Содержание
как поставить машинное обучение на поток (пост #1) / Хабр
Сегодня мы начинаем публиковать серию постов о машинном обучении и его месте в Яндексе, а также инструментах, которые избавили разработчиков поисковой системы от рутинных действий и помогли сфокусироваться на главном — изобретении новых подходов к улучшению поиска. Основное внимание мы уделим применению этих средств для улучшения формулы релевантности, и более широко — для качества ранжирования.
Наша отрасль устроена так, что качеством поиска нужно заниматься постоянно. Во-первых, поисковые компании конкурируют между собой, а любое улучшение быстро приводит к изменению доли рынка каждой. Во-вторых, поисковые оптимизаторы стараются найти слабые места в алгоритмах, чтобы поднимать в результатах поиска даже те сайты, которые менее релевантны запросам людей. В-третьих, привычки пользователей меняются. Например, за последние несколько лет длина среднего поискового запроса выросла с 1,5 до 3 слов.
Качество поиска — это комплексное понятие. Оно состоит из множества взаимосвязанных элементов: ранжирования, сниппетов, полноты поисковой базы, безопасности и многих других. В этой серии статей мы рассмотрим только один аспект качества — ранжирование. Как многим уже известно, оно отвечает за порядок предоставления найденной информации пользователю.
Даже самая простая идея, которая может его улучшить, должна проделать сложный многошаговый путь от обсуждения в кругу коллег до запуска готового решения. И чем более автоматизированным (а значит быстрым и простым для разработчика) будет этот путь, тем быстрее пользователи смогут воспользоваться этим улучшением и тем чаще Яндекс сможет запускать такие нововведения.
Возможно, вы уже читали о платформе распределённых вычислений Yet Another MapReduce (YAMR), библиотеке машинного обучения Матрикснет и основном алгоритме обучения формулы ранжирования. Теперь мы решили рассказать и о фреймворке FML (friendly machine learning — «машинное обучение с человеческим лицом»). Он стал следующим шагом в автоматизации и упрощении работы наших коллег — поставил работу с машинным обучением на поток. Вместе FML и Матрикснет являются частями одного решения — технологии машинного обучения Яндекса.
Он стал следующим шагом в автоматизации и упрощении работы наших коллег — поставил работу с машинным обучением на поток. Вместе FML и Матрикснет являются частями одного решения — технологии машинного обучения Яндекса.
Рассказывать о FML достаточно сложно, а сделать это мы хотим обстоятельно. Поэтому разобьём наш рассказ на несколько постов:
- Что такое ранжирование и какие задачи оно решает. Здесь мы расскажем о проблематике ранжирования и основных сложностях, возникающих в этой области. Даже если вы никогда не занимались этой темой, этого введения будет достаточно для понимания всего последующего материала. А уже знакомые с ранжированием смогут свериться с нами в используемой терминологии.
- Подбор формулы ранжирования. Вы узнаете о том, как FML стал конвейером по подбору формул (да-да, их много!), чтобы оперативно учитывать большой объём асессорских оценок и новых факторов при минимальном участии человека. А также о созданном в Яндексе кластере на GPU-процессорах, который вполне может войти в сотню самых мощных суперкомпьютеров в мире.

Разработка новых факторов и оценка их эффективности. Как правило, публикации в сфере машинного обучения уделяют основное внимание самому процессу подбора формул, а разработку новых факторов обходят стороной. Однако сколько бы замечательной ни была технология машинного обучения, без хороших факторов ничего не получится. В Яндексе существует даже отдельная группа разработчиков, занятая исключительно их созданием. Здесь речь пойдёт о том, из чего состоит технологический цикл, в результате которого появляются новые факторы, и каким образом FML помогает оценить пользу от внедрения и себестоимость каждого из них. - Мониторинг качества уже внедрённых факторов. Интернет постоянно меняется. И вполне возможно, что факторы, которые ещё несколько лет назад очень помогли поднять качество, на сегодняшний день утратили свою ценность и впустую расходуют вычислительные ресурсы. Поэтому мы расскажем о том, как FML поддерживает постоянную эволюцию, в которой слабые факторы погибают и уступают место сильным.
Конвейер распределённых вычислений. Машинное обучение — лишь одна из задач, которые хорошо решает FML. Более широко его применяют для того, чтобы упростить работу с распределёными вычислениями на кластере в несколько тысяч серверов над большим массивом данных, меняющимся во времени. На сегодняшний день около 70% вычислений в разработке Яндекс.Поиска находится под управлением FML.
