Содержание
Как правильно составить файл robots.txt: инструкция
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
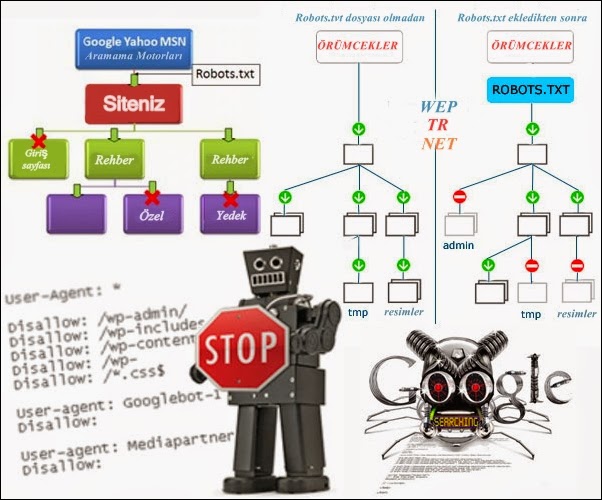
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Зачем это нужно:
- уменьшить количество запросов к серверу;
- оптимизировать краулинговый бюджет сайта — общее количество страниц, которое за один раз может посетить поисковый бот;
- уменьшить шанс того, что в выдачу попадут страницы, которые там не нужны.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию <head> HTML-кода страницы:
<meta name="robots" content="noindex, nofollow"/>
Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
- Формат — только txt.
- Вес — не превышающий 32 КБ.
- Название — строго строчными буквами «robots.txt». Никакие другие варианты, к примеру, с заглавной, боты не воспримут.
- Наполнение — строго латиница. Все записи должны быть на латинице, включая адрес сайта: если он кириллический, его нужно переконвертировать в punycode.
 Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.
Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах. - Исключение для предыдущего правила — комментарии вебмастера. Они могут быть на любом языке, поскольку специалист оставляет их для себя и коллег, а не для поисковых ботов. Для обозначения комментариев используют символ «#». Все, что указано после «#», роботы проигнорируют, поэтому следите, чтобы туда случайно не попали важные команды.
- Количество файлов robots.txt — должен быть один общий файл на весь сайт вместе с поддоменами.
- Местоположение — корневой каталог. У поддоменов файл должен быть таким же, только разместить его нужно в корневом каталоге каждого поддомена.
- Ссылка на файл — https://example.com/robots.txt (вместо https://example.com нужно указать адрес вашего сайта).
- Ссылка на robots.txt должна отдавать код ответа сервера 200 OK.
 Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.
Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
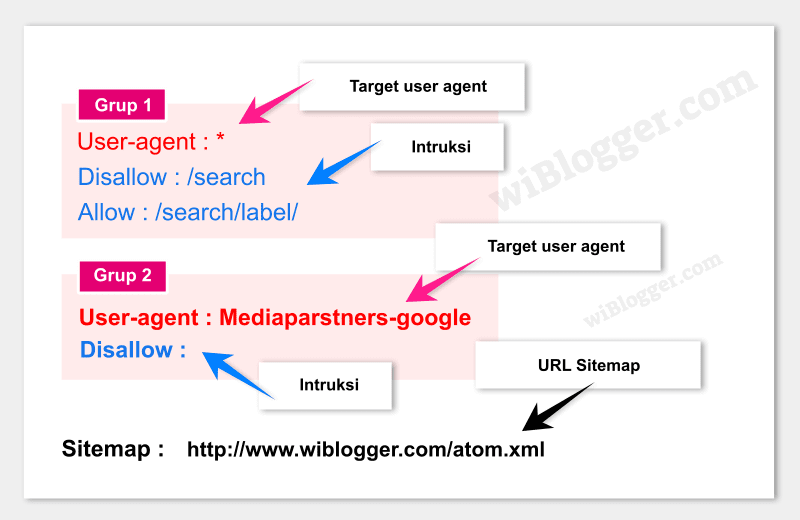
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пример:
Disallow: /blog/page-2.html
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
User-agent: *
Disallow:
А эта запись запрещает всем роботом сканировать весь сайт:
User-agent: *
Disallow: /
Если речь идет о новом сайте, проследите, чтобы в файле robots.
 txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Disallow: /catalog/blog/photo/
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Disallow: /catalog/
Disallow: /blog/
Disallow: /photo/
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
User-agent: *
Allow: /album/photo1.html
Disallow: /album/
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
https://example.com/index.php?page=1&sid=2564126ebdec301c607e5df
https://example.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index. php» индексировать не нужно:
php» индексировать не нужно:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Sitemap: https://example.com/sitemap.xml
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
Disallow: /catalog/category1$
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
- Найти ошибки в заполнении robots — инструмент от Яндекса. Укажите сайт и введите содержимое файла в поле.
- Проверить доступность для ботов — инструмент от Google. Введите ссылку на URL с вашим robots.txt.
- Определить наличие файла robots.txt в корневом каталоге и доступность сайта для индексации — Анализ сайта от PR-CY. В сервисе есть еще 70+ тестов с проверкой SEO, технических параметров, ссылок и другого.
 Укажите сайт и введите содержимое файла в поле.
Укажите сайт и введите содержимое файла в поле.Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots. txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
- Robots.txt Editor,
- Virtual Robots.txt,
- WordPress Robots.txt optimization (+XML Sitemap).
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: *&s=
Disallow: /search/
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc. php # файл API WP
php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
1C-Битрикс
В модуле «Поисковая оптимизация» этой CMS начиная с версии 14.0.0 можно настроить управление файлом robots из административной панели сайта. Нужный раздел находится в меню Маркетинг > Поисковая оптимизация > Настройка robots. txt.
txt.
Пример robots.txt для сайта на Битрикс
Похожий набор рекомендаций с дополнениями, подразумевающими, что у сайта есть личный кабинет пользователя.
User-agent: *
Disallow: /cgi-bin # закрыли папку на хостинге
Disallow: /bitrix/ # закрыли папку с системными файлами Битрикс
Disallow: *bitrix_*= # GET-запросы Битрикс
Disallow: /local/ # другая папка с системными файлами Битрикс
Disallow: /*index.php$ # дубли страниц с index.php
Disallow: /auth/ # страница авторизации
Disallow: *auth=
Disallow: /personal/ # личный кабинет
Disallow: *register= # страница регистрации
Disallow: *forgot_password= # страница с функцией восстановления пароля
Disallow: *change_password= # страница с возможностью изменить пароль
Disallow: *login= # вход с логином
Disallow: *logout= # выход из кабинета
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url=
Disallow: *back_url_admin=
Disallow: *captcha # страница с прохождением капчи
Disallow: */feed # новостные ленты
Disallow: */rss # rss-фиды
Disallow: *?FILTER*= # несколько популярных параметров фильтров в каталоге
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # все ссылки, имеющие метки UTM
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открыли папку, где находятся файлы uploads
Allow: /bitrix/*. js # здесь и далее открыли скрипты js и css
js # здесь и далее открыли скрипты js и css
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg # открыли доступ к картинкам в формате jpg и далее в других форматах
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
Sitemap: https://example.com/sitemap.xml
OpenCart
У этого движка есть официальный модуль Редактирование robots.txt Opencart для работы с файлом прямо из панели администратора.
Пример robots.txt для магазина на OpenCart
CMS OpenCart обычно используют в качестве базы для интернет-магазина, поэтому пример robots заточен под нужды e-commerce.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: *page=*
Disallow: *search=*
Disallow: /cart/
Disallow: /forgot-password/
Disallow: /login/
Disallow: /compare-products/
Disallow: /add-return/
Disallow: /vouchers/
Sitemap: https://example. com/sitemap.xml
com/sitemap.xml
Joomla
Отдельных расширений, связанных с формированием файла robots.txt для этой CMS нет, система управления автоматически генерирует файл при установке, в нем содержатся все необходимые запреты.
Пример robots.txt для сайта на Joomla
В файле закрыты плагины, шаблоны и прочие системные решения.
