, отримала код відповіді сервера відмінний від 200 – сканування сайту припиниться. Це може істотно погіршити швидкість сканування сайту.
Обмеження документа Robots.txt
- Не всі пошукові системи обробляють директиви у файлі Robots.txt однаково. У кожної є своя інтерпретація. При складанні правил слід на це звертати увагу.
- Кожна директива повинна починатися з нового рядка.
- У кожної пошукової системи є кілька роботів, які сканують сайти. Деякі з них інтерпретують правила robots.txt інакше.
- У файлі Robots.txt дозволяється використовувати тільки латинські літери. Якщо у вас кириличні url-адреси або домен – необхідно використовувати punycode.
Розглянемо на прикладі, як Robots.txt використовує систему кодування:
Вірно:
User-agent: *
Disallow: /корзина
Sitemap: сайт. рф/sitemap.xml
рф/sitemap.xml
Не вірно:
User-agent: *
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap:http://xn--80aswg.xn--p1ai/sitemap.xml
Позначення і види директив
Нижче розглянемо які є директиви у файлі Robots.txt
- User-agent — вказівка пошукового бота, до якого застосовуються правила. Щоб вибрати всіх роботів – вкажіть “*”. Директива є обов’язковою для використання, без вказівки User-gent не можна використовувати будь-які правила.
Наприклад:
User-agent: * # правила для всіх.
User-agent: Googlebot # правила тільки для Google.
User-agent: Yandex # правила тільки для Яндекса
. - Disallow — директива, яка забороняє сканування певних сторінок або розділів.
Наприклад:
Disallow: / order / # закриває всі сторінки, які починаються з / order /.
Disallow: / * sort-order # закриває всі сторінки, які містять фрагмент “sort-order”.
Disallow: / secretiki / # закриває всі сторінки, які починаються з / secretiki /. - Sitemap — вказівка посилання на xml-карту сайту. Якщо xml-карт сайту кілька – можна вказати їх все.
Наприклад:
Sitemap: https://inweb.ua/sitemap.xml
Sitemap: https://inweb.ua/sitemap-images.xml - Allow — дозволяє відкрити для робота сторінку або групу сторінок.
Наприклад:
Disallow: /category/
Allo: /category/phones/
Ми закриваємо всі сторінки, які починаються з / category /, але відкриваємо /category/phones/ - Clean-param — повідомляє Яндексу, що в адресі є параметри і мітки, необов’язкові при скануванні. Працює тільки з роботами в Yandex.
- Crawl-delay — з 22 лютого 2018 року не враховується. Раніше враховувалася тільки пошуковою системою Яндекс і впливала на затримку між зверненнями до сайту.
- Host — вказівка головного дзеркала для Яндекса. Не враховується з 12 березня 2018 року. Тепер все пошукові системи ігнорують цю директиву.
- Спецсимволи:* – позначає будь-яку кількість символів.
Наприклад:
Disallow: * # забороняє сканування всього сайту.
Disallow: * limit # Забороняє сканування всіх сторінок, які містять “limit”.
Disallow: / order / * / success / # забороняє сканування всіх сторінок, які починаються з / order /, потім містять будь-яку кількість символів, а потім / success /. - $ – позначає кінець рядка.
Наприклад:
Disallow: /*order$ #забороняє сканування всіх сторінок, які закінчуються на order.
У якому порядку виконуються правила
Yandex і Google обробляє директиви Allow і Disallow не по порядку, в якому вони вказані, а спочатку сортує їх від короткого правила до довгого, а потім обробляє останнім відповідне правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
Буде прочитана як:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким чином, якщо перевіряється посилання виду: /wp-content/uploads/file. jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
У разі, якщо директиви рівнозначні або суперечать один одному:
User-agent: *
Disallow: /admin
Allow: /admin
Пріоритет віддається директиві Allow.
Приклади використання файлу Robots.txt
Приклад №1 – повністю закрити сайт від індексації.
User-agent: *
Disallow: /
Приклад №2 – блокуємо доступ до папки для Google, іншим пошуковим системам відкриваємо.
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /papka/
Приклад №3 – сайт повністю відкритий для індексації.
User-agent: *
Disallow:
Приклад №4 – закриваємо всі сторінки сайту, які містять фрагмент url-адреси “secret”.