Области применения и сравнение с аналогами. FML используется в Яндексе для машинного обучения целым рядом команд и для решения далёких от поиска задач. Мы полагаем, что наша разработка может пригодиться и коллегам по отрасли, имеющим дело с задачами машинного обучения, да и просто с расчётами на больших объёмах данных. Мы обозначим круг задач, для решения которых FML может оказаться полезным и за пределами Яндекса, и сравним его с аналогами, доступными на рынке. Мы также расскажем, как применение FML в CERN может открыть дорогу Нобелевской премии.
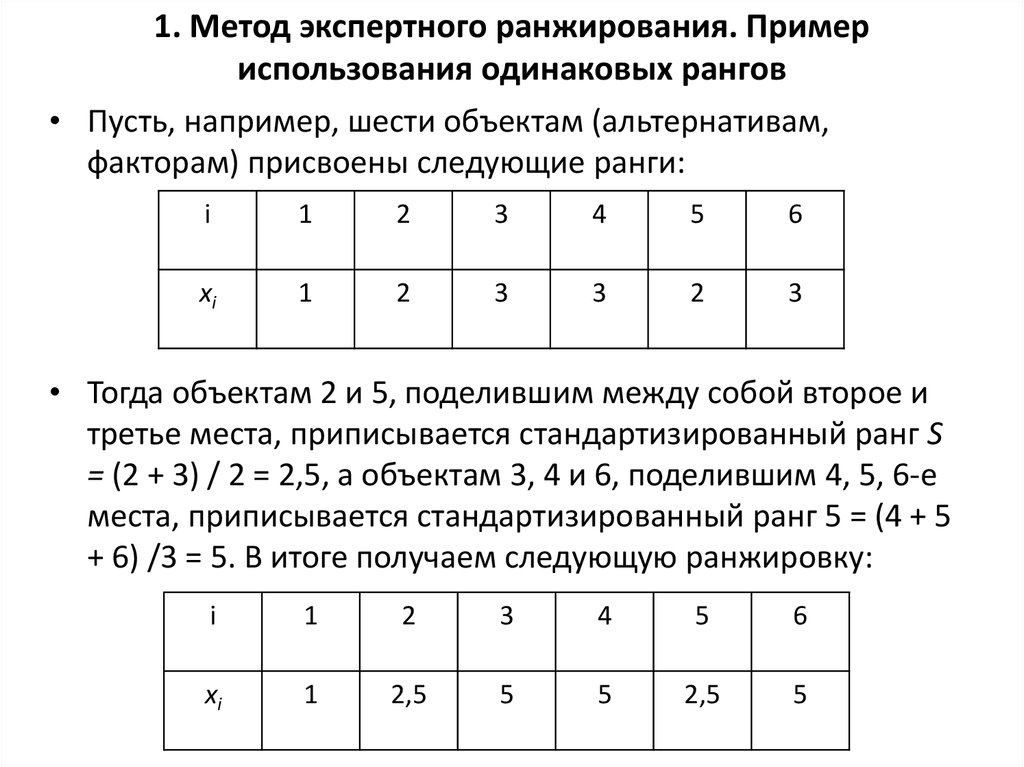
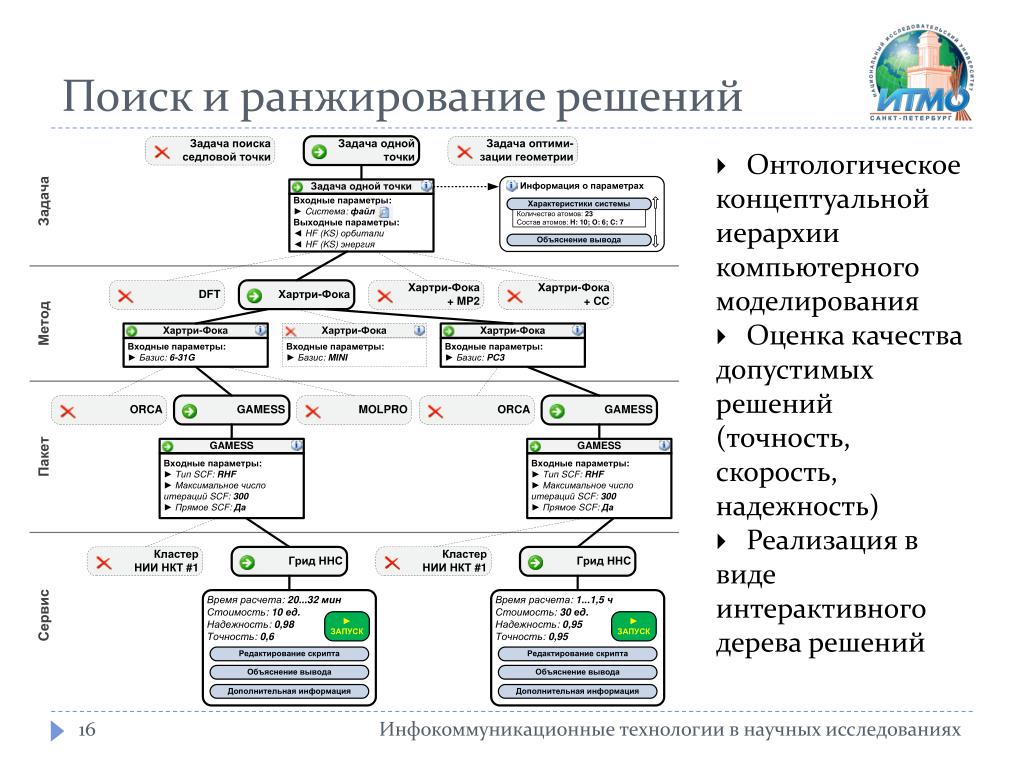
Что такое ранжирование и какую задачу оно решает
После того как поисковая система приняла запрос пользователя и нашла все подходящие страницы, она должна упорядочить их по принципу наибольшего соответствия запросу. Алгоритм, выполняющий эту работу, и называется функцией ранжирования (в СМИ её иногда называют формулой релевантности). Именно в том, чтобы выделить наиболее важные из найденных страниц и определить «правильный» порядок их выдачи, и заключается задача ранжирования. Его улучшение — первое и главное место, где используются FML и Матрикснет.
Алгоритм, выполняющий эту работу, и называется функцией ранжирования (в СМИ её иногда называют формулой релевантности). Именно в том, чтобы выделить наиболее важные из найденных страниц и определить «правильный» порядок их выдачи, и заключается задача ранжирования. Его улучшение — первое и главное место, где используются FML и Матрикснет.
Когда-то давно в Яндексе функция ранжирования выражалась одной единственной формулой, подобранной вручную. Её размер растёт экспоненциально (на графике шкала Y — логарифмическая).
Помимо того, что со временем формула грозила достичь неуправляемых размеров, появились и другие причины перехода от ручного подбора к машинному обучению. Например, в какой-то момент нам потребовалось иметь одновременно несколько формул, чтобы одинаковые запросы обрабатывались по-разному в зависимости от региона пользователя.
Формально в ранжировании, как и в любой задаче машинного обучения с учителем, нам нужно построить функцию, которая наилучшим образом соответствует экспертным данным. В ранжировании эксперты определяют порядок, в котором нужно показывать документы по конкретным запросам. Таких запросов десятки тысяч. И чем лучше, с точки зрения экспертных оценок, оказался порядок документов, сформированный формулой, тем лучшее ранжирование мы получили. Эти данные называются оценками и, как многие знают, готовятся отдельными специалистами — асессорами. Для каждого запроса они оценивают, насколько хорошо тот или иной документ отвечает на него.
В ранжировании эксперты определяют порядок, в котором нужно показывать документы по конкретным запросам. Таких запросов десятки тысяч. И чем лучше, с точки зрения экспертных оценок, оказался порядок документов, сформированный формулой, тем лучшее ранжирование мы получили. Эти данные называются оценками и, как многие знают, готовятся отдельными специалистами — асессорами. Для каждого запроса они оценивают, насколько хорошо тот или иной документ отвечает на него.
Входными данными для обучаемой функции, по которым она должна определить порядок документов для любого другого запроса, выступают так называемые факторы — различные признаки страниц. Эти признаки могут как зависеть от запроса (например, учитывать, сколько его слов содержится в тексте страницы), так и нет (например, отличать стартовую страницу сайта от внутренних). Среди факторов, используемых для обучения, есть также признаки самого запроса, которые едины для всех страниц — к примеру, на каком языке задан запрос, сколько в нём слов, насколько часто его задают пользователи.
Машинное обучение использует обучающую выборку, чтобы установить зависимость между порядком страниц для запроса, полученным исходя из их оценки людьми, и признаками этих страниц. Полученная функция используется для ранжирования по всем запросам, независимо от наличия по ним экспертных оценок.
Для построения хорошей формулы ранжирования важно не только получить оценки релевантности, но и правильным образом отобрать запросы, по которым их делать. Поэтому мы берём такое их подмножество, которое бы наилучшим образом представляло интересы пользователей.
Существует несколько технологий получения асессорских оценок, и каждая из них даёт свой вид суждений. В данный момент в Яндексе асессоры оценивают релевантность документа запросу по пятибалльной шкале. Этот метод основан на методологии Cranfield II. В других задачах мы используем и иные виды экспертных данных — например, в классификаторах могут применяться бинарные оценки.
