Содержание
▷ Какие страницы закрыть от индексации: запрет индексации страниц
29457
| How-to | – Читать 14 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ИСПРАВЛЕНИЕ
Инструкцию одобрил
Tech Head of SEO в TRINET.Group
Рамазан Миндубаев
Контент сайта должен быть информативным и полезным для пользователя, а соответствующие страницы — открытыми для сканирования поисковым роботом. Однако есть случаи, когда нужно закрыть страницу от индексации. Разберемся в каких случаях это уместно.
Содержание:
- Причины запретить индексацию страницы
- Какие страницы не индекстровать
- Как закрыть страницы от индексации
3.1. Как закрыть сайт от индексации Google - Как проверить, сколько страниц закрыто от индексации
- Заключение
FAQ
Причины запретить индексацию страниц
Владелец сайта заинтересован, чтобы потенциальный клиент находил его веб-ресурс в выдаче, а поисковая система — в том, чтобы предоставить пользователю ценную и релевантную информацию. Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Рассмотрим причины, по которым следует запретить индексацию сайта или отдельных страниц:
Контент не несет в себе смысловой нагрузки для поисковой системы и пользователей или же вводит их в заблуждение.
К такому контенту можно отнести технические и административные страницы сайта (корзина, страница оплаты, результатов поиска, авторизация и т.д.), данные с персональной информацией, наборы фильтров каталога товара в электронной коммерции (множественный выбор фильтров по цене, цвету, фактуре и другое).
Нерациональное использование краулингового бюджета.
Краулинговый бюджет — это определенное количество страниц сайта, которое периодически сканирует поисковая система. Для всех сайтов это значение количества страниц разное и не постоянное и в том числе зависит от типа сайта и частоты его обновления.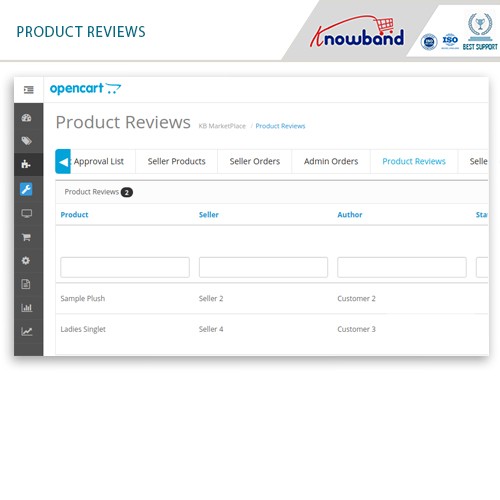 В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
Схема сканирования, индексирования и ранжирования сайта
Хотите прямо сейчас проверить, какие страницы вашего сайта индексируются и находятся в топе поисковой выдачи? А по каким фразам ранжируется ваш конкурент? Попробуйте Serpstat (нужно зарегистрироваться и после вы получите доступ к бесплатным инструментам). Если хотите доминировать на своем рынке — используйте Serpstat и достигайте большей эффективности в онлайн.
Какие закрыть страницы от индексации
Страницы сайта в процессе разработки
Если проект только в процессе создания, лучше закрыть сайт от поисковых систем. Рекомендуется открыть доступ к сканированию наполненных и оптимизированных страниц, отображение которых в результатах поиска целесообразно. При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
Закрыть сайт от индексации в robots.txt можно следующим содержимым (первая директива — означает обращение ко всем краулерам, вторая директива — запрещает сканировать все URL сайта):
User-agent: *
Disallow: /
Эти две строчки запретят доступ к сайту всем роботам поисковых систем.
Если нужно при этом разрешить сканировать конкретные URL, нужно добавить директиву Allow: /namepage$ где /namepage URL страницы разрешенной к сканированию. Директива разрешения сканирования доминирует над запретом (для конкретного URL), а значек $ отменяет применение по умолчанию не выводимывого символа «*». То есть если не поставить $ — мы разрешим сканировать вложенные URL относительно родителя, такие как /namepage/indexpage.html и т.д.
Запрет индексации для сайта на сервере NGINX осуществляется с помощью добавления кода add_header X-Robots-Tag «noindex, nofollow»; в файл .conf.
Копии сайта
Настраивая копию сайта, важно правильно указать зеркало с помощью 301 редиректов, либо атрибута rel= «canonical», чтобы сохранить рейтинг существующего ресурса и проинформировать поисковую систему: где сайт-первоисточник, а где его аналог. Закрывать от индексации работающий ресурс крайне нежелательно. Тем самым можно обнулить возраст сайта и наработанную репутацию.