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
Sitemap: https://example.com/sitemap.xml
Поисковые системы воспринимают директивы в robots.txt как рекомендации, которым можно следовать или не следовать. Тем не менее, если в файле не будет противоречий, а на закрытые страницы нет входящих ссылок — у ботов не будет причин игнорировать правила. Пользуйтесь нашими инструкциями и примерами, и пусть в выдаче появляются только действительно нужные пользователям страницы вашего сайта.
Пользуйтесь нашими инструкциями и примерами, и пусть в выдаче появляются только действительно нужные пользователям страницы вашего сайта.
Как настроить и добавить robots.txt на сайт
Поисковые системы ранжируют страницы согласно заданным параметрам. Если не прописать условия ранжирования с помощью специальных инструментов, в топ выдачи попадут ненужные страницы, а нужные — останутся в тени. Чтобы этого избежать, необходимо настроить robots.txt.
Что такое файл robots.txt, для чего он нужен и за что отвечает
Robots.txt — простой, но важный файл для SEO-продвижения. Он содержит команды и инструкции по индексации сайта.
Правильный robots.txt позволит закрыть от индексации, например, технические страницы. Это нужно для того, чтобы оптимизировать сайт под поисковые системы и повысить его позиции в выдаче.
Как создать и добавить robots.txt на сайт
Если у вашего сайта нет robots.txt, то он считается полностью открытым для индексирования.
Robots. txt сайта yandex.ru
txt сайта yandex.ru
Создаем файл в блокноте или любой текстовой программе — подойдет Word, NotePad и т. д. Главное, чтобы вы сохранили файл в формате “.txt” и назвали его “robots”. В тексте нужно будет прописать страницы, которые можно и нельзя индексировать, указать нужные директивы.
Разрешили сканировать все, что начинается с “/catalog”, запретили доступ к разделам “about”, “info”, “album1”
Исключать из индексации нужно те страницы, которые не содержат полезной и релевантной для целевой аудитории информации:
- страницы авторизации и регистрации;
- результаты поиска;
- служебные разделы;
- страницы фильтров;
- PDF-документы;
- разрабатываемые страницы;
- формы заказа, корзина и т. д.
Файл загрузите в корень сайта через панель администратора.
Затем установить галочку в строке «Включить robots.txt» и внести в поле необходимые правила, нажать «Применить». Проверьте, открывается ли файл по адресу ваш_домен/robots.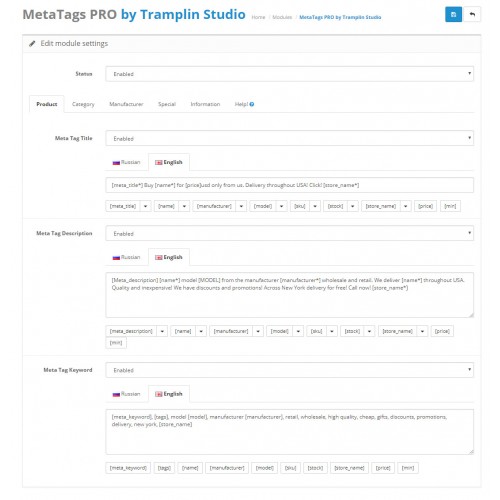 txt.
txt.
Как настроить файл robots.txt вручную
Для этого не нужно быть программистом или верстальщиком — достаточно разобраться, за что отвечает каждый параметр, который мы будем вносить в файл.
- User-agent. С этой директивы должен начинаться каждый robots.txt. Она показывает, для бота какой поисковой системы предназначается инструкция.
User-agent: YandexBot — для Яндекса,
User-agent: Googlebot — для Гугла,
User-Agent: * — общий для всех роботов.
https://vk.com/robots.txt предназначается для всех роботов поисковых систем
- Allow. Эта директива показывает, какие страницы может индексировать робот поисковых систем.
Например, в этом файле Яндексу разрешается индексировать весь сайт:
User-Agent: YandexBot
Allow: /
- Disallow. Полная противоположность предыдущей директивы — закрывает те страницы, которые запрещается индексировать.