Почему стандартные методики неприменимы в ранжировании
Однако, даже собрав достаточное число оценок и рассчитав для каждой пары (запрос + документ) набор факторов, построить ранжирующую функцию стандартными методами оптимизации не так просто.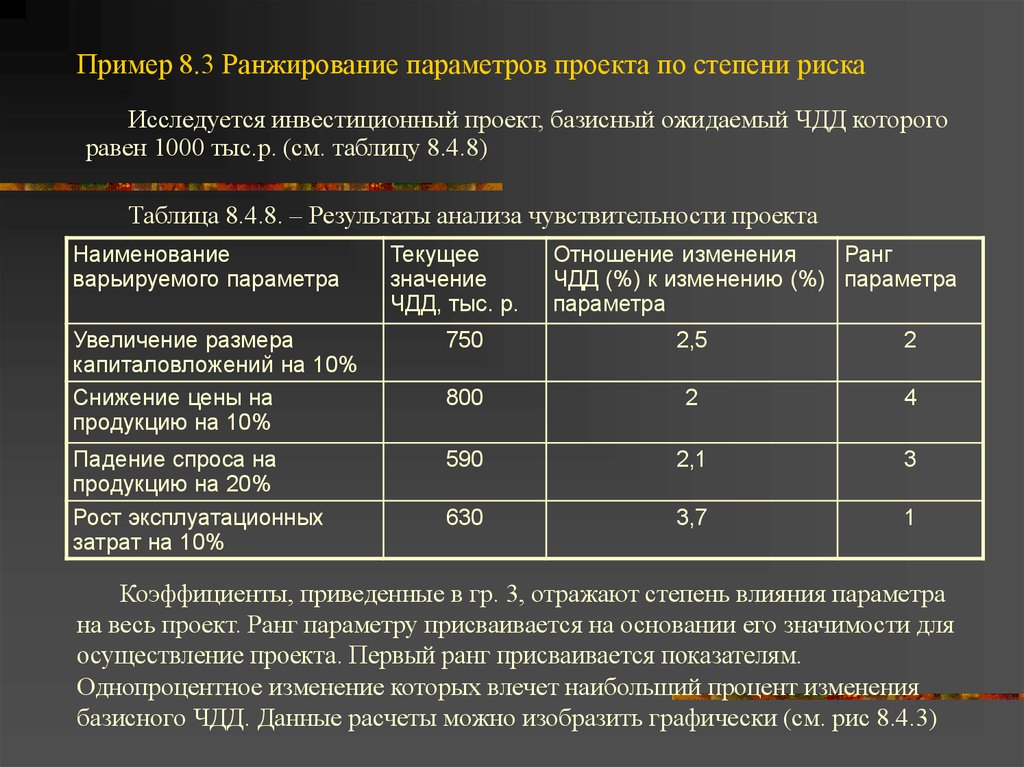 Основная сложность возникает из-за кусочно-постоянной природы целевых метрик ранжирования (nDCG, pFound и т.п.). Это свойство не позволяет использовать здесь, например, известные градиентные методы, которые требуют дифференцируемости функции, которую мы оптимизируем.
Основная сложность возникает из-за кусочно-постоянной природы целевых метрик ранжирования (nDCG, pFound и т.п.). Это свойство не позволяет использовать здесь, например, известные градиентные методы, которые требуют дифференцируемости функции, которую мы оптимизируем.
Существует отдельная научная область, посвященная метрикам ранжирования и их оптимизации — Learning to Rank (обучение ранжированию). А в Яндексе есть специальная группа, которая занимается реализацией и совершенствованием различных методов решения этого достаточно узкого, но очень важного для поиска класса оптимизационных задач.
Итак, функция ранжирования строится по набору факторов и по обучающим данным, подготовленным экспертами. Её построением и занимается машинное обучение — в случае Яндекса библиотека Матрикснет. В следующих постах мы расскажем о том, откуда берутся поисковые факторы, и как всё это связано с FML.
Яндекс — информация о компании — Ранжирование и машинное обучение
Сейчас уже сложно придумать такой запрос, по которому находится меньше десятка страниц. А по многим запросам результатов поиска — миллионы. И со временем их становится всё больше — интернет очень быстро растет. Поэтому поисковой системе уже недостаточно просто показать все страницы со словами из запроса — чтобы найти подходящий ответ, человеку придется листать десятки страниц с результатами поиска. Поисковая система должна расположить найденные страницы в нужном порядке — так, чтобы сверху оказались наиболее подходящие пользователю (наиболее релевантные). Этот процесс — упорядочивание результатов поиска в соответствии с запросом пользователя — называется ранжированием. Именно ранжирование определяет качество поиска — то есть качество ответа на вопрос, заданный в поисковой строке.
А по многим запросам результатов поиска — миллионы. И со временем их становится всё больше — интернет очень быстро растет. Поэтому поисковой системе уже недостаточно просто показать все страницы со словами из запроса — чтобы найти подходящий ответ, человеку придется листать десятки страниц с результатами поиска. Поисковая система должна расположить найденные страницы в нужном порядке — так, чтобы сверху оказались наиболее подходящие пользователю (наиболее релевантные). Этот процесс — упорядочивание результатов поиска в соответствии с запросом пользователя — называется ранжированием. Именно ранжирование определяет качество поиска — то есть качество ответа на вопрос, заданный в поисковой строке.
Каждый день Яндекс отвечает на десятки миллионов запросов. Около четверти из них — неповторяющиеся. Поэтому невозможно написать для поисковой системы такую программу, в которой предусмотрен каждый запрос и для каждого запроса известен лучший ответ. Поисковая система должна уметь принимать решения самостоятельно, то есть сама выбирать из миллионов документов тот, который лучше всего отвечает пользователю. Для этого нужно научить ее обучаться.
Для этого нужно научить ее обучаться.
Задача научить машину обучаться существует не только в поисковых технологиях. Без машинного обучения невозможно, например, распознавать рукописный текст или речь. Термин «машинное обучение» появился еще в 50-х годах. Этот термин обозначает попытку научить компьютер решать задачи, которые легко даются человеку, но формализовать путь их решения сложно. В результате машинного обучения компьютер может демонстрировать поведение, которое в него не было явно заложено.
Поисковая система должна научиться строить правило, которое определяет для каждого запроса, какая страница является хорошим ответом на него, а какая — нет. Для этого поисковая машина анализирует свойства веб-страниц и поисковых запросов. У всех страниц есть какие-то признаки. Некоторые из них — статические — связаны с самой страницей: например, количество ссылок на эту страницу в интернете. Некоторые признаки — динамические — связаны одновременно с запросом и страницей: например, присутствие в тексте страницы слов запроса, их количество и расположение.
У поискового запроса тоже есть свойства, например, геозависимость — это означает, что для хорошего ответа на этот запрос нужно учитывать регион, из которого он был задан. Свойства запроса и страницы, которые важны для ранжирования и которые можно измерить числами, называются факторами ранжирования. Для точного поиска важно учитывать очень много разных факторов.
Кроме факторов ранжирования поисковой системе необходимы образцы — запросы и страницы, которые люди считают подходящими ответами на эти запросы. Оценкой того, насколько та или иная страница подходит для ответа на тот или иной запрос, занимаются специалисты — асессоры. Они берут поисковые запросы и документы, которые поиск находит по этим запросам, и оценивают, насколько хорошо найденный документ отвечает на заданный запрос. Из запросов и хороших ответов составляется обучающая выборка. Она должна содержать самые разные запросы, причём в тех же пропорциях, в которых их задают пользователи. На обучающей выборке поисковая система устанавливает зависимость между страницами, которые асессоры посчитали релевантными запросам, и свойствами этих страниц. После этого она может подобрать оптимальную формулу ранжирования — которая показывает релевантные запросу сайты среди первых результатов поиска.
После этого она может подобрать оптимальную формулу ранжирования — которая показывает релевантные запросу сайты среди первых результатов поиска.