Страницы печати
Страницы печати могут быть полезны посетителю. Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
По сути страница печати является копией её основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее приоритетной и более релевантной. Для правильной оптимизации сайта с большим числом страниц следует установить запрет индексации страниц для печати.
Чтобы закрыть ссылку на документ, можно использовать вывод контента с помощью AJAX, закрыть страницы с помощью метатега <meta name=»robots» content=»noindex, follow»/>, либо в роботс закрыть от индексации все страницы печати.
Ненужные документы
На сайте, кроме страниц с основным контентом, могут присутствовать документы PDF, DOC, XLS, доступные для чтения и загрузки. В результатах поиска на ряду со страницами сайта можно увидеть заголовки pdf-файлов.
Возможно, содержимое этих файлов не отвечает запросам целевой аудитории сайта. Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Пример индексации pdf-файла на сайте
Пользовательские формы и элементы
Сюда относят все страницы, которые полезны для клиентов, но не несут информационной ценности для других пользователей и, как следствие, поисковых систем. Это могут быть формы регистрации и оформления заявок, корзина, личный кабинет. Доступ к таким страницам следует ограничить.
Технические данные сайта
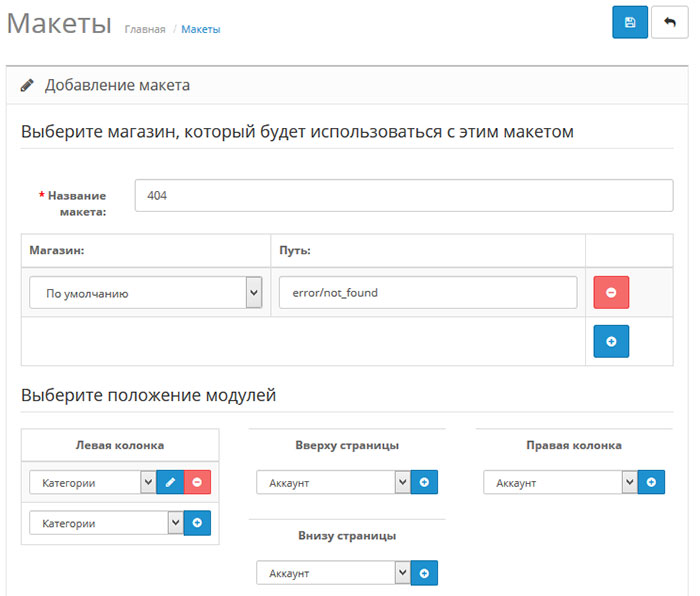
Технические страницы нужны исключительно для служебного использования администратором. Например, форма авторизации для входа в панель управления.
Форма авторизации в админку OpenCart
Персональная информация о клиентах
Эти данные могут содержать не только только имя и фамилию зарегистрированного пользователя, но и контактные и платежные данные, оставленные при оформлении заказа. Эта информация должна быть надежно защищена от просмотра.
Страницы сортировки
Особенности структуры таких страниц делают их похожими друг на друга. Чтобы снизить риск санкций от поисковых систем за дублированный контент, рекомендуем закрывать к ним доступ.
Страницы пагинации
Данные страницы хоть частично и дублируют содержание основной страницы, закрывать от индексации их не рекомендуется, для них необходимо настроить атрибут rel=»canonical», атрибуты rel=»prev» и rel=»next», указать в Google Search Console в разделе «Параметры URL», какие параметры разбивают страницы, либо целенаправленно их оптимизировать.
- Как провести анализ индексации сайта
- SEO-аудит сайта с помощью Serpstat: обзор инструмента
- Как автоматизировать поиск ошибок на сайте: Аудит сайта теперь доступен в API Serpstat
Как закрыть страницы от индексации
Метатег robots со значением noindex в html-файле
Чтобы закрыть страницу от индексации, используйте атрибут noindex в html-коде страницы — это сигнал поисковой системе о том, что ее следует исключить из результатов поиска. Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Это позволяет полностью закрыть страницу, оставив роботам возможность переходить по размещенным на странице ссылкам. Если это не нужно, замените follow на nofollow:
<meta name=»robots» content=»noindex, nofollow»/>
При использовании данных методов страница будет закрыта для сканирования даже при наличии внешних ссылок на нее.
Как закрыть сайт от индексации Google
Вы можете также закрыть доступ к сайту только ботам Google. Добавьте для этой цели данный метатег внутри <head> </head> всех страниц ресурса:
<meta name=»googlebot» content=»noindex, nofollow»/>
Через robots доступ к сайту ботам Google закрывается так:
User-agent: googlebot
Disallow: /
Еще можно запретить доступ к каким-либо статьям сайта роботам Google Новостей, тогда они не появятся в Google News:
<meta name=»Googlebot-News» content=»noindex, nofollow»>.
