Содержание
YATI — новый алгоритм Яндекса 2020
Спикер: Дмитрий Севальнев, основатель и евангелист сервиса «Пиксель Тулс»
2020 год ознаменовался не только эпидемией коронавируса, но и запуском нового алгоритма Яндекса — YATI (Yet Another Transformer with Improvements). Это технология, основанная на нейронных сетях, целью которой является оценка смысловой близости запроса пользователя и документа (веб-страницы).
По мнению специалистов Яндекса, это наиболее значимое событие для поиска за последние 10 лет (со времен запуска Матрикснета). Чтобы оценить всю важность этого запуска, можно вспомнить хотя бы тот факт, что до 2016 года до 95% слов на странице никак не учитывались Яндексом. Они просто игнорировались его алгоритмами.
Вот пример страницы, где цветом отмечены те слова, которые распознавались и учитывались поиском:
Регулярные изменения в поиске vs «Core Updates»
В целом 2020 год для Яндекса был очень мощным, а с октября по декабрь выдача находилась в режиме перманентного шторма.
Постоянное отслеживание апдейтов при помощи инструментов «Пиксель Тулс» позволяет различать некоторые регулярные изменения в поиске (их бывает 300-500 в год) и фундаментальные, касающиеся непосредственно алгоритма ранжирования, которые называются «Core».
Core Updates затрагивают большую долю поисковых запросов и часто связаны с переобучением формулы или новым подходом.
Поисковые системы по-разному информируют оптимизаторов о Core Updates. Так например Google, в котором за истекший год было 3 обновления основного алгоритма – в январе, мае и декабре, чётко предупреждал о начале запуска каждого из них, как правило, коротко в социальных сетях. Яндекс же, по факту, не анонсирует сами запуски, однако раскрывает больше деталей в статьях, посвященных апдейтам.
Как известно, Яндекс анонсировал свой новый алгоритм в ноябре. Однако, согласно измерениям «Пиксель Тулс», в этом месяце никаких изломов в динамике средних показателей выдачи Яндекса не было. Последний излом наблюдался 28-30 сентября 2020 года, что как раз и может свидетельствовать о запуске нового алгоритма.
Вероятней всего, мы уже давно живем в реалиях нового алгоритма и говорить о его раскатке непосредственно в ноябре не приходится.
Использование нейронных сетей в алгоритмах ранжирования: основные вехи и примеры
Нейронные сети — это один из методов машинного обучения. А как известно, машинное обучение используется в поиске с начала 2000-х.
В 2009 году Яндекс анонсировал алгоритм Снежинск, который использовал технологию на основе машинного обучения MatrixNet.
В 2016 году Яндекс впервые публично заявил о применении нейросетей, представляя алгоритм Палех. Однако совершенно точно нейросети использовались Яндексом и ранее, в частности, в работе сервиса Яндекс.Переводчик. Тогда инженеры Яндекса честно заявили:
«Далекая, но чрезвычайно интересная цель поиска Яндекса состоит в том, чтобы получить на основе нейронных сетей модели, способные «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека».
Палех является одной из важных вех развития поиска Яндекса на пути к технологии YATI, также как и алгоритм Королёв, анонсированный в 2017 году.
Аналогичными вехами в развитии поиска Google можно обозначить разработку программного обеспечения Word2vec в 2013 году, а также запуск алгоритма BERT в 2019-м.
Нужно понимать, что нейронные сети ни в коем случае не пришли на замену всей поисковой формуле ранжирования. Факторы, вычисленные с помощью нейросетей, являются «одними из» в общей совокупности факторов, которые используются для построения итоговой формулы.
В результате на выдаче по запросу мы можем видеть как документы, релевантные по своей смысловой составляющей, так и документы, содержащие точное вхождение запроса:
Пример «смешанной» выдачи
Условно говоря, каждый из факторов «тянет» в свою сторону, в результате происходит «борьба» факторов, отвечающих за «смысл», с теми, которые отвечают за «обычные вхождения» в текст.
В «борьбе» принимают участие и все остальные группы факторов:
- Поведенческие
- Хостовые факторы (сайт)
- Ссылочные
Это доказывает, что Яндекс не действует по принципу замены всего уже существующего новым алгоритмом, а по принципу улучшения существующей формулы новыми технологиями.