На примере это выглядит так. Допустим, мы хотим научить машину выбирать самые вкусные яблоки. Асессоры в этом случае получают ящик яблок, пробуют их все и раскладывают на две кучи, вкусные — в одну, невкусные — в другую. Из разных яблок составляется обучающая выборка. Машина пробовать яблоки не может, но она может проанализировать их свойства. Например, какого они размера, какого цвета, сколько сахара содержат, твердые или мягкие, с листиком или без. На обучающей выборке машина учится выбирать самые вкусные яблоки — с оптимальным сочетанием размера, цвета, кислоты и твердости. При этом могут возникать какие-то ошибки. Например, поскольку машина ничего не знает про червяков, среди выбранных яблок могут оказаться червивые. Чтобы ошибок было меньше, нужно учитывать больше признаков яблок.
В поисковых технологиях машинное обучение применяется с начала 2000-х годов. Разные поисковые системы используют разные модели. Одна из проблем, которые возникают при машинном обучении — переобучение. Переобучившаяся машина похожа на студента, который перезанимался — например, прочитал очень много книжек перед экзаменом по психологии. Он мало общается с живыми людьми и пытается объяснить простые поступки слишком сложными моделями поведения. И из-за этого поведение друзей для него всегда неожиданно.
Разные поисковые системы используют разные модели. Одна из проблем, которые возникают при машинном обучении — переобучение. Переобучившаяся машина похожа на студента, который перезанимался — например, прочитал очень много книжек перед экзаменом по психологии. Он мало общается с живыми людьми и пытается объяснить простые поступки слишком сложными моделями поведения. И из-за этого поведение друзей для него всегда неожиданно.
Как это выглядит: когда компьютер оперирует большим количеством факторов (в нашем случае это — признаки страниц и запросов), а размер обучающей выборки (оценок асессоров) не очень велик, компьютер начинает искать и находить несуществующие закономерности. Например, среди всех оцененных страниц могут оказаться две с какой-то сложной комбинацией факторов, например, с размером 2 кб, фоном фиолетового цвета и текстом, который начинается на букву «я». И обе эти страницы окажутся релевантными запросу [яблоко]. Компьютер начнет считать эту случайную комбинацию факторов важным признаком релевантности запросу [яблоко].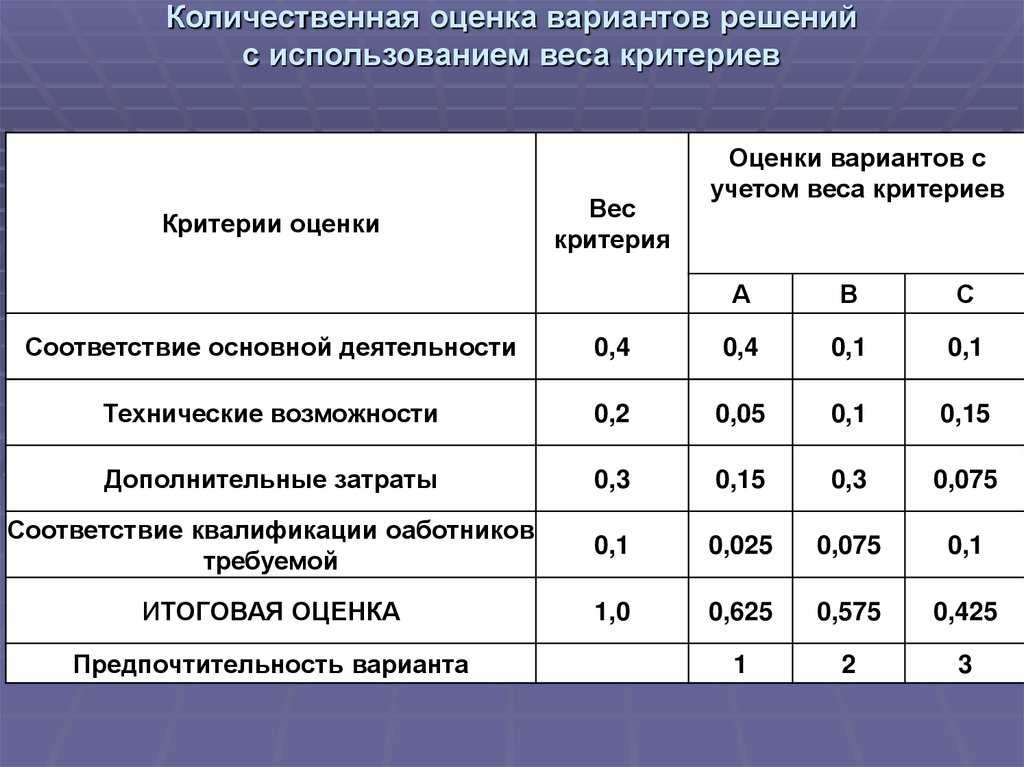 При этом все важные документы про яблоки, которые такой комбинацией факторов не обладают, покажутся ему менее релевантными.
При этом все важные документы про яблоки, которые такой комбинацией факторов не обладают, покажутся ему менее релевантными.
Для построения формулы ранжирования Яндекс использует собственный метод машинного обучения — Матрикснет. Он устойчив к переобучению.
Обучение ранжированию: полное руководство по ранжированию с использованием машинного обучения | by Francesco Casalegno
Photo by Nick Fewings on Unsplash
В этом посте под « ранжирование » мы подразумеваем сортировку документов по релевантности для поиска интересующего содержимого по запросу . Это фундаментальная проблема информационного поиска , но эта задача также возникает во многих других приложениях:
- Поисковые системы — Учитывая профиль пользователя (местоположение, возраст, пол, …) текстовый запрос, сортировка сети страницы результатов по релевантности.
- Рекомендательные системы — Учитывая профиль пользователя и историю покупок, отсортируйте другие элементы, чтобы найти новые потенциально интересные продукты для пользователя.
- Туристические агентства — Учитывая профиль пользователя и фильтры (даты заезда/выезда, количество и возраст путешественников, …), отсортируйте доступные номера по релевантности.
Ранжирование приложений: 1) поисковые системы; 2) рекомендательные системы; 3) туристические агентства. (Изображение автора)
Модели ранжирования обычно работают, предсказывая relevance score s = f ( x ) for each input x = ( q, d ) where q is a query and d это документ . Как только у нас будет релевантность каждого документа, мы можем отсортировать (т.е. ранжировать) документы в соответствии с этими оценками.
Модели ранжирования основаны на функции подсчета очков. (Изображение автора)
Модель скоринга может быть реализована с использованием различных подходов.
- Модели векторного пространства — Вычислить векторное вложение (например, с помощью Tf-Idf или BERT) для каждого запроса и документа, а затем вычислить показатель релевантности , d ) как косинусное сходство векторов вложений q и d .
- Learning to Rank — Модель подсчета очков — это модель машинного обучения, которая учится предсказывать результат с при вводе x = ( q, d ) во время фазы обучения, когда минимизируется некоторая потеря ранжирования.
В этой статье мы сосредоточимся на последнем подходе и покажем, как реализовать модели машинного обучения для обучения до ранга .
Прежде чем анализировать различные модели машинного обучения для обучения ранжированию, нам нужно определить, какие показатели используются для оценки моделей ранжирования. Эти метрики рассчитываются для предсказанных документов с рейтингом 9.0004 , т. е. k--й документ с наибольшим числом извлечений — это k -й документ с наивысшим прогнозируемым результатом s .
Эти метрики рассчитываются для предсказанных документов с рейтингом 9.0004 , т. е. k--й документ с наибольшим числом извлечений — это k -й документ с наивысшим прогнозируемым результатом s .