Файл robots.txt
В этом документе можно заблокировать доступ ко всем выбранным страницам или указать поисковикам не индексировать сайт.
Ограничить индексацию страниц через файл robots.txt можно так:
User-agent: * #название поисковой системы Disallow: /catalog/ #частичный или полный URL закрываемой страницы
Чтобы использование этого метода было эффективным, следует проверить, нет ли внешних ссылок на раздел сайта, который нужно скрыть, а также изменить все внутренние ссылки, ведущие на него.
Файл конфигурации .htaccess
Используя этот документ можно ограничить доступ к сайту с помощью пароля. Необходимо указать Username пользователей, которые смогут попасть к нужным страницам и документам, в файле паролей .htpasswd. Затем указать путь к этому файлу с помощью специального кода в файле .htaccess.
AuthType Basic AuthName "Password Protected Area" AuthUserFile путь к файлу с паролем Require valid-user
Удаление URL через сервисы веб-мастеров
В Google Search Console можно убрать страницу из результатов поиска, указав URL в специальной форме и обозначив причину ее удаления. Функция удаления страниц доступна в разделе «Индекс Google». Обработка запроса может занять некоторое время.
Функция удаления страниц доступна в разделе «Индекс Google». Обработка запроса может занять некоторое время.
Удаление URL-адресов из индекса в Search Console
Как проверить, сколько страниц закрыто от индексации
С помощью Аудита сайта Serpstat можно быстро проверить сайт на наличие технических ошибок и узнать, сколько страниц не проиндексировано.
Для того, чтобы это сделать нужно всего лишь нажать на кнопку ниже, и у вас будет возможность создать проект для сайта ↓
В появившихся настройках можно указать имя домена и количество страниц, которые нужно просканировать краулеру:
Запуск аудита в Serpstat
Выбор типа сканирования и указание лимита страниц
Когда сканирование будет закончено, на графике в Суммарном отчете можно проверить, какое количество страниц из указанных не проиндексировано:
Проверка индексации страниц в Аудите Serpstat
Хотите узнать, как с помощью Serpstat найти и исправить технические ошибки на сайте?
Оставьте заявку и наши специалисты проконсультируют вас по продвижению вашего проекта, поделятся учебными материалами и инсайтами рынка!
| Заказать бесплатную консультацию |
Error get alias
Заключение
Управление индексацией — важный этап SEO. Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Ограничение доступа к ряду страниц и документов сэкономит ресурсы поисковой системы и ускорит индексацию сайта в целом.
Как запретить индексацию сайта?
Запретить доступ ботов поисковых систем к сайту можно с помощью нескольких способов: добавления метатега robots со значением noindex в html-код; указания директивы Disallow в файле robots.txt; установки пароля для доступа к сайту в конфигурационном файле .htaccess. Также можно блокировать доступ к отдельным каталогам и документам.
Как временно закрыть сайт от индексации
Чтобы закрыть сайт от индексации, добавьте метатег name=»robots» content=»noindex, nofollow» в раздел всех веб-страниц или добавьте директиву User-agent: * Disallow: / в файл robots.txt.
Как закрыть сайт от индексации WordPress
Чтобы закрыть сайт WordPress от индексации, зайдите в админку CMS, выберите раздел «Настройки» → «Чтение». Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Задавайте вопросы в комментариях или пишите в техподдержку.:) А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4.11 из 5 на основе 45 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Как включить HTTP/2 для сайта
How-to
Анастасия Сотула
Как проверить посещаемость сайта в системах аналитики и без счетчика
How-to
Анастасия Сотула
Что такое SEO продвижение сайтов: SEO оптимизация сайта пошагово
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Какие страницы закрывать от индексации и как
Любая страница на сайте может быть открыта или закрыта для индексации поисковыми системами. Если страница открыта, поисковая система добавляет ее в свой индекс, если закрыта, то робот не заходит на нее и не учитывает в поисковой выдаче.
При создании сайта важно на программном уровне закрыть от индексации все страницы, которые по каким-либо причинам не должны видеть пользователи и поисковики.
К таким страницам можно отнести административную часть сайта (админку), страницы с различной служебной информацией (например, с личными данными зарегистрированных пользователей), страницы с многоуровневыми формами (например, сложные формы регистрации), формы обратной связи и т. д.
д.
Пример:
Профиль пользователя на форуме о поисковых системах Searchengines.
Обязательным также является закрытие от индексации страниц, содержимое которых уже используется на других страницах.Такие страницы называются дублирующими. Полные или частичные дубли сильно пессимизируют сайт, поскольку увеличивают количество неуникального контента на сайте.