Директивы в файле robots. txt на сайте apple.com
txt на сайте apple.com
- Sitemap. Этот параметр показывает, где находится карта сайта в формате XML, если такая у вас есть. Добавляется данная строчка в конец файла. Прописывается так:
Sitemap: http://www.вашсайт.ru/sitemap.xml
- Clean Param. Закрывает от индексации страницы с дублирующимся контентом. Это нужно для того, чтобы снизить нагрузку на сервер, — так робот поисковой системы не будет раз за разом перезагружать дублирующуюся информацию. Например, у вас есть три страницы с одинаковым содержанием, которые отличаются только параметром “get=”. Он нужен, чтобы понять, с какого сайта к вам пришел пользователь. В этом случае URL страниц разные, но все они ведут на одну и ту же страницу. Чтобы робот не индексировал всё как дубли, прописываем:
Clean-param: option /index.php
Готовые шаблоны файлов: где взять и как редактировать
Если нет желания или времени прописывать директивы вручную, можно воспользоваться сервисами для создания готовых файлов robots. txt для сайта. Однако, у этого способа есть свои плюсы и минусы.
txt для сайта. Однако, у этого способа есть свои плюсы и минусы.
Экономия времени — если у вас много сайтов, не придется для каждого вручную прописывать параметры
Директивы будут настроены однотипно, в них не учитываются особенности именно вашего сайта
Рассмотрим самые популярные сервисы:
- CY-PR. Интерфейс довольно простой — все, что требуется сделать, выбрать нужные поля и задать ваши значения. Готовый файл нужно перенести в корень сайта.
Интерфейс CY-PR
- Seo-auditor. Выбираете нужные поля и вводите ваши значения. Можно указать зеркало сайта, запретить скачивание сайта программами и адаптировать robots.txt под движок WordPress.
Интерфейс Seo-auditor
- IKSWEB. Еще один генератор с более разнообразной адаптацией настроек под CMS сайта — доступны WordPress, 1C-Bitrix, Blogger, uCoz и многие другие.
Интерфейс IKSWEB
После создания файла вы можете его редактировать под себя. Для этого достаточно открыть файл в блокноте и внести необходимые изменения в директивы. Не забудьте загрузить обновленный документ в корень сайта.
Не забудьте загрузить обновленный документ в корень сайта.
Как исправить ошибки при проверке robots.txt
В первой части статьи мы писали, как проверить корректную работу файла. Рассмотрим, как исправить ошибки, которые могут возникнуть.
Чек-лист для настройки файла robots.txt
- Файл имеет расширение “.txt” и называется “robots”.
- Файл загружен в корень сайта.
- Файл начинается с директивы User-agent и содержит не более 2 048 правил.
- Каждое правило длиной не более 1 024 символа.
- Файл содержит только одну директиву типа “User-agent: *”.
- После каждой директивы проставлено двоеточие, а затем прописан параметр.
- Файл успешно прошел проверку на сервисе, ошибок не обнаружено.
Перейти ко всем материалам блога
Как использовать WordPress robots.txt для улучшения SEO
Фейсбук
Твиттер
LinkedIn
Файл robots.txt представляет собой руководство для поисковых систем, которое поможет им правильно индексировать ваш сайт. Хотя поисковая система по-прежнему будет сканировать ваши страницы, этот файл помогает упростить процесс. Поскольку он играет роль в том, как поисковые системы получают доступ к вашему веб-сайту, полезно настроить WordPress и файл robots.txt для улучшения SEO.
Хотя поисковая система по-прежнему будет сканировать ваши страницы, этот файл помогает упростить процесс. Поскольку он играет роль в том, как поисковые системы получают доступ к вашему веб-сайту, полезно настроить WordPress и файл robots.txt для улучшения SEO.
Поисковые системы будут использовать файл robots.txt для поиска карты сайта, если он еще не указан. Например, сюда будет смотреть бот движка, если у вас нет карты сайта в инструментах консоли сайта Google или Bing. По сути, файл поможет поисковикам найти именно то, что они ищут, что сократит время индексации вашего сайта.
