Исключенные страницы: документ является неканоническим. Неканоническая страница сайта opencart
Исключенные страницы: документ является неканоническим
Очень странная произошла вещь с одним сайтом, созданном на OpenCart. Все страницы выпали из индекса Яндекса — осталось только одна — главная. Первая мысль — сайт попал под фильтр. Но это не обычный сайт, а интернет-магазин, который, кстати, приносит доход его владельцу.
Я впервые написал Платону Щукину с просьбой указать причину происшедшего.
Что же это могло произойти? Описание товаров почти все уникальные, сайт еще не продвигался и обратных ссылок пока нет.

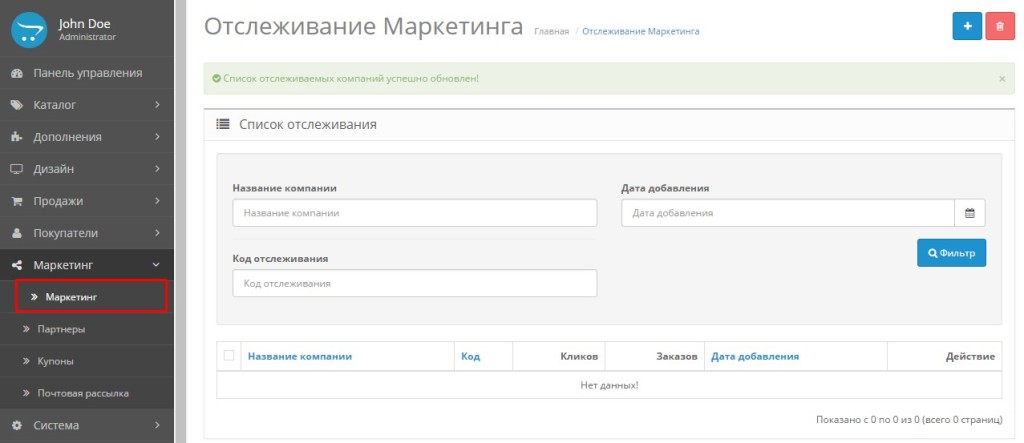
В панели Яндекс.Вебастера в разделе «Исключенные страницы» находится информация о страницах, которые не были проиндексированы роботом.
В этом разделе находится информация о страницах, которые не были проиндексированы роботом при посещении сайта. Часто индексирование страниц намеренно запрещается вебмастером – это не является ошибкой и исправления не требует. Иногда могут возникать неполадки на стороне вашего сервера или сайта, что ведет к нежелательному исключению страниц, в этом случае проблему рекомендуется устранить.
В настройках вы самостоятельно можете указать, к какой категории относится та или иная причина исключения.
Я проверил все три категории
Ресурс не найден
Там все ОК, судя по всему кто-то набирал УРЛ в адресной строке и ошибся.
Документ запрещен в файле robots.txt
Я проверил, здесь всё правильно, эти страницы индексировать не нужно.
/index.php?route=account/account |
/index.php?route=account/address |
/index.php?route=account/download |
/index.php?route=account/forgotten |
/index.php?route=account/login |
/index.php?route=account/newsletter |
/index.php?route=account/order |
/index.php?route=account/password |
/index.php?route=account/register |
/index.php?route=account/return |
/index.php?route=account/return/insert |
З/index.php?route=account/transaction |
/index.php?route=account/wishlist |
/index.php?route=affiliate/account |
/index.php?route=checkout/cart |
/index.php?route=checkout/checkout |
/index.php?route=checkout/quickcheckout |
/index.php?route=checkout/voucher |
/index.php?route=product/search |
/index.php?route=product/search&filter_tag=Product Name |
Документ является неканоническим
А вот тут уже интересно.
В коде документа в тэге содержится параметр rel=»canonical», содержащий канонический адрес страницы, по которому она индексируется роботом. Как правило, тег с атрибутом rel=»canonical» прописывают на дублирующих страницах сайта, в этом случае ничего исправлять не требуется.
Если страницы дублями не являются и должны индексироваться роботом, то вам необходимо убрать атрибут из их исходного кода. Более подробную информацию об использовании rel=»canonical» вы можете прочитать на следующей странице нашей Помощи.
Также в этом разделе могут присутствовать страницы, содержащие в коде документа мета-тег, и поэтому вместо них индексируются html-версии. Подробнее об индексировании AJAX-сайтов вы также можете прочитать в нашей Помощи.
Далее идет список УРЛ карточек продуктов (здесь их приводить не буду).
Теперь давайте размышлять вместе. Значит так. Что мы имеем? >Недоработку в OpenCart или странную реакцию Яндекса?
Смотрим что находится в коде страницы товара. Да там есть тег <link> с параметром rel=»canonical».
<link href="//site.ru/product-name" rel="canonical" />
Дело в том, что УРЛ, указанный в теге <link> совпадает с УРЛ самой страницы. Она что камикадзе? Что за суицит такой? Я понимаю, если бы УРЛ страницы, в коде которой был бы этот тег, указывающий на оригинал, тогда вопросов нет.
Теперь проверяем страницу этого поста моего блога, который работает на Вордпресс.
<link rel="canonical" href="//www.fortress-design.com/isklyuchennye-stranicy-dokument-yavlyaetsya-nekanonicheskim/" />
И что? И чем отличаются теги на этих двух страницах? Только тем, что у OpenCart rel="canonical" после ссылки, у WordPress — вначале. Но при этом мой блог отлично индексируется. Почему так? Где логика?
Значит Яндекс думает, что в Опенкарт эти карточки товара неканонические, а являются дублями оригинальных страниц. Но они как раз и являются оригиналами. Мда, наверное придется убирать из кода этот тег. Зачем мне проблемы? То что не нужно, я и сам закрою от индексации в robots.txt.
Читаем из Помощи Яндекса
Атрибут rel=»canonical» тега <link>
Если на сайте присутствуют группы схожих по контенту страниц, вебмастер может указать для каждой страницы группы предпочитаемый (канонический) адрес, который будет участвовать в поиске. Например, страница доступна по двум адресам:
<code>www.site.ru/pages?id=2 www.site.ru/blog</code>Робот считает ссылку с атрибутом rel=»canonical» не строгой директивой, а предлагаемым вариантом, который учитывается, но может быть проигнорирован.
Например, робот может не использовать указанный вами адрес, если:
- Документ по каноническому адресу недоступен для индексирования.
- В качестве канонического адреса указывается URL в другом домене или поддомене.
- Вы указали несколько канонических адресов.
fortress-design.com
Атрибут rel=canonical
Привет, друзья! Я уже писал про дубли страниц и то какой вред они могут нанести сайту. Сегодняшняя тема напрямую связана с этим явлением. Я расскажу про атрибут rel=canonical.