Средняя средняя точность (MAP)
MAP — Средняя средняя точность. (Изображение автора)
Средняя средняя точность используется для задач с бинарной релевантностью , т. е. когда истинная оценка y документа d может быть только 0 ( нерелевантная ) или 1 ( релевантная ) .
Для заданного запроса q и соответствующих документов D = { d ₁, …, dₙ }, мы проверяем, сколько из k = найденных0 документов являются релевантными0 (1 1) или нет ( y= 0)., чтобы вычислить точность P ₖ и вспомнить R ₖ . Для k = 1… n мы получаем разные значения P ₖ и R ₖ , которые определяют кривая точности-отзыва : площадь под этой кривой представляет собой среднюю точность (AP) .
Для k = 1… n мы получаем разные значения P ₖ и R ₖ , которые определяют кривая точности-отзыва : площадь под этой кривой представляет собой среднюю точность (AP) .
Наконец, путем вычисления среднего значения AP для набора из m запросов мы получаем Mean Average Precision (MAP) .
Дисконтированная совокупная прибыль (DCG)
DCG — Дисконтированная совокупная прибыль. (Изображение автора)
Дисконтированный кумулятивный выигрыш используется для задач с градуированной релевантностью , т.е. когда истинная оценка y документа d — дискретное значение на шкале, измеряющее релевантность по отношению к запрос q . Типичная шкала: 0 ( плохо ), 1 ( удовлетворительно ), 2 ( хорошо ), 3 ( отлично ), 4 ( отлично ) .
Для заданного запроса q и соответствующих документов D = { d ₁, …, dₙ } мы рассматриваем k -й верхний найденный документ.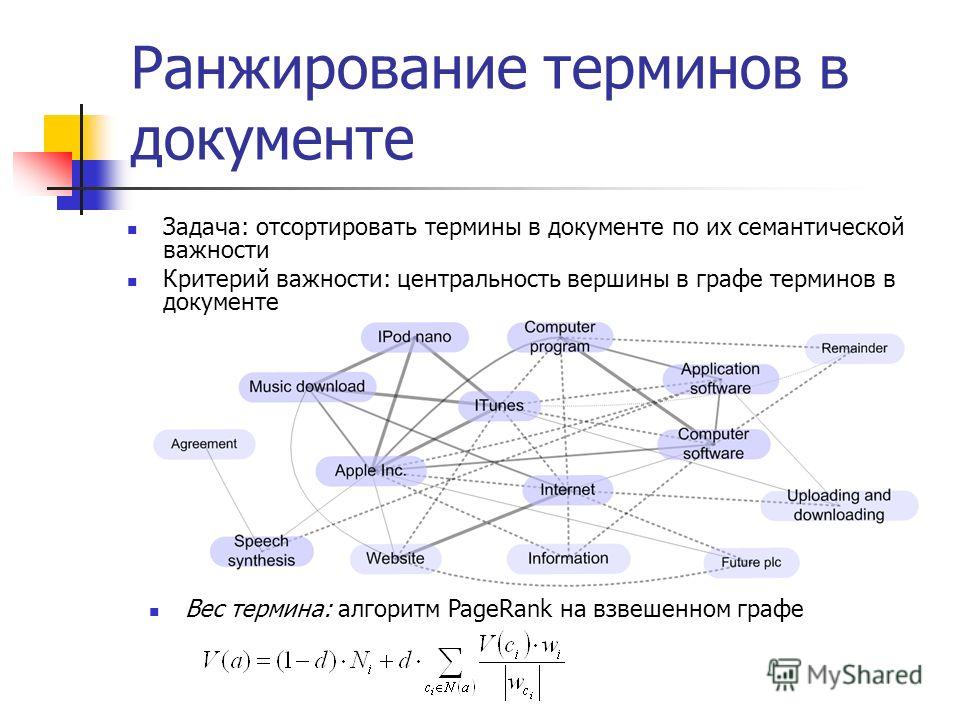 Прирост G ₖ = 9 yₖ – 1 измеряет, насколько полезен этот документ (нам нужны документы с высокой релевантностью!), в то время как скидка D ₖ = 1/log( k +1) наказывает документы, полученные с более низким рангом (хотим соответствующие документы в первых рядах!).
Прирост G ₖ = 9 yₖ – 1 измеряет, насколько полезен этот документ (нам нужны документы с высокой релевантностью!), в то время как скидка D ₖ = 1/log( k +1) наказывает документы, полученные с более низким рангом (хотим соответствующие документы в первых рядах!).
Сумма дисконтированной прибыли терминов G ₖ D ₖ for k = 1… n – дисконтированная совокупная прибыль (DCG) . Чтобы убедиться, что этот показатель находится между 0 и 1, мы можем разделить измеренный DCG на идеальный показатель IDCG, полученный, если мы ранжировали документы по истинному значению 9.0030 гₖ . Это дает нам нормализованную дисконтированную совокупную прибыль (NDCG) , где NDCG = DCG/IDCG.
Наконец, что касается MAP, мы обычно вычисляем среднее значение значений DCG или NDCG для набора из m запросов, чтобы получить среднее значение.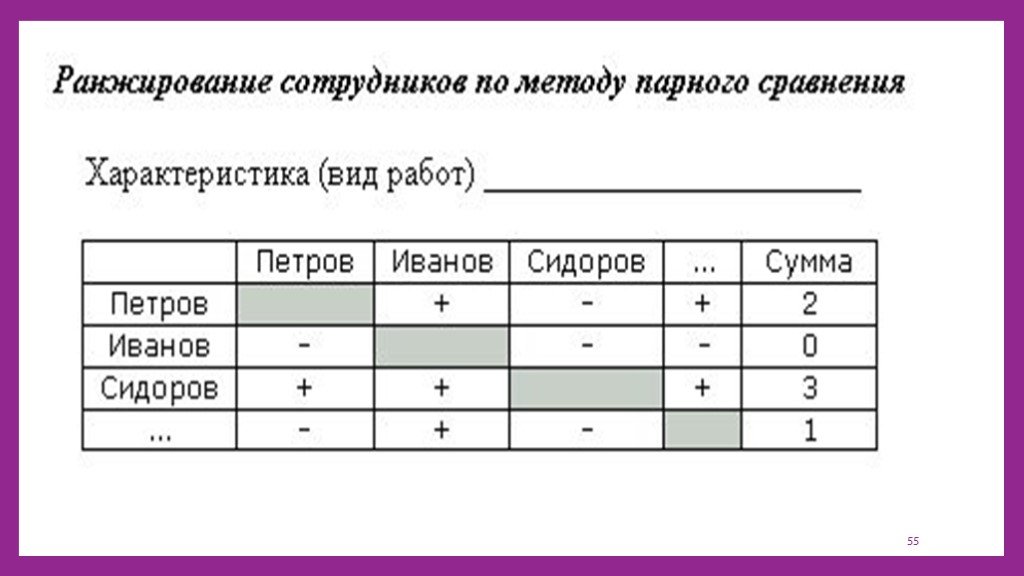
Чтобы построить модель машинного обучения для ранжирования, нам нужно определить входных данных , выходных данных и функцию потерь .
- Ввод – Для запроса q имеем n документы D = { d ₁, …, d 0 ранжироваться по 4. 0 0 релевантность 4. 0 Элементы xᵢ = ( q , dᵢ ) являются входными данными для нашей модели.
- Выход . Для ввода запроса-документа x ᵢ = ( q , dᵢ ) мы предполагаем, что существует истинный показатель релевантности yᵢ . Наша модель выводит прогнозируемый результат sᵢ = f ( xᵢ ) .