Этот файл также полезен для отвода поисковых систем от определенного контента. По умолчанию WordPress уже имеет статус nofollow и noindex для некоторых элементов, таких как панель администратора. Однако файл robots.txt также можно использовать для предотвращения индексации других папок и содержимого.
Сегодня я собираюсь продемонстрировать, как вы можете редактировать этот файл и заставить его работать на вас, чтобы улучшить SEO веб-сайта. Это очень простой процесс, который может сделать любой, независимо от уровня навыков.
Это очень простой процесс, который может сделать любой, независимо от уровня навыков.
Шаг 1: Создание файла robots.txt для WordPress
Некоторые плагины автоматически создают файл robots.txt при активации. Однако могут быть случаи, когда вам придется создать его вручную. В этом примере я использую FileZilla для доступа к корневой папке WordPress. Это простая в использовании программа, которая имеет большой функционал, когда дело доходит до управления веб-сайтом.
Чтобы создать файл robots.txt:
Шаг 1: Откройте FileZilla и подключитесь к корневой папке вашего веб-сайта.
ПРИМЕЧАНИЕ . Ознакомьтесь с нашим Полным руководством по использованию FileZilla, чтобы узнать больше о том, как работает программа.
Шаг 2. В правом нижнем углу окна FileZilla щелкните правой кнопкой мыши в любом месте и выберите «Создать новый файл».
Шаг 3. Появится окно с запросом имени. Введите:
robots.txt
Шаг 4: Нажмите OK, чтобы продолжить.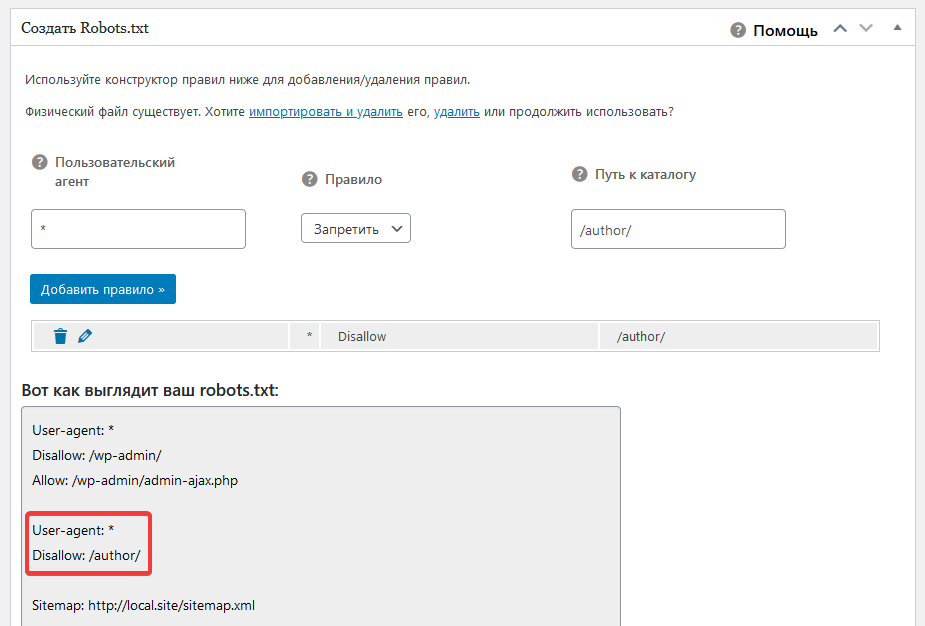 Затем FileZilla создаст файл на вашем веб-хостинге.
Затем FileZilla создаст файл на вашем веб-хостинге.
Теперь у вас есть пустой файл robots.txt, ожидающий редактирования. Поскольку FileZilla вносит эти изменения в режиме реального времени, файл сразу становится доступным. Однако ничего не произойдет, потому что он пуст.
Шаг 2: Редактирование текстового файла
После создания файла нам нужно дать ему несколько команд. В противном случае поисковые системы проигнорируют его и будут двигаться дальше. Давайте добавим несколько инструкций, чтобы боты знали, как вести себя при посещении сайта.