User-agent: *
Disallow: *secret
Приклад №5 – закриємо повністю сайт для Яндекса, а для Google відкриємо тільки папку /for-google/
User-agent: Yandex
Disallow: /
User-agent: Googlebot
Disallow: /
Allow: /for-google/
Найбільш поширені помилки
Розглянемо найбільш поширені помилки, які допускають SEO-фахівці при складанні директив.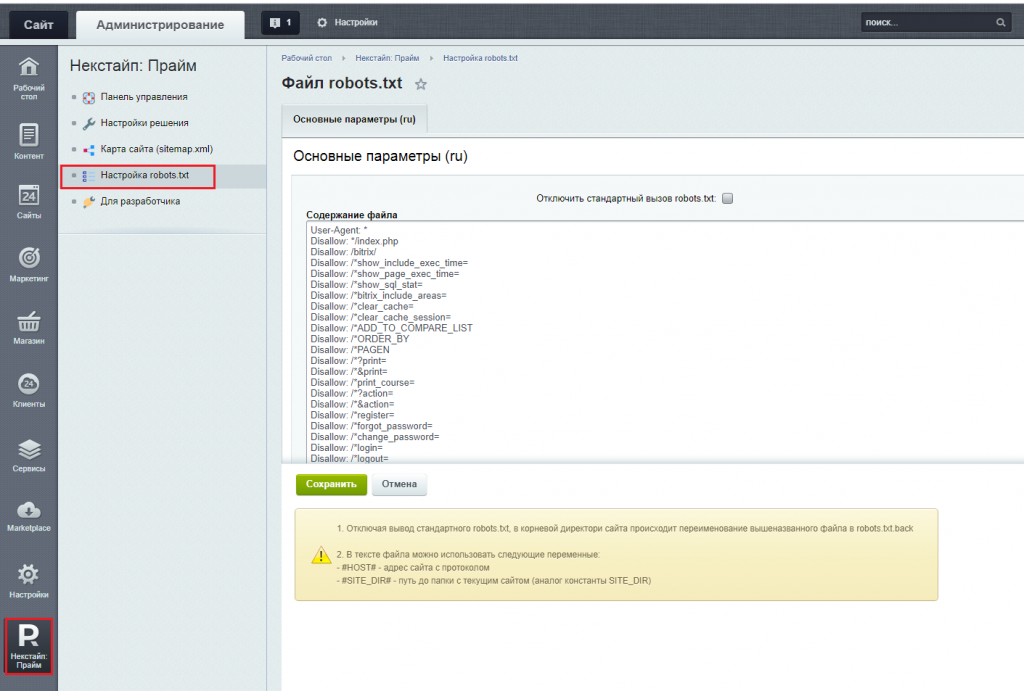
- Відсутність на самому початку директиви зірочки. Варто пам’ятати, що обов’язково потрібно додавати * перед фрагментом url-адреси, якщо директива містить фрагмент, який знаходиться не на початку url-адреси.
Наприклад, потрібно закрити від сканування url-адреса
https://inweb.ua/catalog/cateogory/?sort=name
Невірно: Disallow: ?sort=
Вірно: Disallow: /*sort= - Директива, крім неякісних url-адрес, забороняє сканування якісних сторінок. При написанні директив варто вказувати їх максимально чітко, щоб навіть теоретично якісні url-адреси не потрапили під заборону.
Невірно: Disallow: *sort
Вірно: Disallow: /*?sort=
У першому випадку, випадково можуть бути сторінки виду:
https://inweb.ua/kak-zakryt-ot-indeksacii-sortirovki/ Адже, теоретично, деякі сторінки можуть містити в url-адресу фрагмент “sort”. - Сторінки одночасно закриті в файлі Robots.txt і через метатег robots.Еслі неякісний документ закритий від сканування в файлі Robots.txt і від індексування через метатег robots – сторінка ніколи не випаде з індексу, оскільки робот пошукової системи Google не побачить noindex, адже не може її просканувати.
- Використання кириличних символів. Варто завжди пам’ятати, що кирилиця не розпізнає пошуковими системами в файлі Robots.txt, обов’язково потрібно замінити на punycode. Посилання на конвертер.

Довідкові матеріали
- Довідка Яндекс по Robots.txt.
- Довідка Google по Robots.txt.
- Види пошукових роботів Google.
- Види пошукових роботів Яндекс.
- Інструмент перевірки файлу Robots.txt.
Тест на знання файлу Robots.txt
Коли-небудь настане день і знамення олдові «Термінатора» стане реальністю – роботи заполонять світ і візьмуть верх над людством. І тільки вправні знавці машин зможуть лавірувати в смертельній сутичці. Як добре ви вмієте спілкуватися з роботами? Чи зможете очолити повстання проти машин? Давайте перевіримо!