Все модели Learning to Rank используют базовую модель машинного обучения (например, дерево решений или нейронную сеть) для вычисления s = f ( x ). Выбор функции потерь является отличительным элементом моделей Learning to Rank. В общем, у нас есть 3 подхода к , в зависимости от того, как вычисляется убыток.
Выбор функции потерь является отличительным элементом моделей Learning to Rank. В общем, у нас есть 3 подхода к , в зависимости от того, как вычисляется убыток.
- Точечные методы — Общий убыток рассчитывается как сумма условий убытка, определенных по каждому документу dᵢ (отсюда поточечно ) как расстояние между прогнозируемым счетом sᵢ 9030 и реальным значением , для i= 1… n . Делая это, мы преобразуем нашу задачу в задачу регрессии , , где мы обучаем модель прогнозировать лет.
- Попарные методы – Общий убыток рассчитывается как сумма условий убытка, определенных на каждая пара документов dᵢ, dⱼ (отсюда попарно ), для i, j= 1… n . Цель, на которой обучается модель, состоит в том, чтобы предсказать, будет ли yᵢ > yⱼ или нет, то есть какой из двух документов более релевантен. Делая это, мы преобразуем нашу задачу в задачу бинарной классификации .
- Методы списка – Потери вычисляются непосредственно по всему списку документов (отсюда по списку ) с соответствующими предсказанными рангами. Таким образом, показатели ранжирования могут быть более непосредственно включены в потери.
.jpg) Делая это, мы преобразуем нашу задачу в задачу бинарной классификации .
Делая это, мы преобразуем нашу задачу в задачу бинарной классификации .Подходы машинного обучения к обучению ранжированию: точечный, парный, списочный. (Изображение автора)
Точечные методы
Точечный подход проще всего реализовать, и он был первым, предложенным для задач обучения ранжированию. Потери непосредственно измеряют расстояние между истинной оценкой земли yᵢ и предсказанное sᵢ , поэтому мы рассматриваем эту задачу, эффективно решая проблему регрессии. Например, Ранжирование подмножества использует потерю среднеквадратичной ошибки (MSE).
Потеря MSE для точечных методов, как в ранжировании подмножества. (Изображение автора)
(Изображение автора)
Парные методы
Основная проблема с точечными моделями заключается в том, что для обучения модели необходимы истинные оценки релевантности. Но во многих сценариях обучающие данные доступны только с частичной информацией , напр. мы знаем только, какой документ в списке документов был выбран пользователем (и, следовательно, более релевантен ), но мы не знаем точно, насколько релевантен любой из этих документов!
По этой причине парные методы не работают с абсолютной релевантностью. Вместо этого они работают с относительным предпочтением : учитывая два документа, мы хотим предсказать, является ли первый более релевантным, чем второй. Таким образом, мы решаем задачу бинарной классификации , где нам нужна только основная истина yᵢⱼ ( = 1, если yᵢ > yⱼ , 0 в противном случае), и мы сопоставляем выходные данные модели с вероятностями, используя логистическую функцию: sᵢⱼ = σ( sᵢ – sⱼ 90). Этот подход был впервые использован RankNet , в котором использовалась потеря двоичной перекрестной энтропии (BCE). Потеря
Этот подход был впервые использован RankNet , в котором использовалась потеря двоичной перекрестной энтропии (BCE). Потеря
BCE для парных методов, как в RankNet. (Изображение автора)
RankNet — это улучшение поточечных методов, но всем документам при обучении по-прежнему придается одинаковое значение, в то время как мы хотели бы дать большая важность для документов более высокого ранга (как метрика DCG с условиями скидки).
К сожалению, информация о ранге доступна только после сортировки, а сортировка не дифференцируема. Однако для запуска оптимизации градиентного спуска нам не нужна функция потерь, нам нужен только ее градиент! LambdaRank определяет градиенты неявной функции потерь, чтобы документы с высоким рангом имели гораздо большие градиенты:
Градиенты неявной функции потерь, как в LambdaRank. (Изображение автора)
Наличие градиентов также достаточно для построения модели Gradient Boosting. Это идея, которую использовали LambdaMART , что дало даже лучшие результаты, чем с LambdaRank.
Списочные методы
Точечные и парные подходы превращают задачу ранжирования в суррогатную задачу регрессии или классификации. Списковые методы, напротив, решают проблему more напрямую, максимизируя оценочную метрику .
Интуитивно этот подход должен дать наилучшие результаты , так как информация о ранжировании используется полностью, а NDCG напрямую оптимизируется. Но очевидная проблема с установкой Loss = 1 – NDCG заключается в том, что информация о ранге, необходимая для расчета скидок Dₖ, доступна только после сортировки документов на основе предсказанных оценок, а сортировка не является дифференцируемой . Как мы можем решить эту проблему?
Первый подход заключается в использовании итеративного метода, где 9Метрики ранжирования 0003 используются для повторного взвешивания экземпляров на каждой итерации. Это подход, используемый LambdaRank и LambdaMART , которые действительно находятся между парным и списковым подходом.
Это подход, используемый LambdaRank и LambdaMART , которые действительно находятся между парным и списковым подходом.
Второй подход заключается в аппроксимации цели, чтобы сделать ее дифференцируемой, что является идеей SoftRank . Вместо того, чтобы предсказывать детерминистическую оценку s = f ( x ), мы предсказываем сглаженная вероятностная оценка с~ 𝒩( f ( x ), σ ²). рангов k являются прерывистыми функциями предсказанных оценок s , но благодаря сглаживанию мы можем вычислить распределения вероятностей для рангов каждого документа. Наконец, мы оптимизируем SoftNDCG , ожидаемый NDCG по этому ранговому распределению, которое является гладкой функцией.
Неопределенность в оценках приводит к плавной потере SoftRank. (Изображение автора)
(Изображение автора)
Третий подход предполагает, что каждый ранжированный список соответствует перестановке, и определяет потерю пространства перестановок . В ListNet по списку оценок s мы определяем вероятность любой перестановки, используя модель Плакетта-Люса . Тогда наши потери легко вычислить как бинарное кросс-энтропийное расстояние между истинным и предсказанным распределениями вероятностей в пространстве перестановок.
Вероятность различных перестановок с использованием модели Плакетта-Люса в ListNet. (Изображение автора)
Наконец, документ LambdaLoss представил новый взгляд на эту проблему и создал обобщенную структуру для определения новых списочных функций потерь и достижения современной точности . Основная идея состоит в том, чтобы сформулировать проблему в строгой и общей форме, как модель смеси , где ранжированный список π рассматривается как скрытая переменная. Затем потеря определяется как отрицательная логарифмическая вероятность такой модели.
Затем потеря определяется как отрицательная логарифмическая вероятность такой модели.
Функция потерь LambdaLoss. (Изображение автора)
Авторы фреймворка LambdaLoss доказали два важных результата.
- Все остальные списковые методы (RankNet, LambdaRank, SoftRank, ListNet, …) являются специальными конфигурациями этой общей структуры. В самом деле, их потери получаются путем точного выбора правдоподобия p ( y | s, π ) и распределения ранжированного списка p ( π | s ) .
- Эта структура позволяет нам определять функции потерь на основе метрик, напрямую связанные с метриками ранжирования, которые мы хотим оптимизировать. Это позволяет значительно улучшить состояние дел в задачах Learningt to Rank.