В ряде случаев, когда прямых ответов на запрос пользователя оказывается мало (24 документа по точному вхождению фразы [фильм про человека который выращивал картошку на другой планете]), факторы, отвечающие за смысл, начинают играть большую роль.
Как видим, по этому запросу в выдаче преобладают документы, найденные по «смыслу». Только один информационный сайт, содержащий точное вхождение, смог попасть в смысловой ТОП, благодаря своим прокачанным хостовым факторам.
Это позволяет сделать важный вывод:
С запуском YATI в Яндексе – факторы смысла стали впервые «бить» факторы вхождений (правда пока только по мНЧ-фразам).
BERT (Bidirectional Encoder Representations from Transformers) от Google и YATI: важные нюансы
В статье на Хабре, посвященной раскрытию технических деталей технологии YATI, алгоритм BERT обозначен как ее прямой конкурент. При этом YATI приписывается большая эффективность, чем модели BERT:
- – nDCG – широко принятая метрика оценки качества выдачи, учитывающая позицию каждого документа в выдаче и асессорскую (экспертную) оценку его релевантности (n – нормировка)
Нужно сказать, что технология BERT способна решать гораздо большее число задач, но, в том числе используется и для понимания «смысла» текста. На модели BERT базируется большое семейство языковых моделей:
На модели BERT базируется большое семейство языковых моделей:
С точки зрения компьютерной лингвистики, BERT и YATI – это очень близкие алгоритмы. И Яндекс к YATI не сразу пришел.
Первым шагом, как уже упоминалось выше, был Палех, когда Яндекс впервые заявил, что научился понимать смысл текстов. Затем то же самое было озвучено при запуске Королёва. Вероятно, по этой причине технология YATI была анонсирована довольно скромно, без всякой помпы и акцентов на том, что поиск ещё лучше научился понимать смысл текстов, хотя технология действительно является прорывной.
Нюансы в YATI, которые нужно учитывать:
- Переформулировки и «пред-обучение на клик». База Яндекса из 1 млрд переформулировок: [первичная фраза] —> нет клика —> [новая фраза]. Модель учится предсказыать вероятность клика.
- Оценки толокеров. На втором этапе используются «более дешёвые и простые оценки» толокеров из Яндекс.Толоки.
- Оценки асессоров.
 Далее для обучения используются экспертные (асессорские) оценки релевантности.
Далее для обучения используются экспертные (асессорские) оценки релевантности. - Данные, подаваемые на вход:
 Далее для обучения используются экспертные (асессорские) оценки релевантности.
Далее для обучения используются экспертные (асессорские) оценки релевантности. - Текст запроса
- Расширение запроса (синонимы, дополнительные слова)
- «Хорошие» фрагменты документа
- Стримы для документа: анкор-лист, запросный индекс для документа (даже не показы, а клики по запросам)
Сможет ли YATI победить накрутку ПФ в Яндексе
Ситуация с накруткой ПФ на конец 2020 года очень проблемная. Первая волна санкций за накрутку ПФ была отмечена в начале осени, и многие проекты до сих пор продолжают терять видимость практически до нуля.
Яндекс наказывает сайты, чьи поведенческие факторы кажутся ему неестественными. И некоторые проекты потеряли в видимости уже после запуска YATI, в том числе и 10 декабря.
Осталось еще много вопросов, тем не менее можно сказать, что ситуация с накруткой существенно улучшается.