Пример:
Типичный блог на CMSWordPress, который содержит дубли.http://reaktivist.ru/ — главная страница.
http://reaktivist.ru/category/liniya-zhizni — страница категории.
Как видим, контент на обеих страницах частично совпадает. Поэтому страницы категорий на WordPress-сайтах закрывают от индексации, либо выводят на них только название записей.
То же самое касается и страниц тэгов– такие страницы часто присутствуют в структуре блогов на WordPress. Облако тэгов облегчает навигацию по сайту и позволяет пользователям быстро находить интересующую информацию. Однако они являются частичными дублями других страниц, а значит – подлежат закрытию от индексации.
Однако они являются частичными дублями других страниц, а значит – подлежат закрытию от индексации.
Еще один пример – магазин на CMS OpenCart.
Страница категории товаров http://www.masternet-instrument.ru/Lampy-energosberegajuschie-c-906_910_947.html.
Страница товаров, на которые распространяется скидка http://www.masternet-instrument.ru/specials.php.
Данные страницы имеют схожее содержание, так как на них размещено много одинаковых товаров.
Особенно критично к дублированию контента на различных страницах сайта относится Google. За большое количество дублей в Google можно заработать определенные санкции вплоть до временного исключения сайта из поисковой выдачи.
Мы рекомендуем закрывать страницу от индексации, если она содержит более 40 % контента с другой страницы. В идеале структуру сайта нужно создавать таким образом, чтобы дублирования контента не было вовсе.
Примечание:
Для авторитетных сайтов с большим количеством страниц и хорошей посещаемостью (от 3000 человек в сутки) дублирование не столь существенно, как для новых сайтов.
Еще один случай, когда содержимое страниц не стоит «показывать» поисковику – страницы с неуникальным контентом. Типичный пример — инструкции к медицинским препаратам в интернет-аптеке. Контент на странице с описанием препарата http://www.piluli.ru/product271593/product_info.html неуникален и опубликован на сотнях других сайтов.
Сделать его уникальным практически невозможно, поскольку переписывание столь специфических текстов – дело неблагодарное и запрещенное. Наилучшим решением в этом случае будет закрытие страницы от индексации, либо написание письма в поисковые системы с просьбой лояльно отнестись к неуникальности контента, который сделать уникальным невозможно по тем или иным причинам.
Классическим инструментом для закрытия страниц от индексации является файл robots.txt. Он находится в корневом каталоге вашего сайта и создается специально для того, чтобы показать поисковым роботам, какие страницы им посещать нельзя. Это обычный текстовый файл, который вы в любой момент можете отредактировать. Если файла robots.txt у вас нет или если он пуст, поисковики по умолчанию будут индексировать все страницы, которые найдут.
Если файла robots.txt у вас нет или если он пуст, поисковики по умолчанию будут индексировать все страницы, которые найдут.
Структура файла robots.txt довольно проста. Он может состоять из одного или нескольких блоков (инструкций). Каждая инструкция, в свою очередь, состоит из двух строк. Первая строка называется User-agent и определяет, какой поисковик должен следовать этой инструкции. Если вы хотите запретить индексацию для всех поисковиков, первая строка должна выглядеть так:
User-agent: *
Если вы хотите запретить индексацию страницы только для одной ПС, например, для Яндекса, первая строка выглядит так:
User-agent: Yandex
Вторая строчка инструкции называется Disallow (запретить). Для запрета всех страниц сайта напишите в этой строке следующее:
Disallow: /
Чтобы разрешить индексацию всех страниц вторая строка должна иметь вид:
Disallow:
В строке Disallow вы можете указывать конкретные папки и файлы, которые нужно закрыть от индексации.
Например, для запрета индексации папки images и всего ее содержимого пишем:
User-agent: *
Disallow: /images/
Чтобы «спрятать» от поисковиков конкретные файлы, перечисляем их:
User-agent: *
Disallow: /myfile1.htm
Disallow: /myfile2.htm
Disallow: /myfile3.htm
Это – основные принципы структуры файла robots.txt. Они помогут вам закрыть от индексации отдельные страницы и папки на вашем сайте.
Еще один, менее распространенный способ запрета индексации – мета-тэг Robots. Если вы хотите закрыть от индексации страницу или запретить поисковикам индексировать ссылки, размещенные на ней, в ее HTML-коде необходимо прописать этот тэг. Его надо размещать в области HEAD, перед тэгом <title>.
Мета-тег Robots состоит из двух параметров. INDEX – параметр, отвечающий за индексацию самой страницы, а FOLLOW – параметр, разрешающий или запрещающий индексацию ссылок, расположенных на этой странице.