Проблемы с ранжированием встречаются везде, от поиска информации до рекомендательных систем и бронирования поездок. Показатели оценки, такие как MAP и NDCG, учитывают как ранг, так и релевантность извлеченных документов, и поэтому их трудно оптимизировать напрямую.
Методы обучения ранжированию используют модели машинного обучения для прогнозирования оценки релевантности документа и делятся на 3 класса: точечные, парные и списочные. В большинстве задач ранжирования списочные методы, такие как LambdaRank и обобщенная структура LambdaLoss, достигают уровня техники.
- Страница Википедии «Учимся ранжировать»
- Li, Hang. «Краткое введение в обучение ранжированию». 2011
- Л. Те-Ян. «Учимся ранжировать для поиска информации», 2009 г.
- Л. Ти-Ян «Обучение ранжированию», 2009 г.
- X. Ван, «Структура LambdaLoss для оптимизации показателей ранжирования», 2018 г.
- З. Цао, «Обучение ранжированию: от парного подхода к списочному подходу», 2007
- M Taylor, «SoftRank: оптимизация показателей негладкого ранжирования», 2008
Азбука обучения ранжированию
Поиск нужной вещи при совершении покупок может быть утомительным. Вы можете часами просеивать похожие результаты только для того, чтобы сдаться в отчаянии. Может поэтому 79процент людей, которым не нравится то, что они находят, покидают корабль и ищут другой сайт.
Должен быть лучший способ обслуживать клиентов с улучшенным поиском.
И есть. Обучение ранжированию — это метод машинного обучения, который помогает вам предоставлять результаты, которые не только релевантны, но и… подождите… ранжированы по этой релевантности.
Поисковые системы используют обучение для ранжирования почти два десятилетия, поэтому вам может быть интересно, почему вы ничего об этом не слышали.
Как и во многих предыдущих процессах машинного обучения, нам требовалось больше данных, и мы использовали лишь несколько функций для ранжирования, включая частоту терминов, обратную частоту документов и длину документа.
79 процентов людей, которым не нравится то, что они находят, уходят с корабля и ищут другой сайт.
Итак, люди настраивали вручную и повторяли снова и снова. Теперь измученными являются специалисты по данным, а не покупатели. Усталость кругом!
Сегодня у нас больше обучающих наборов и улучшены возможности машинного обучения.
Но все еще есть проблемы, особенно связанные с определением функций; преобразование данных поискового каталога в эффективные обучающие наборы; получение суждений о релевантности, включая как явные суждения людей, так и неявные суждения, основанные на журналах поиска; и принятие решения о том, какую целевую функцию оптимизировать для конкретных приложений.
Что такое научиться ранжировать?
Обучение ранжированию (LTR) — это класс алгоритмических методов, которые применяют контролируемое машинное обучение для решения проблем ранжирования в релевантности поиска. Другими словами, это то, что заказывает результаты запроса. Сделано хорошо, у вас есть счастливые сотрудники и клиенты; сделано плохо, в лучшем случае у вас будут разочарования, а что еще хуже, они никогда не вернутся.
Для обучения ранжированию вам необходим доступ к обучающим данным, поведению пользователей, профилям пользователей и мощная поисковая система, такая как SOLR.
Данные обучения для модели обучения ранжированию состоят из списка результатов для запроса и рейтинг релевантности для каждого из этих результатов по отношению к запросу. Специалисты по данным создают эти обучающие данные, изучая результаты и принимая решение о включении или исключении каждого результата из набора данных.
Этот проверенный набор данных становится золотым стандартом, который модель использует для прогнозирования. Мы называем это исходной истиной и сравниваем с ней наши прогнозы.
Точечный, парный и списочный LTR-подходы
Три основных подхода к LTR известны как точечный, парный и списочный.
Точечный
Точечный подход рассматривает один документ за раз, используя классификацию или регрессию, чтобы найти наилучшее ранжирование для отдельных результатов.
Классификация означает помещение схожих документов в один и тот же класс — подумайте о сортировке фруктов по стопкам по типам; клубника, ежевика и черника относятся к группе ягод (или классу), а персики, вишня и слива относятся к группе косточковых фруктов. (Видео: кластеризация и классификация)
Регрессия означает присвоение похожим документам аналогичного значения функции, чтобы мы могли назначать им аналогичные предпочтения во время процедуры ранжирования.
Во время этих процессов мы даем каждому документу баллы за то, насколько он подходит. Мы добавляем их и сортируем список результатов. Обратите внимание, что оценка каждого документа в списке результатов для запроса не зависит от оценки любого другого документа, т. е. каждый документ считается «баллом» для ранжирования, независимым от других «баллов»
Попарно
Попарно подходит для просмотра двух документов вместе. Они также используют классификацию или регрессию — чтобы решить, какая из пар занимает более высокое место.
Мы сравниваем эту пару выше-ниже с истинной правдой (золотым стандартом данных ранжирования рук, который мы обсуждали ранее) и корректируем ранжирование, если оно не совпадает. Цель состоит в том, чтобы свести к минимуму количество случаев, когда пара результатов находится в неправильном порядке относительно основной истины (также называемой инверсией).
Listwise
Listwise подходы определяют оптимальный порядок всего списка документов. Идентифицируются наземные списки истинности, и машина использует эти данные для ранжирования своего списка. Списочные подходы используют вероятностные модели для минимизации ошибки порядка. Они могут быть довольно сложными по сравнению с точечными или парными подходами.
Рис. 1. Обучение (получению и) рангу — Интуитивно понятный обзор — Часть III0117
Прежде чем приступить к построению моделей, вам необходимо определиться с подходом, который вы хотите использовать.
При одних и тех же данных лучше обучать одну модель для всех или несколько моделей для разных наборов данных? Как известные модели обучения ранжированию справляются с этой задачей?
Вам также необходимо:
- Перед созданием обучающего набора данных определиться с объектами, которые вы хотите представить, и выбрать надежные суждения о релевантности.
- Выберите используемую модель и цель для оптимизации.
В частности, обученные модели должны быть способны обобщать:
- Ранее невиданные запросы, не входящие в обучающий набор, и
- Ранее не просмотренные документы должны быть ранжированы по запросам, обнаруженным в обучающем наборе.
Кроме того, увеличение доступных обучающих данных улучшает качество модели, но высококачественные сигналы, как правило, разрежены, что приводит к компромиссу между количеством и качеством обучающих данных. Понимание этого компромисса имеет решающее значение для создания наборов обучающих данных.
Корпорация Майкрософт разрабатывает алгоритмы обучения ранжированию
Доступные варианты обучения алгоритмам ранжирования за последние несколько лет расширились, что дает вам больше возможностей для принятия практических решений в отношении вашего проекта обучения ранжированию. Это довольно технические описания, поэтому, пожалуйста, не стесняйтесь обращаться с вопросами.
RankNet, LambdaRank и LambdaMART — популярные алгоритмы обучения ранжированию, разработанные исследователями Microsoft Research. Все используют попарное ранжирование.
RankNet представляет использование градиентного спуска (GD) для изучения функции обучения (обновления весов или параметров модели) для задачи LTR. Поскольку GD требует вычисления градиента, RankNet требует модели, для которой выход представляет собой дифференцируемую функцию , что означает, что ее производная всегда существует в каждой точке ее области (они используют нейронные сети, но это может быть любая другая модель с этим свойством).