Стоит привести здесь ответ одного из разработчиков нового алгоритма Яндекса:
«1 и 2 — Решающие деревья в GBDT работают немного по-другому.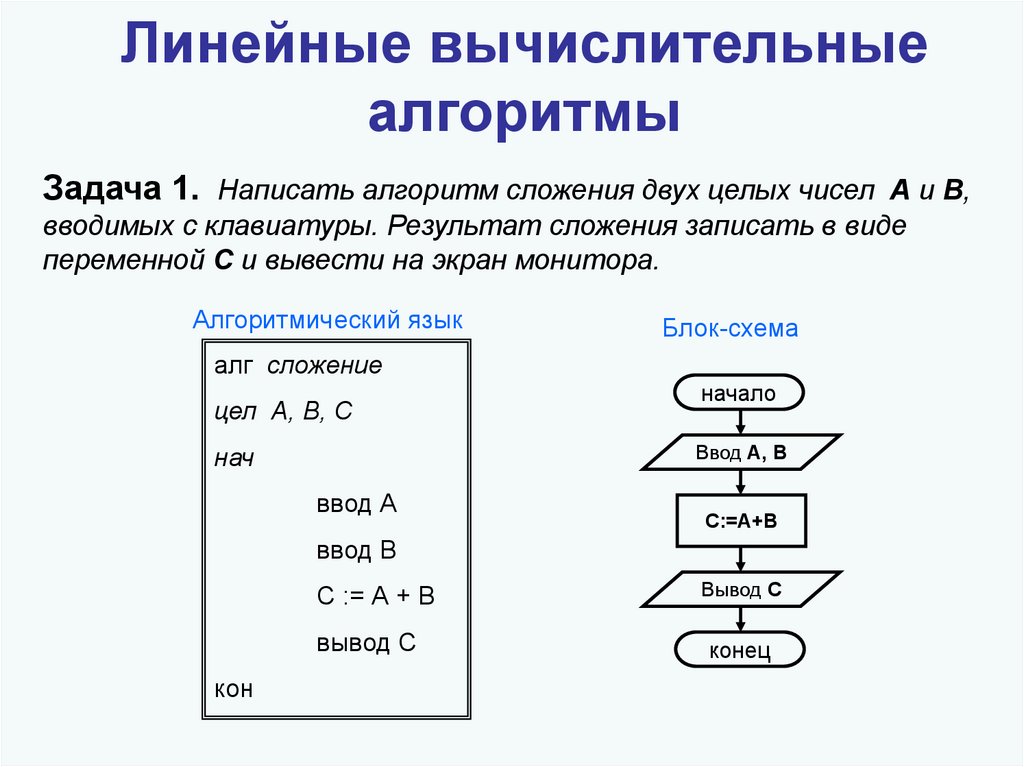 Глубина дерева фиксирована, мы её в наших моделях CatBoost не меняем. Если есть сильный признак, то Сплит по нему будет просто встречаться чаще (и возможно выше) в дереве той же глубины, и соответственно будет сильнее влиять на итоговое предсказание. Размер влияния можно увидеть например по метрике FSTR, которая численно оценивает вклад конкретного признака в предсказание. В случае с YATI – вклад новой модели заметно больше 50% от суммарного вклада вех признаков. В этом смысле трансформер решает «больше половины» задачи ранжирования».
Глубина дерева фиксирована, мы её в наших моделях CatBoost не меняем. Если есть сильный признак, то Сплит по нему будет просто встречаться чаще (и возможно выше) в дереве той же глубины, и соответственно будет сильнее влиять на итоговое предсказание. Размер влияния можно увидеть например по метрике FSTR, которая численно оценивает вклад конкретного признака в предсказание. В случае с YATI – вклад новой модели заметно больше 50% от суммарного вклада вех признаков. В этом смысле трансформер решает «больше половины» задачи ранжирования».
Мы видим, что возможность отказаться от учета кликового фактора у Яндекса есть, и это позволит ему в дальнейшем эффективно бороться с накрутками.
От теории к практике
По поводу всего вышесказанного читатель может сказать : «Да, это все очень круто. Но как мне использовать YATI для продвижения своего сайта? И чего от него ждать?».
Исходя из утверждения, что YATI обеспечивает более 50% вклада в ранжирование, можно ожидать, что теперь «смысл» окончательно победил возможности SEO-специалистов в оптимизации текстов (и можно больше ничего не оптимизировать). Равно как и того, что все факторы вида «точное вхождение», «Title» и «добавить ключей» остались в прошлом. Хотя… Оценка же сильно зависит от того, какие запросы берутся для выборки. Как все на самом деле?
Равно как и того, что все факторы вида «точное вхождение», «Title» и «добавить ключей» остались в прошлом. Хотя… Оценка же сильно зависит от того, какие запросы берутся для выборки. Как все на самом деле?
Изначально для улучшения ранжирования поисковая система Яндекс, конечно же, обучалась на редких запросах, по которым итак документов недостаточно. Поэтому в 50% вклад в ранжирование именно этих запросов вполне можно поверить. Именно на них очень хорошо видна та борьба между «смыслом» и «вхождением», в которой «смысл» начал побеждать. Но какова ситуация по ВЧ-запросам, по средне- и низкочастотным?