Атрибут rel=canonical был введен Google 12 февраля 2009 года. Он учитывается до сих пор, поисковой системой Яндекс в том числе. Атрибут rel=canonical указывает поисковым роботам какая страница является предпочтительной при индексации, если на сайте имеется несколько страниц с одинаковым содержимым, но с разными URL-адресами.
Допустим существует 2 страницы:
http://nazyrov.ru/chto-takoe-alexa-rank.htmlhttp://nazyrov.ru/chto-takoe-alexa-rank.html?id=4535
В данном случае первая страница является основной, именно для нее и должен быть прописан атрибут rel=canonical. А вторая страница является лишь ее копией, но с другим URL-адресом. Следовательно, если не будет прописан rel=canonical, то поисковая система будет индексировать как основной адрес, так и дубль страницы.
Конечно, поисковые системы не глупы и со временем выкинут дубль из индекса, но на это требуется время. А если сайт ежедневно пополняется несколькими сотнями новых страниц, то отсутствие указания канонического URL-адреса может негативно сказаться на продвижении.
Возьмем интернет магазин с 10 000 товарами. У каждого товара на сайте своя страница и несколько дублей. Представляете как подпортит продвижение сайта могут 20 000 дублированных страниц?
Откуда берутся неканонические страницы на сайте?
Неканонические страницы или дубли генерируют движки управления, такие как WordPress, phpBB и прочие. Если у вас сайт написан на чистом HTML, то дублированных страниц в принципе быть не должно, если только вы их специально не добавляли конечно.
Если мы обратимся к справочнику вебмастера в Google и Яндекс, то увидим следующее:
Сообщение Google