Обучение ранжированию (LTR) — это класс алгоритмических методов, которые применяют контролируемое машинное обучение для решения проблем ранжирования в релевантности поиска. Другими словами, это то, что заказывает результаты запроса. Сделано хорошо, у вас есть счастливые сотрудники и клиенты; сделано плохо, в лучшем случае у вас будут разочарования, а что еще хуже, они никогда не вернутся.
RankNet представляет собой парный подход и использует GD для обновления параметров модели, чтобы минимизировать стоимость (RankNet был представлен с функцией стоимости Cross-Entropy). Это похоже на определение силы и направления для применения при обновлении позиций двух кандидатов (один занимает более высокое место в списке, а другой — более низкий, но с той же силой). В качестве окончательного решения по оптимизации они ускоряют весь процесс, используя мини-пакетный стохастический градиентный спуск (вычисление всех обновлений веса для данного запроса перед их фактическим применением).
LambdaRank основан на идее, что мы можем использовать одно и то же направление (градиент, оцененный по паре кандидатов, определяемой как лямбда) для замены, но масштабируя его изменением конечной метрики, такой как nDCG, на каждом шаге ( например, замена пары и немедленное вычисление дельты nDCG). Это очень удобный подход, поскольку он поддерживает любую модель (с дифференцируемым выходом) с метрикой ранжирования, которую мы хотим оптимизировать в нашем случае использования.
LambdaMART вдохновлен LambdaRank, но основан на семействе моделей под названием MART (Multiple Additive Regression Trees). Эти модели используют деревья с усилением градиента, которые представляют собой каскад деревьев, в которых градиенты вычисляются после каждого нового дерева, чтобы оценить направление, которое минимизирует функцию потерь (которая будет масштабироваться вкладом следующего дерева). Другими словами, каждое дерево вносит вклад в шаг градиента в направлении, которое минимизирует функцию потерь. Ансамбль этих деревьев является окончательной моделью (т. е. деревьями повышения градиента). LambdaMART использует этот ансамбль, но заменяет этот градиент лямбдой (градиент, вычисленный на основе пар кандидатов), представленным в LambdaRank.
Этот алгоритм часто считают попарным, поскольку лямбда рассматривает пары кандидатов, но на самом деле он должен знать весь ранжированный список (т. четкая характеристика подхода Listwise.
Обучение ранжированию приложений в промышленности
Wayfair
В сообщении в своем техническом блоге Wayfair рассказывает о том, как они использовали обучение ранжированию для целей поиска по ключевым словам. Wayfair — это публичная компания электронной коммерции, которая продает товары для дома. Таким образом, поиск имеет решающее значение для взаимодействия с клиентами. Wayfair решает эту проблему, используя LTR в сочетании с методами машинного обучения и обработки естественного языка (NLP), чтобы понять намерения клиента и предоставить соответствующие результаты.
На приведенной ниже схеме показана поисковая система Wayfair. Они извлекают текстовую информацию из различных наборов данных, включая обзоры пользователей, каталог продуктов и историю посещений. Затем они используют различные методы НЛП для извлечения сущностей, анализа настроений и преобразования данных.
Затем Wayfair передает результаты в свой собственный модуль Query Intent Engine, чтобы определить намерения клиентов по большей части входящих запросов и направить многих пользователей прямо на нужную страницу с отфильтрованными результатами. Когда Intent Engine не может найти прямое соответствие, они используют модель поиска по ключевым словам. И тут на помощь приходит LTR.
Рисунок 2. Система поиска Wayfair
В своем подходе к поиску по ключевым словам Wayfair выполняет входящий поиск для получения результатов по всему каталогу продуктов. Под капотом они обучили модель LTR (используемую Solr) для присвоения оценки релевантности отдельным продуктам, возвращенным для входящего запроса. Затем Wayfair обучает свою модель LTR на данных о кликах и журналах поиска, чтобы предсказать оценку для каждого продукта. Эти оценки в конечном итоге будут определять позицию продукта в результатах поиска. Модель улучшается со временем, поскольку она получает обратную связь от новых данных, которые генерируются каждый день.
Результаты показывают, что эта модель улучшила коэффициент конверсии запросов клиентов Wayfair. В частности, они создали персонализированную сортировку по релевантности и поиск по разделам, называемым лучшими результатами, который представляет как персонализированные, так и недавние результаты в одном представлении. Обратите внимание, что поиск внутри Slack сильно отличается от обычного веб-поиска, потому что каждый пользователь Slack имеет доступ к уникальному набору документов, и то, что актуально в данный момент, часто меняется.
Slack предлагает две стратегии поиска: недавние и релевантные. Недавний поиск находит сообщения, соответствующие всем терминам, а затем представляет их в обратном хронологическом порядке. Релевантный поиск ослабляет ограничение по возрасту и учитывает, насколько документ соответствует условиям запроса.
Сотрудники Slack заметили, что релевантный поиск работает немного хуже, чем недавний поиск, в соответствии с показателями качества поиска, такими как количество кликов на поиск и рейтинг кликов результатов поиска на нескольких верхних позициях.
Рисунок 3. Лучшие результаты по запросу «дорожная карта платформы»
Включение дополнительных функций, несомненно, улучшит ранжирование результатов релевантного поиска. Для этого команда Slack использует двухэтапный подход: (1) использование настраиваемой функции сортировки Solr для извлечения набора сообщений, ранжированных только по нескольким избранным функциям, которые Solr легко вычислить, и (2) повторное ранжирование. эти сообщения на прикладном уровне в соответствии с полным набором функций, взвешенных соответствующим образом. При построении модели для определения этих весов первой задачей было создание размеченного обучающего множества. Команда Slack использовала описанный ранее попарный метод, чтобы оценить относительную релевантность документов в рамках одного поиска с помощью кликов.
Этот подход был включен в модуль лучших результатов Slack, который показывает значительное увеличение количества поисковых сеансов на пользователя, увеличение количества кликов на поиск и сокращение поисков на сеанс. Это указывает на то, что пользователи Slack могут быстрее находить то, что ищут.
Skyscanner
Skyscanner, приложение для путешествий, где пользователи ищут авиабилеты и бронируют идеальное путешествие, использует LTR для поиска маршрута полета.
Поиск сложен и включает в себя цены, доступное время, промежуточные рейсы, окна для путешествий и многое другое. Цель Skyscanner — помочь пользователям найти лучшие рейсы для их обстоятельств.
Команда Skyscanner переводит проблему ранжирования элементов в задачу бинарной регрессии. Они помечают свои данные об элементах, которые пользователи считают релевантными их запросам, как положительные примеры, а данные об элементах, которые пользователи считают не относящимися к их запросу, — как отрицательные примеры. Затем они используют эти данные для обучения модели машинного обучения для прогнозирования вероятности того, что пользователь найдет рейс, соответствующий поисковому запросу. В частности, термин релевантность определяется как переход по ссылке на веб-сайт авиакомпании и туристического агентства для его покупки, поскольку это требует от пользователя множества действий.
Рисунок 4. Релевантность при поиске авиабилетов: результат поиска релевантен, если вы его купили. В частности, они сравнивают пользователей, которым дали рекомендации с помощью машинного обучения, пользователей, которым дали рекомендации с помощью эвристики, учитывающей только цену и продолжительность, и пользователей, которым вообще не давали рекомендаций.