Как запретить поисковым системам сканировать ваш веб-сайт
Чтобы ваш веб-сайт могли найти другие люди, поисковые системы поисковые роботы, также иногда называемые ботами или пауками, будут сканировать ваш веб-сайт в поисках обновленного текста и ссылки для обновления своих поисковых индексов.
Как управлять сканерами поисковых систем с помощью файла robots.txt
Владельцы веб-сайтов могут указывать поисковым системам, как им следует сканировать веб-сайт, с помощью файла robots.txt 9файл 0004.
Когда поисковая система сканирует веб-сайт, она сначала запрашивает файл robots.txt , а затем следует его правилам.
Важно знать, что правила robots.txt не должны соблюдаться ботами, и они являются ориентиром.
Например, чтобы установить задержку сканирования для Google, это необходимо сделать в инструментах Google для веб-мастеров.
Для плохих ботов, которые злоупотребляют вашим сайтом, вы должны посмотреть, как заблокировать плохих пользователей с помощью User-agent в .htaccess.
Отредактируйте или создайте файл robots.txt
Файл robots.txt должен находиться в корне вашего сайта. Если ваш домен был example.com , он должен быть найден:
На вашем сайте :
https://example.
 com/robots.txt
com/robots.txt На вашем сервере :
/home/userna5/ public_html/robots.txt
Вы также можете создать новый файл и назвать его robots.txt просто текстовым файлом, если у вас его еще нет.
User-agent поисковой системы
Наиболее распространенное правило, которое вы используете в файле robots.txt , основано на User-agent сканера поисковой системы.
Сканеры поисковых систем используют User-agent , чтобы идентифицировать себя при сканировании, вот несколько распространенных примеров:
3 лучших агента пользователя поисковой системы США :
Googlebot Яху! Slurp bingbot
Общая поисковая система Пользовательские агенты заблокированы :
AhrefsBot Байдуспайдер Эзумы MJ12bot YandexBot
Доступ поискового робота через файл robots.txt
Существует несколько вариантов управления сканированием вашего сайта с помощью файла robots. txt .
txt .
Правило User-agent: указывает, к какому User-agent применяется правило, а * — это подстановочный знак, соответствующий любому User-agent.
Запретить: устанавливает файлы или папки, которые не разрешены для сканирования.
Установить задержку сканирования для всех поисковых систем :
Если на вашем веб-сайте 1000 страниц, поисковая система потенциально может проиндексировать весь ваш сайт за несколько минут.
Однако это может привести к чрезмерному использованию системных ресурсов при загрузке всех этих страниц за короткий период времени.
A Crawl-delay: из 30 секунд позволят поисковым роботам проиндексировать весь ваш веб-сайт на 1000 страниц всего за 8,3 часа
A Задержка сканирования: из 500 секунд позволит поисковым роботам проиндексировать весь ваш 1000-страничный веб-сайт за 5,8 дней
Агент пользователя: * Crawl-delay: 30
Разрешить всем поисковым системам сканировать веб-сайт :
По умолчанию поисковые системы должны иметь возможность сканировать ваш веб-сайт, но вы также можете указать, что они разрешено с:
User-agent: * Запретить:
Запретить всем поисковым системам сканировать сайт :
Вы можете запретить любой поисковой системе сканировать ваш сайт, используя следующие правила:
User-agent:4 *
Запретить: /
Запретить одной конкретной поисковой системе сканирование веб-сайта :
Вы можете запретить сканировать ваш сайт только одной поисковой системе, используя следующие правила:
User-agent: Baiduspider Запретить: /
Запретить все поисковые системы из определенных папок :
Если бы у нас было несколько каталогов, таких как /cgi-bin/ , /private/wempt 0 и 03, 0
не хотел, чтобы боты ползали, мы могли бы использовать это:
User-agent: * Запретить: /cgi-bin/ Запретить: /частный/ Запретить: /tmp/
Запретить все поисковые системы из определенных файлов :
Если бы у нас были такие файлы, как , contactus.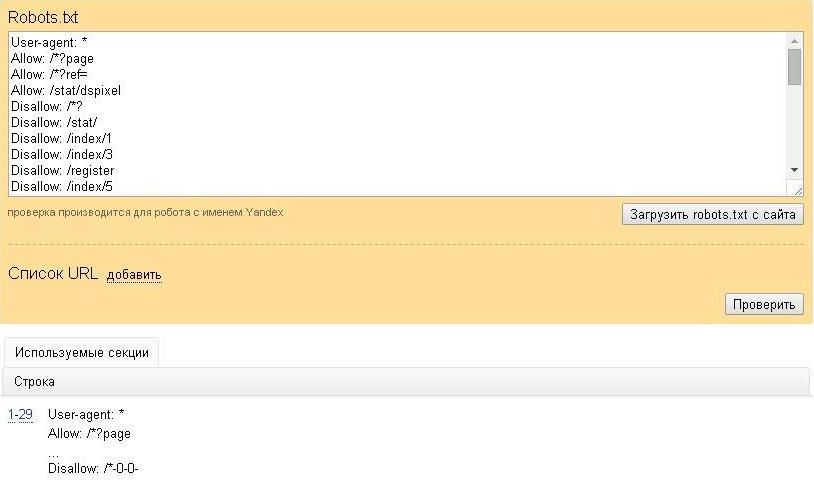 htm , index.htm
htm , index.htm
4 , и
мы не сохранили бы.tm4 и
хотите, чтобы боты сканировали, мы могли бы использовать это: User-agent: *
Запретить: /contactus.htm
Запретить: /index.htm
Disallow: /store.htm
User-agent: * Запретить: /contactus.htm Запретить: /index.htm Disallow: /store.htm
Запретить все поисковые системы, кроме одной :
Если бы мы только хотели разрешить роботу Googlebot доступ к нашему каталогу /private/ , мы могли бы использовать все остальные каталоги и запретить :
Агент пользователя: * Запретить: /частный/ Агент пользователя: Googlebot Запретить:
Когда Googlebot прочитает наш файл robots.txt , он увидит, что ему не запрещено сканировать какие-либо каталоги.
Как найти, отредактировать и скрыть страницы
Поисковые системы, такие как Google, просматривают Интернет в поисках новых данных и сканируют веб-страницы с помощью поисковых роботов или поисковых роботов, чтобы найти новый или обновленный контент.
Как владелец магазина Shopify, вы можете использовать файл robots.txt, чтобы запретить поисковым системам сканировать содержимое страницы, что может снизить SEO вашего сайта за счет кражи PageRank.
Как также указано в руководстве Google по robots.txt, файл robots.txt сообщает поисковым системам, какие страницы или файлы сканеры могут или не могут запрашивать. Однако имейте в виду, что это не гарантирует, что вы сохраните веб-страницу вне Google. Позже в этой статье мы рассмотрим, как защитить страницу Shopify от Google.
В этом посте мы объясним, где находится ваш файл Shopify robots.txt, как скрыть страницу от поисковых систем и можно ли ее редактировать. Давайте углубимся.
Ваш файл Shopify robots. txt находится в корневом каталоге основного доменного имени вашего магазина Shopify. Он будет выглядеть как доменное имя robots.txt, как в следующем примере:
txt находится в корневом каталоге основного доменного имени вашего магазина Shopify. Он будет выглядеть как доменное имя robots.txt, как в следующем примере:
examplestore.com/robots.txt
Если вы считаете, что определенная страница, файл или содержимое вашего магазина Shopify заблокированы роботами. txt, и вы хотите отредактировать его, чтобы Google и другие поисковые системы могли его проиндексировать, подумайте еще раз.
Вам НЕ нужно редактировать файл robots.txt, чтобы Google проиндексировал содержимое вашего веб-сайта.
Вы можете отправить карту сайта в Google, чтобы он знал все о содержании, файлах и обновлениях вашего веб-сайта. Карты сайта генерируются автоматически и находятся в корневом каталоге доменов вашего магазина Shopify. То есть katies-apperal.com/sitemap.xml .
Файл карты сайта Shopify содержит ссылки на все ваши продукты, страницы, сообщения в блогах, изображения продуктов и коллекции.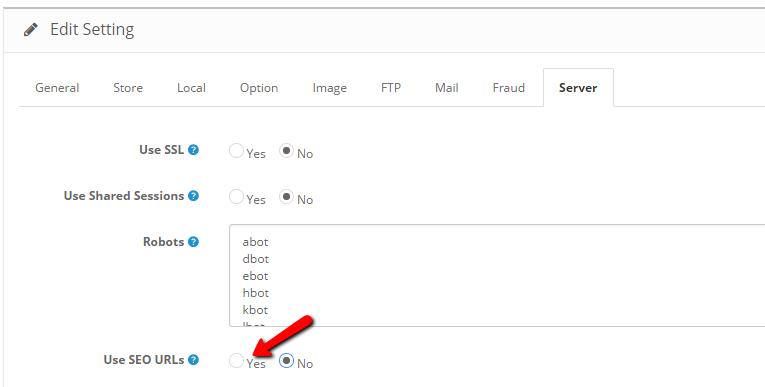 Поисковые системы используют этот файл для индексации вашего сайта, чтобы страницы вашего магазина отображались в результатах поиска.