Рекомендации Яндекс

Указание атрибута rel=canonical не является строгой директивой. При отсутствии данного атрибута, поисковые системы попытаются определить каноническую страницу самостоятельно.
Как прописать атрибут rel=canonical?
С тех пор, как Google ввел данный атрибут, прошло много времени и практически на всех CMS и конструкторах сайтов есть возможность его прописать. В конструкторах сайтов он обычно прописывается автоматически, а для движков существуют дополнения в виде модулей и плагинов.
Если взять CMS WordPress, то практически все SEO плагины предоставляют возможность прописать канонический URL автоматически. Я пользуюсь плагином All In One Seo Pack, поэтому покажу на его примере.
В настройках плагина нужно отметить галочкой, чтобы автоматически прописывались канонические URL-адреса.

Если взглянем на исходный код страницы, то увидим что rel=canonical прописан. И если поисковый робот зайдет на этот дубль страницы, то увидит, что страница не является основной.

Вот такой вот интересный атрибут. Конечно, ничего нового я вам не открыл. Но почему-то многие не обращают внимания на вот такие мелочи, особенно владельцы небольших интернет-магазинов.
nazyrov.ru
Что такое canonical, как и зачем его настраивать
Зачем нужны canonical-адреса
Канонический URL (canonical) позволяет указать поисковой системе, какая ссылка является предпочтительной для индексации. Настройкой canonical необходимо заниматься, если у вас на сайте имеются страницы с одинаковым содержанием. Ввиду особенностей CMS сайта могут автоматически создаваться страницы с одним и тем же контентом по разным адресам URL (более подробно читайте ниже). Появление подобных страниц возможно вследствие таких причин:
- Если вы написали одно и то же сообщение в разных темах блога, то есть вероятность автоматического создания еще одной страницы сайта.
- Например, у вас есть несколько доменов: http://article.example.com и http://blogs.example.com. И вы планируете размещать информацию сразу на обоих ресурсах. В таком случае размещаемый контент будет дублированным.
- Если была обновлена структура вашего сайта, после чего URL страниц сайта могли быть изменены.
Чтобы не допустить дублирования страниц сайта в поисковой выдаче, необходимо настроить канонические URL, после чего поисковик сможет определить, какую страницу нужно индексировать. Рассмотрим причины, из-за которых важно заниматься настройкой canonical:
- Если на разных страницах вашего сайта публикуется частично или полностью идентичная информация, то следует указать, какую страницу следует считать основной.
- Одна и та же информация, размещенная на разных страницах, затрудняет получение статистики о данных страницах.
Как настроить канонические адреса
Рассмотрим способы настройки «канонических» URL:
- Следует указать, какой URL считается основным. Сделать это можно при помощи атрибута rel="canonical" тега link. Например, на сайте присутствует несколько страниц с идентичным содержимым. Для того чтобы задать URL https://example.com/buyingcar в качестве основного, указываем на страницах с дублируемым контентом в блоке head кода страницы тег вида <link rel="canonical" href="https://example.com/buyingcar" />. В данной ситуации вы задаете главный URL, который в дальнейшем будет использован для просмотра сообщения о покупке автомобилей. Также эта страница будет показываться в результатах поисковой выдачи. Предпочтительнее задавать адрес сайта в абсолютном виде (https://example.com/buyingcar), избегайте относительных путей (/buyingcar).
- В карту сайта добавляем только канонические URL, в таком случае вы сможете сообщить поисковому роботу, какие страницы сайта вы считаете основными. При индексировании сайта поисковой робот не будет заходить на неканонические страницы, тем самым быстрее индексируя сайт.
- Для различных CMS существуют различные плагины, которые позволяют настроить канонические URL, например, для WordPress можно воспользоваться Yoast SEO.