Чтобы отредактировать файл robots.txt:
Шаг 1: Открыв и подключив FileZilla, щелкните правой кнопкой мыши только что созданный файл robots.txt и выберите «Редактировать».
ПРИМЕЧАНИЕ : откроется программа редактирования текста. Большинство людей на компьютерах с Windows увидят Блокнот. Однако вы можете увидеть что-то другое в зависимости от того, какая у вас компьютерная система или программное обеспечение, которое вы установили.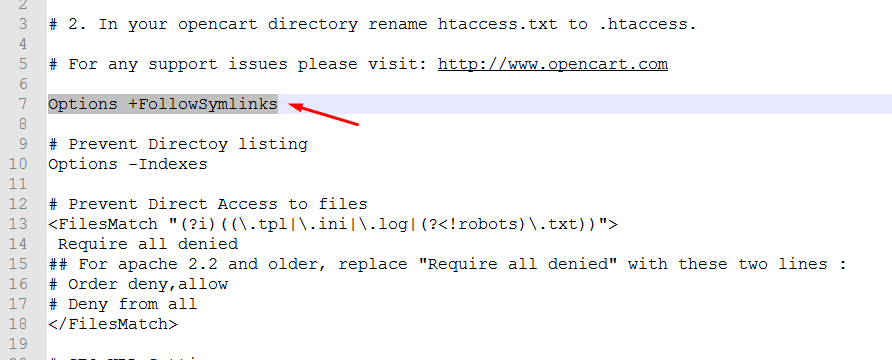 Если вы видите окно с вопросом, какую программу вы хотите использовать, выберите Блокнот или ваш любимый текстовый редактор.
Если вы видите окно с вопросом, какую программу вы хотите использовать, выберите Блокнот или ваш любимый текстовый редактор.
Шаг 2: Первая команда будет обращаться к ботам по имени. Например, Googlebot и Bingbot — это имена пользовательских агентов, которые сканируют сайт в поисках контента. Поскольку мы хотим сосредоточиться на всех поисковых системах, вместо этого мы будем использовать «*». Введите следующую строку:
User-Agent: *
Шаг 3: Нажмите Enter, чтобы перейти к следующей строке файла. Теперь мы собираемся настроить папку загрузки для сканирования поисковыми системами. Это называется «Разрешить». Поскольку папка содержит изображения и метаданные, относящиеся к оптимизации, мы хотим, чтобы она была проиндексирована. Введите следующую строку под агентом пользователя:
Разрешить: /wp-content/uploads/
Шаг 4: Нажмите Enter, чтобы перейти к следующей строке. Далее мы настроим robots.txt на «запрет» доступа к определенным файлам и местам. Это делается для того, чтобы боты не сканировали контент, который не имеет смысла для SEO. Чем меньше работы вы создадите для бота, тем лучше сайт будет показываться в результатах поиска. Итак, давайте остановим сканирование папки плагинов, введя следующую команду:
Это делается для того, чтобы боты не сканировали контент, который не имеет смысла для SEO. Чем меньше работы вы создадите для бота, тем лучше сайт будет показываться в результатах поиска. Итак, давайте остановим сканирование папки плагинов, введя следующую команду:
Disallow: /wp-content/plugins/
Шаг 5. Нажмите клавишу ВВОД, чтобы перейти к следующей строке. Давайте запретим боту индексировать определенный файл. В этом случае мы собираемся запретить доступ к файлу readme.html. Это не часть вашего веб-сайта и просто дает информацию о WordPress в целом. Чтобы запретить доступ к файлу, введите следующий текст:
Disallow: /readme.html
Шаг 6. На этот раз дважды нажмите клавишу ввода, чтобы добавить к файлу двойной пробел. Поскольку мы хотим, чтобы поисковые системы находили карту сайта для нашего веб-сайта, мы хотим сообщить им, где она находится. В этом случае вы хотите использовать весь URL-адрес самой карты сайта.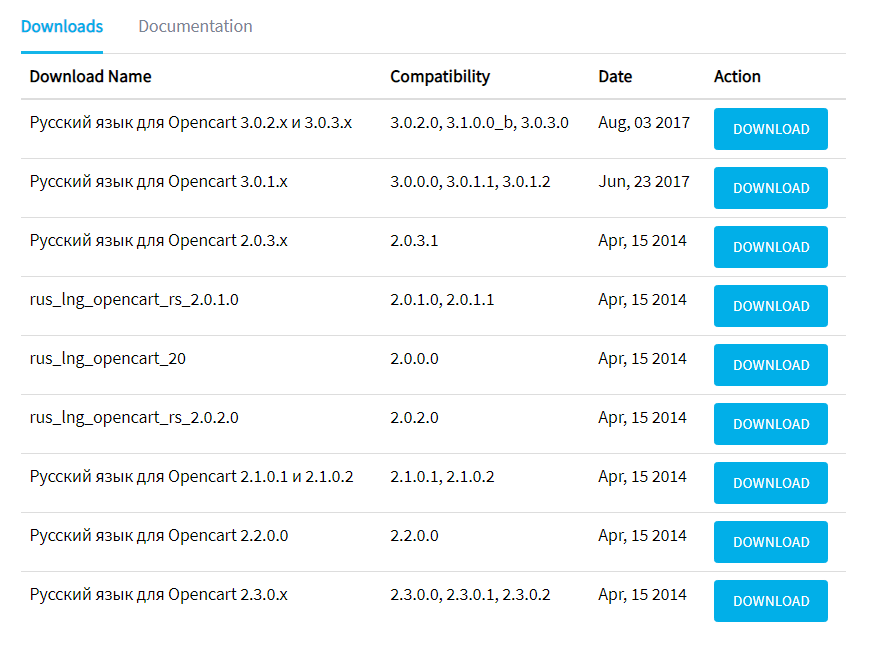 Введите следующее, но измените адрес на URL вашей карты:
Введите следующее, но измените адрес на URL вашей карты:
Карта сайта: https://www.ggexample.com/sitemap.xml
Шаг 7. Теперь у вас есть полнофункциональный файл robots.txt. Вы можете сделать это еще более сложным, разрешив или запретив определенные части веб-сайта. В целом это должно выглядеть так:
User-Agent: *
Разрешить: /wp-content/uploads/
Запретить: /wp-content/plugins/
Запретить: 900 readme.html
Карта сайта: https://www.ggexample.com/sitemap.xml
Шаг 8: Сохраните файл.
ПРИМЕЧАНИЕ : FileZilla может отображать окно с предупреждением о том, как файл был изменен. Это связано с тем, что система автоматически создаст локальный файл на вашем компьютере во время редактирования. Установите флажок «Завершить редактирование и удалить локальный файл». Нажмите кнопку «Да», чтобы зафиксировать сохранение в папке WordPress.
Поисковые роботы теперь будут иметь более четкий путь к содержимому, которое им необходимо проиндексировать. Помните, что каждый раз, когда вы можете сэкономить на боте, вы улучшаете свое отображение в результатах поиска.
Плагины SEO и их поведение
Некоторые плагины SEO вносят изменения в файл robots.txt, если он существует. Например, Yoast SEO для WordPress имеет возможность создать для вас карту сайта. Если это настроено, он автоматически добавит URL-адрес карты сайта в WordPress в файле robots.txt.
Если по какой-то причине добавить карты сайта из плагина SEO не удается, вы можете легко добавить их в файл robots.txt, чтобы улучшить функциональность SEO. Например, предположим, что ваш SEO-плагин использует карты сайта для постов и страниц по отдельности. Затем вы должны добавить их в конец текстового файла, например:
Карта сайта: https://www.ggexample.com/post-sitemap.xml
Карта сайта: https://www. ggexample.com/page-sitemap.xml
Вряд ли качественный плагин произойдет сбой при добавлении в файл robots.txt WordPress, но известно, что это происходит. Неплохо периодически проверять, особенно если вы меняете SEO-плагины или добавляете новую функцию оптимизации в WordPress.