Для запрета индексации вместо INDEX и FOLLOW следует писать NOINDEX и NOFOLLOW соответственно.
Таким образом, если вы хотите закрыть страницу от индексации и запретить поисковикам учитывать ссылки на ней, вам надо добавить в код такую строку:
<meta name=“robots” content=“noindex,nofollow”>
Если вы не хотите скрывать страницу от индексации, но вам необходимо «спрятать» ссылки на ней, мета-тег Robots будет выглядеть так:
<metaname=“robots” content=“index,nofollow”>
Если же вам наоборот, надо скрыть страницу от ПС, но при этом учитывать ссылки, данный тэг будет иметь такой вид:
<meta name=“robots” content=“noindex,follow”>
Большинство современных CMS дают возможность закрывать некоторые страницы от индексации прямо из админ.панели сайта. Это позволяет избежать необходимости разбираться в коде и настраивать данные параметры вручную. Однако перечисленные выше способы были и остаются универсальными и самыми надежными инструментами для запрета индексации.
Подборка лучших SEO-модулей для OpenCart от веб-студии NeoSeo
Все мы, когда нам нужно найти нужную информацию, заходим на сайты поисковых систем Google или Bing, чтобы получить ответ от Всевышнего. Поисковики, конечно же, стараются чем могут помочь нам, представляя в результатах поиска наиболее релевантные (наиболее подходящие запросу) на их странице мнения. Вы, как владелец интернет-магазина на OpenCart, безусловно, будете иметь бесплатный, органический трафик в своей сфере. Отсюда вопрос: как заставить поисковую систему решать, какие страницы вашего интернет-магазина наиболее подходят покупателям для отображения в результатах поиска?
Ответ прост – нужно как минимум провести все работы, которые относятся к базовой SEO оптимизации, ну и конечно же работать в направлении создания полезного покупателям контента, улучшения на дороге, показателей ссылочной массы . Все мы знаем (за что во многом винили OpenCart), что «голый OpenCart», который можно бесплатно скачать и использовать для создания собственного интернет-магазина, создан достаточно неплохо, с точки зрения даже элементарной поисковой оптимизации. А куда же сегодня без базового SEO, когда стоимость клика по контекстной рекламе в Google Adwords или Яндекс.Директе постоянно растет, а в некоторых категориях уже достигла 10$ и выше, а конкуренция продолжает расти? Правильно, негде в этом направлении работать и лучше начать поздно, чем никогда.
А куда же сегодня без базового SEO, когда стоимость клика по контекстной рекламе в Google Adwords или Яндекс.Директе постоянно растет, а в некоторых категориях уже достигла 10$ и выше, а конкуренция продолжает расти? Правильно, негде в этом направлении работать и лучше начать поздно, чем никогда.
Для того, чтобы вы провели хотя бы элементарную, базовую SEO оптимизацию интернет-магазина на OpenCart вам понадобится подборка ТОП 10 SEO модулей от нашей веб-студии.
SEO-модули для OpenCart помогут вам значительно упростить и автоматизировать процессы, чтобы не писать код с нуля. Конечно, одних модулей недостаточно, чтобы занять лидирующие позиции в поисковой выдаче, однако они являются фундаментом, с которого нужно начинать.
Рассмотрим основные моменты базовой SEO-оптимизации и наши программные решения, которые мы сами используем для продвижения проектов наших Заказчиков (данные модули уже есть в сборках нашего SEO-Shop по умолчанию, но не только они…)
1.
 SEO-структура интернет-магазина
SEO-структура интернет-магазина
Решение: Модуль Product Filter {SEO-filter} для OpenCart — создание фильтров и лендингов.
Правильная SEO-структура сайта необходима для получения высоких позиций по средне- и низкочастотным запросам. Чтобы поисковые роботы выдавали ваш интернет-магазин по обширному, очень широкому количеству запросов вашей тематики, они должны выявить и распознать такие страницы на вашем сайте как наиболее подходящие для запросов пользователей (наиболее релевантные). Если для каждой смысловой группы товаров создать отдельный лендинг, то можно удовлетворить и поискового робота, и потребность покупателя, и тем самым обеспечить высокие продажи.
Модуль SEO-фильтра позволяет создавать любые целевые страницы. С его помощью вы можете создавать тысячи целевых страниц, комбинируя необходимые значения фильтров (по цвету, по типу, по классу, по производителю и т. д.) и значения категорий. То есть для любого возможного сочетания фильтров и категорий будет создана максимально релевантная целевая страница с удобным для человека адресом (ЧПУ URL), для которой можно будет прописать метатеги. Подробнее здесь.