Для OpenCart настройка атрибута canonical производится средствами CMS. Необходимо зайти в настройки товара и задать параметр SEO URL.

Для настройки canonical в Joomla нужно включить в настройках CMS функцию SEF. После включения для технических страниц вида /index.php?option будет добавлен атрибут rel="canonical" (с указанием URL на страницу с настроенным ЧПУ).

Как проверить дублированный контент
Проверить, настроен canonical для страниц вашего сайта или нет, можно с помощью следующих инструментов:
1. Для проверки настройки canonical, открываем html-код страницы и проверяем наличие атрибута canonical у тега link (в блоке <head> кода страницы).

Плагин для браузеров RDS Bar позволит просмотреть эту информацию без совершения лишних действий. Включаем данную опцию в настройках плагина (Параметры – SEO – теги – Canonical), после чего при переходе на страницы, где canonical настроен, будет отображаться следующая информация:

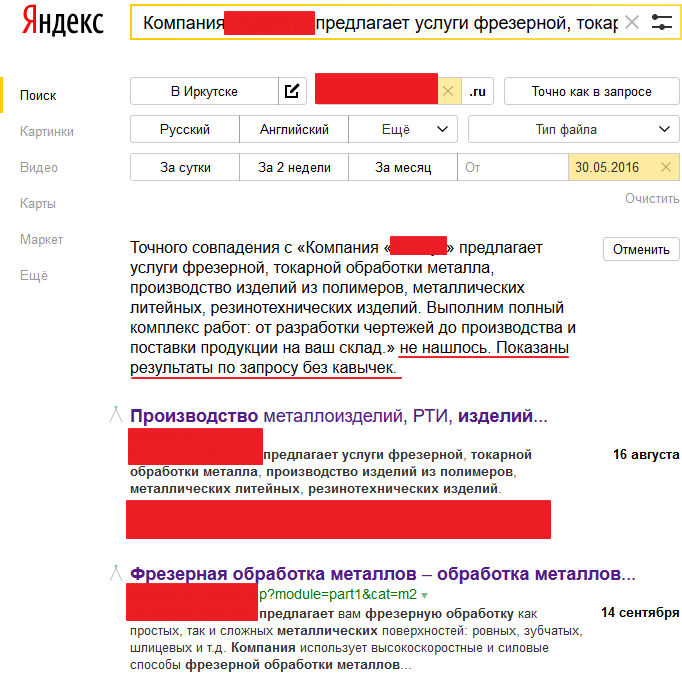
2. Проверить наличие дублируемого контента можно с помощью Расширенного поиска Яндекса. Для этого указываем адрес сайта и часть текста со страницы, контент которой будем проверять на дублирование. В результатах поиска будет указано, нашлись точные совпадения или нет. Если дублирование отсутствует, то будут предложены варианты по запросу.
Также проверить контент на наличие дублей можно с помощью операторов поиска, рассмотрим на примере Google. Для этого нужно ввести в поисковую строку site:имя_домена "запрос", в итоге аналогично поиску от Яндекса по результатам поисковой выдачи делаем вывод о наличии дублированного контента.

3. Еще один способ найти дублируемый контент – уникальность. В этом нам помогут специальные программы и сервисы, мы рассмотрим на примере сервиса text.ru. Для анализа необходимо добавить информацию со страницы вашего сайта в сервис и запустить проверку. В результате вы увидите, на каких сайтах в Интернете есть такой же текст, и на сколько процентов ваш текст совпадает с текстами других сайтов.

Итог
Грамотно настроенный canonical повышает эффективность работы и ускоряет индексирование сайта. Если у вас не получится самостоятельно это сделать, то вы можете обратиться к нашим специалистам, и мы сделаем настройку rel="canonical" для вашего сайта.
© 1PS.RU, при полном или частичном копировании материала ссылка на первоисточник обязательна.
Понравилась статья?
51 6
Сожалеем, что не оправдали ваши ожидания ((Возможно, вам понравятся другие статьи блога.
Понравилось? Поделись!1ps.ru