Защита вашего сайта
Поисковые системы — не единственное, что можно отговорить от доступа к определенным материалам на сайте. Есть несколько ботов, созданных хакерами, маршрутизация которых осуществляется через файл robots.txt. Запрещая эти папки, боты, ищущие уязвимости, вообще обходят эти папки. Хотя это не является гарантией от всех угроз взлома, файл robots.txt может обеспечить уровень защиты от некоторых из них.
Получите больше от практики SEO
Из всех файлов, которые вы можете изменить в WordPress, файл robots.txt, пожалуй, один из самых простых. Кодирование простое и может быть сделано в течение пяти минут. Используйте все возможные преимущества, чтобы улучшить SEO вашего сайта. Можно с уверенностью сказать, что это ваши конкуренты.
Какие модификации файлов вы внесли на свой веб-сайт? Какие ваши любимые инструменты SEO для WordPress?
Фейсбук
Твиттер
LinkedIn
Учебники и руководства по веб-хостингу
Категории
Клиентская зона (4)
Учебники и руководства по клиентской области проведут вас по всем областям использования портала поддержки Todhost.
Учебники по CPanel (42)
Узнайте, как использовать раздел CPanel панели управления вашего веб-сайта, используя наше бесплатное учебное руководство по cPanel.
Учебники по доменам (4)
Вопросы, связанные с доменом — управление доменом, учебные пособия по переносу домена, управление DNS и связанные с ним учебные пособия
Электронная коммерция (56)
Руководства по электронной коммерции, которые помогут вам управлять наиболее популярными приложениями электронной коммерции.
Учебники по электронной почте (23)
Учебники по электронной почте — узнайте, как работать и использовать функции электронной почты в панели управления веб-сайтом
Учебники по программному обеспечению форума (16)
Программное обеспечение для форумов Учебное пособие, охватывающее все области, необходимые для эффективного управления онлайн-форумами
FTP — протокол передачи файлов (6)
Протокол передачи файлов — руководства по FTP, охватывающие основные области, необходимые для эффективной передачи и управления файлами веб-сайта с помощью приложений для передачи файлов
Учебники по хостингу (15)
Техническая поддержка более общего характера, охватывающая все аспекты, связанные с веб-хостингом и другими областями, не охваченными другими категориями.
Порталы/CMS (117)
Учебники по WordPress, Joomla, Drupal, Magento, Expression Engine, Ghost и другим основным системам управления контентом.
Предпродажные вопросы (2)
Подборка наиболее часто задаваемых вопросов и предоставленных нами ответов. Также ниже вы найдете ответы на наиболее часто задаваемые вопросы перед продажей.
Управление проектами (1)
Программное обеспечение для управления проектами Учебные пособия, охватывающие все области, необходимые для эффективного управления веб-сайтами по управлению проектами.
Социальная сеть/сообщество (16)
Учебные пособия по программному обеспечению ведущих социальных сетей/сообществ, помогающие эффективно управлять веб-сайтами социальных сетей/сообществ
SSL — защищенный уровень сокетов (4)
Руководства по SSL, охватывающие основные области, необходимые для эффективного управления установками SSL на вашем веб-сайте
Менеджер веб-хостинга (4)
Руководства по Web Host Manager, охватывающие основные темы и помогающие эффективно управлять серверами хостинга.
Дизайн веб-сайтов (10)
Общее руководство и статьи по дизайну веб-сайтов и методам управления ими
Самые популярные статьи
Обзор быстрой установки
QuickInstall — это программа автоматической установки, работающая на всех планах общего и реселлерского хостинга. Это делает…
Поисковая оптимизация Concrete5
После долгих исследований и испытаний я думаю, что у нас есть поисковая оптимизация (SEO) для…
Руководство по входу в cPanel
Это руководство представляет собой пошаговое руководство по входу в cPanel. Вы узнаете, как войти в…
Основные шаги после установки PrestaShop
После того, как вы завершили установку нашего веб-сайта Prestashop и создали свой онлайн.