Подробнее здесь.
2. Быстрое индексирование сайта
Решение: Модуль карты сайта для OpenCart — автоматическая генерация карты сайта
Для того, чтобы роботы быстро узнавали обо всех ваших новинках, вам необходимо предоставить им соответствующую информацию в рекомендованном ими формате. Именно в карте сайта мы сообщаем роботам, какую страницу и когда индексировать, как часто они должны это делать и т. д. Чтобы не доводить эту информацию до руководителя магазина, мы создали этот модуль, который все это делает автоматически. Для достижения большей скорости вывода данных разработана возможность разбивать группы товаров на 10 000 единиц.
Модуль Карта сайта для OpenCart самостоятельно формирует и выдает поисковым системам всю необходимую им информацию и вносит изменения после любых обновлений в интернет-магазине: добавление новых категорий, лендингов, карточек товаров, статей блога и т.д.
3. Правильно индексация нужных страниц
Решение: Модуль Robots. txt Generator для OpenCart — автоматическая генерация файлов с указанием «разрешенных» и «запрещенных» директив.
txt Generator для OpenCart — автоматическая генерация файлов с указанием «разрешенных» и «запрещенных» директив.
После того, как вы создали много лендингов, определили, что и когда нужно индексировать с помощью карты сайта, нужно указать, что именно нужно проиндексировать, а что полностью закрыть от поисковых роботов, чтобы роботы не потратить так называемый краулинговый бюджет вашего интернет-магазина на OpenCart. Это очень важно для интернет-магазинов с большим количеством товаров. Так, при объединении фильтров в разном порядке, но с одинаковой комбинацией могут появляться страницы с одинаковым содержанием (дубликаты страниц). Это, в свою очередь, негативно сказывается на уникальности — важной характеристике сайта.
Также ботам нужно закрывать страницы, которые не нужны пользователю (html-файлы с информацией, страницы с архивами, скрипты и прочие маловажные ресурсы). Вы можете автоматически сгенерировать файл robots.txt с помощью модуля Генератор Robots.txt, наполнив его нужными ссылками в панели администрирования сайта.
4. SEO URL, h2, мета-теги
Решение: ЧПУ и модуль генератора метаданных для OpenCart — предоставление удобочитаемых URL-адресов веб-сайтов и генерация мета-тегов по заданному шаблону с возможностью добавления забавных EMOJI.
Удобный для человека внешний вид URL-адреса положительно влияет на рейтинг сайта в результатах поиска. То есть сайты с SEO-URL чаще занимают высокие позиции в поисковой выдаче, когда URL выглядят так, что их можно прочитать в транслитерации. Это удобно для клиентов, когда на вашу ссылку указывают кроссы с других сайтов или сниппеты, пользователи поймут, что именно находится на сайте после перехода по указанному адресу.
SEO-оптимизированные метаданные облегчают поисковым системам чтение и понимание информации с вашего сайта. Если вы правильно укажете title, Title и Description для каждой страницы (а в идеале они должны быть уникальными), поисковые системы, скорее всего, проиндексируют вас быстрее и качественнее (что даст вам преимущество перед сайтами, которые об этом не позаботились). Модуль генератора ЧПУ и метаданных автоматически преобразует URL в тип ЧПУ, и, установив правильные шаблоны, генерирует все необходимые метаданные.
Модуль генератора ЧПУ и метаданных автоматически преобразует URL в тип ЧПУ, и, установив правильные шаблоны, генерирует все необходимые метаданные.
5. Оперативное обнаружение битых, 404 страниц
Решение: Модуль DeadCat Tracking для OpenCart — автоматический поиск и обнаружение несуществующих и/или 404 страниц.
Модуль отслеживания неработающих ссылок для OpenCart
Показатель отказов сайта также является довольно важным фактором для роботов поисковых систем, которые они учитывают при определении качества страницы глазами пользователя. Страницы с ошибкой 404 могут появиться, если вы удалите или переместите страницу, если вы измените URL-адрес или если пользователь допустил ошибку.
Первые два пункта можно полностью контролировать с помощью модуля Отслеживание битых ссылок. Такое программное решение генерирует файл со списком таких страниц, и вы можете легко исправить эту ситуацию. Например, создать редирект на релевантную страницу, что минимизирует количество ошибок 404 и поддерживает ссылочный вес, что также является важным фактором определения позиций вашего интернет-магазина на OpenCart в результатах поиска. Зачем терять клиентов и вес? Просто перенаправьте вовремя!
Зачем терять клиентов и вес? Просто перенаправьте вовремя!