Поисковые системы используют этот файл для индексации вашего сайта, чтобы страницы вашего магазина отображались в результатах поиска.
Для базового плана Shopify: Только основной домен вашего магазина имеет сгенерированный файл карты сайта, и его могут обнаружить поисковые системы.
Для плана Advanced Shopify или Shopify Plus: Если вы используете международные домены, файлы карты сайта создаются для всех ваших доменов.
Имейте в виду, что поисковым системам может потребоваться некоторое время, чтобы просканировать и проиндексировать ваши веб-страницы. Google не гарантирует, сколько времени займет этот процесс. Вы можете использовать консоль поиска Google, чтобы запросить индексацию каждой страницы вручную или отправить карту сайта вашего магазина.
Вот как отправить карту сайта Shopify в Search Console:
Шаг 1. Перейдите в свою учетную запись Search Console. Нажмите ≡ и выберите Добавить свойство .
Нажмите ≡ и выберите Добавить свойство .
Шаг 2. В поле Select Property Type выберите Префикс URL . Затем введите домен Shopify, который вы хотите добавить в качестве свойства. (Включите часть https:// .)
Шаг 3. Нажмите, чтобы продолжить. Выберите HTML-тег в окне Проверка владения .
Шаг 4. Выделите полный тег HTML и скопируйте его в буфер обмена.
Шаг 5. Перейдите в Shopify Admin >
3 Интернет-магазин
Шаг 6. Найдите тему, которую хотите отредактировать, и нажмите Действия , затем Редактировать код .
Шаг 7. См. раздел Макет, найдите и нажмите theme. . liquid
liquid
Шаг 8. Вставьте скопированный тег в пустую строку непосредственно под открывающим тегом .
Шаг 9. Сохраните и вернитесь в Search Console , чтобы нажать Подтвердить .
Обратите внимание, что процесс проверки не происходит немедленно. Если вы получили сообщение об ошибке, подождите 15 минут, чтобы снова нажать Подтвердить.
Если вы спрашиваете: « Могу ли я отредактировать файл Shopify Robots.txt? » ответ нет . Вы не можете редактировать файл robots.txt, если используете услугу хостинга, такую как Shopify. Shopify автоматически обрабатывает файлы robots.txt для вас, и будьте уверены, они делают это правильно.
Например, Shopify автоматически блокирует отображение страницы вашей корзины в поисковых системах. Это помогает SEO вашего магазина, поскольку позволяет легче находить страницы продуктов в результатах поиска.
Короче говоря, это делается для того, чтобы ваши страницы продуктов имели более высокий рейтинг, чем страница оформления заказа.
Хотя вы не можете редактировать файлы robots.txt Shopify, вы можете скрыть страницы, не включенные в ваш robots.txt. Это возможно, если настроить раздел файла макета вашего магазина theme.liquid.
1. Откройте страницу администратора Shopify и перейдите в Интернет-магазин > Темы .
2. Найдите тему, которую хотите отредактировать. Затем нажмите Действия > Редактировать код .
3. Нажмите theme.liquid.
4. Чтобы исключить шаблон поиска, вставьте приведенный ниже код в раздел :
{%, если шаблон содержит «поиск» %}{% endif %}
5. Если вы хотите исключить конкретную страницу, вставьте приведенный ниже код в раздел :
{%, если дескриптор содержит 'page-handle-you- хочу-исключить' %}{% endif %}
- Не забудьте заменить дескриптор страницы, который вы хотите исключить, на правильный дескриптор страницы.

6. Сохранить изменения.
Источник: Shopify
Основная цель файла robots.txt — управлять трафиком поисковых роботов на вашем сайте и часто скрывать страницу от Google, в зависимости от типа страницы.
Веб-страница: Вы можете управлять трафиком веб-страницы с помощью файлов robots.txt, но вы не можете скрыть свои веб-страницы из результатов поиска Google. Он по-прежнему может отображаться в результатах поиска.
Медиа-файл: Файл robots.txt может помочь вам управлять трафиком и предотвратить появление файлов изображений, видео и аудио в результатах поиска Google.
Файл ресурсов: Файлы robots.txt могут блокировать файлы ресурсов, такие как неважные файлы сценариев, изображений или стилей, и помогать вам управлять трафиком к этим файлам.
Как защитить страницу Shopify от Google?
Если вы хотите скрыть веб-страницу от Google, вы должны использовать директивы noindex или защитить свою страницу паролем.