6. Сохранение веса ссылок и трафика со старых URL
Решение: Модуль Redirect Manager для OpenCart — перенаправление запросов, весов и трафика на соответствующие страницы.
Модуль Redirect Manager для OpenCart
Среди причин, когда нужно делать редирект можно выделить:
склейка домена с www и без www;
изменение домена со старого на новый;
разрыв страницы: поисковые системы и посетители переходят на новую страницу вместо неработающей.
удалил категорию, статью или товар и появилась 404-я страница
Как видите, редирект полезен как для пользователей, так и для поисковых роботов. Также объединяет показатели страницы и позволяет не терять позиции в поисковой выдаче. Модуль менеджера перенаправления автоматизирует этот процесс. Он просто незаменим, если позиций на сайте очень много, а вручную выполнить эту работу крайне сложно.
7. Только актуальная информация на сайте, но не терять трафик с поиска по хорошо ранжируемым карточкам товаров
Решение: Модуль архивных товаров для OpenCart — присвоение статуса «в архиве» неактуальным товарам.
Архивный модуль для OpenCart
Со временем многие товары в интернет-магазине становятся неактуальными, и не знающие менеджеров и администраторов таких интернет-магазинов просто берут и удаляют их. В результате появляются несуществующие страницы с ошибкой 404, негативное влияние которых мы рассмотрели выше. Также есть негативный эффект, когда пользователи сохранили ваш товар или ссылку, а при переходе на нее получили 404-ю страницу.
Для того, чтобы сохранить клиентов и не потерять эталонный вес, вы можете воспользоваться модулем Архивные товары. Он переведет товар в категорию «в архиве», тем самым сохранив возможность для клиента перейти на сайт с результатами поиска или прямой ссылкой, хотя такой товар не будет отображаться при поиске на самом сайте. Если вы сохранили такого посетителя, то, вероятно, когда он увидит, что товара нет в наличии, он переключится на аналогичный товар или выберет интересующую его категорию, т.е. останется на сайте и таким образом, вы сохраните шансы, что пользователь совершит покупку, а не просто закроет страницу браузера.
8. Эффективный интернет-маркетинг, анализ трафика покупок
Решение: Модуль исходного заказа для OpenCart — мониторинг источников переходов клиентов перед покупкой.
Модуль исходного заказа для OpenCart
Для того, чтобы провести эффективную рекламную кампанию и понимать, какой доход вы получаете от рекламы на различных источниках (в том числе для увеличения бюджета на эффективных), необходимо четко понимать, какие инструменты продвижения дают результат. Клиенты, конечно, могут прийти из разных источников. Это может быть:
органическая доставка;
контекстная реклама;
социальные сети;
торговые площадки и агрегаторы цен;
ссылки с других ресурсов.
Для того, чтобы определить, какой способ наиболее эффективен для вас, вам необходимо установить модуль Order Source и проследить, откуда пришел клиент. В дальнейшем вы сможете усилить свое присутствие и продвижение в тех источниках, которые приносят наибольший доход.
9. Аналитика от Google
Решение: Модуль Google Analytics для OpenCart — сбор статистики для построения стратегии продвижения сайта.
Google Analytics — лучший инструмент для определения поведения пользователей и анализа расходования рекламных бюджетов, чем предыдущий модуль. С помощью этого сервиса можно формировать множество отчетов, что очень удобно для анализа и определения способов продвижения сайта.
Модуль Google Analytics позволяет легко подключить скрипт и настроить электронную коммерцию в вашем интернет-магазине. То есть вам нужно будет скопировать и вставить в соответствующее поле только идентификатор Google Analytics. Сам скрипт будет создан автоматически. Среди преимуществ программного решения:
- большая гибкость и простота использования аналитики;
- автоматическая генерация тегов ремаркетинга и настройка рекламной кампании без дополнительных усилий;
- возможность настроить электронную коммерцию и получать данные по каждой сделке, в т.
 ч. и для каждого источника трафика.
ч. и для каждого источника трафика.
 ч. и для каждого источника трафика.
ч. и для каждого источника трафика.10. Продвижение в поисковой сети Яндекс
Решение: Модуль подключения Яндекс Метрика для OpenCart — сбор статистики для построения стратегии продвижения сайта.
Модуль подключения Яндекс Метрики для OpenCart
Как и Google Analytics, Яндекс Метрика — это система, которая собирает данные о посещаемости вашего сайта и формирует их в удобном для восприятия виде.
Модуль Яндекс Метрики предоставляет аналогичный функционал, что и модуль Google Analytics, но здесь также можно увидеть поведение клиента на сайте с помощью веб-визора. Настройка и установка не занимает много времени, но дает много пищи для размышлений, в т.ч. Вы сможете понять, насколько удобно вашим покупателям пользоваться вашим интернет-магазином.
ОБЗОР. Если вас не устраивают показатели посещения вашего интернет-магазина из органической выдачи — рано или поздно вам придется заняться поисковой оптимизацией. Наша подборка must have для базового SEO — купите пакет, установите, настройте SEO-модули от NeoSeo, ссылки на инструкции есть в карточках модулей или закажите услуги под ключ у наших специалистов, мы всегда рады помочь.
Правильное предотвращение индексации вашего сайта • Yoast
Мы уже говорили это когда-то, но повторим: нас продолжает удивлять, что до сих пор есть люди, использующие только файлы robots.txt , чтобы предотвратить индексацию своего сайта в Google или Bing. В результате их сайт все равно отображается в поисковых системах. Знаете, почему это продолжает удивлять нас? Потому что robots.txt на самом деле не делает последнего, хотя и предотвращает индексацию вашего сайта. Позвольте мне объяснить, как это работает, в этом посте.
Чтобы узнать больше о robots.txt, прочитайте robots.txt: полное руководство. Или найдите рекомендации по работе с robots.txt в WordPress.
Существует разница между индексацией и включением в список Google.
Прежде чем мы продолжим объяснять, нам нужно сначала пройтись по некоторым терминам: содержимое страницы на сервер поисковика, тем самым добавляя его в свой «индекс».
Отображение сайта на страницах результатов поиска ( SERP).

Подробнее: Что такое индексация в отношении Google? »
Таким образом, в то время как наиболее распространенный процесс идет от индексации к листингу, сайт не обязательно должен быть проиндексирован , чтобы попасть в список. Если ссылка указывает на страницу, домен или что-то еще, Google переходит по этой ссылке. Если файл robots.txt в этом домене предотвращает индексирование этой страницы поисковой системой, он все равно будет показывать URL-адрес в результатах, если он сможет получить данные из других переменных, на которые, возможно, стоит обратить внимание.
В прежние времена это мог быть DMOZ или каталог Yahoo, но я могу представить, как Google использует, например, данные о вашем бизнесе в наши дни или старые данные из этих проектов. Больше сайтов резюмируют ваш сайт, правильно.
Теперь, если приведенное выше объяснение не имеет смысла, посмотрите это видео-объяснение бывшего сотрудника Google Мэтта Каттса из 2009 года:
. Если у вас есть причины запретить индексирование вашего сайта, добавьте этот запрос на нужную страницу. блокировать, как говорит Мэтт, все еще правильный путь.
Если у вас есть причины запретить индексирование вашего сайта, добавьте этот запрос на нужную страницу. блокировать, как говорит Мэтт, все еще правильный путь.
Но вам нужно сообщить Google об этом метатеге robots. Итак, если вы хотите эффективно скрыть страницы от поисковых систем, вам нужно их до индекса 9.0130 эти страницы. Хотя это может показаться противоречивым. Есть два способа сделать это.
ваше периодическое напоминание о том, что поисковые роботы, подчиняющиеся robotstxt, не увидят директиву noindex на странице, если указанная страница запрещена для сканирования.
по запросу https://t.co/i7ouMoqNT6, на который ответил @patrickstox pic.twitter.com/98NLF2twz1
— Гэри 鯨理/경리 Illyes (@methode) 25 марта 2021 г.
Запретить размещение вашей страницы добавление метатега robots
Первый способ предотвратить размещение вашей страницы – использовать метатеги robots. У нас есть исчерпывающее руководство по метатегам роботов , которое является более подробным, но в основном сводится к добавлению этого тега на вашу страницу:
У нас есть исчерпывающее руководство по метатегам роботов , которое является более подробным, но в основном сводится к добавлению этого тега на вашу страницу:
Если вы используете Yoast SEO, это очень просто! Нет необходимости добавлять код самостоятельно. Узнайте, как добавить тег noindex с помощью Yoast SEO, здесь.
Однако проблема с таким тегом заключается в том, что вы должны добавлять его на каждую страницу.
Управление метатегами robots упрощено в Yoast SEO
Чтобы упростить процесс добавления метатега robots на каждую страницу вашего сайта, поисковые системы придумали HTTP-заголовок X-Robots-Tag. Это позволяет указать заголовок HTTP с именем 9.0187 X-Robots-Tag и установите значение, аналогичное значению мета-тегов robots. Самое классное в этом то, что вы можете сделать это для всего сайта. Если ваш сайт работает на Apache и включен mod_headers (обычно это так), вы можете добавить следующую строку в файл .