Лаборатория «Пиксель Тулс» провела небольшое исследование, сравнив значимость фактора «точное вхождение в тексте» по НЧ-запросам в 2019 и 2020 годах (после запуска YATI).
Как видим, «точное вхождение» никуда не пропало, а наоборот, увеличило свою значимость.
Что же произошло за год с СЧ и ВЧ-запросами? Вот тут ситуация с точным вхождением поменялась — явного влияния в ТОП-10 теперь нет, хотя вне его оно сохраняется.
При этом среднее значение фактора – в районе единицы, что означает, что одно вхождение есть и этого более чем достаточно.
Рассмотрим также на выборке коммерческих запросов роль фактора «наличие всех слов из запроса в тексте» в Яндексе:
Как видим, здесь особой разницы между НЧ и СЧ+ВЧ запросами нет. Однако, прослеживается определенная корреляция между попаданием в ТОП и наличием всех слов запроса в документе. Причем значение этого фактора — 0.8, то есть, это справедливо для 80% сайтов. А значит рекомендация по добавлению всех слов из запроса в текст по-прежнему является актуальной.
Проверим таким же образом и «слова в Title» после YATI:
В 2020 году наблюдается рост среднего значения этого фактора относительно 2019 года, то есть значительно чаще в выдаче стали встречаться документы у которых есть все слова запроса в Title, однако есть видимое уменьшение корреляции с позицией. Можно сказать, что этот фактор необходим для попадания на выдачу, но не влияет на позицию в этой выдаче. И для НЧ-запросов он важней, чем для СЧ и ВЧ.
И для НЧ-запросов он важней, чем для СЧ и ВЧ.
7 практических советов:
1. Оптимизируйте под YATI.
Нужно увеличить количество слов, которые встречаются в контексте со словами из поискового запроса. Это могут быть слова из подсветки выдачи; слова, задающие тематику; слова, которые встречаются у конкурентов, но которых нет на продвигаемой странице.
2. Форматируйте текст и расставляйте акценты
Обязательно используйте форматирование при «большом объеме контента» (более 12-14 предложений). Выносите в заголовки и выделенные фрагменты тематические и ключевые слова.
3. Анализируйте и оптимизируйте запросный индекс для документов (Яндекс.Вебмастер —> Поисковые запросы)
- Изучите поисковые запросы, по которым были зафиксированы переходы на URL, они должны быть релевантными
- Проверьте релевантность запросов, по которым были показы, но не было переходов. В случае нерелевантности фраз — примите меры.
4. Запросный индекс для хоста
Запросный индекс для хоста
Данные всего хоста (сайта), как и ранее, сказываются на факторах для заданной страницы. Поэтому проверки, описанные в пункте 3, актуальны и в разрезе всего сайта, а не только заданного URL.
5. Расширяйте семантическое ядро для продвижения в сторону НЧ-запросов
«Вложенные» и синонимичные запросы помогают в продвижении по более общим и близким по смыслу. Пример: [seo продвижение сайта цена в москве] поможет и для [продвижение сайтов] и для [smm продвижение].
6. Проводите конкурентный анализ
Анализируйте показы URL конкурентов по запросам; присматривайтесь к текстам: какие там тематические слова, фразы, структура; анализируйте структуру сайта и охват запросов из семантического ядра. (В помощь: Вебинар по анализу конкурентов в выдаче и шаблон анализа конкурентов )
7. Не забывайте про классику поисковой оптимизации: текст, точные вхождения, все слова в Title
Выводы:
Хоть YATI и выглядит прорывной технологией, надо помнить, что Яндекс строится по принципу «добавить сверху», а не «написать всё с нуля» – то есть, новые факторы добавляются к старым.
Роль смысловой близости текста и запроса растёт, если у поисковой системы нет или мало данных о поведении по данному запросу и мало документов, которые «хороши» по классическим текстовым факторам.
Максимальный прирост идёт по неоднозначным, многословным и редким запросам (длинный хвост).
На вход YATI подаются различные стримы: анкор-лист документа, запросный индекс по кликам.
А что ещё надо делать, учитывая, что в Яндексе новый алгоритм ранжирования?
Обновить распределение
Если вы давно делали группировку запросов и распределение (более 4-6 месяцев назад) – самое время её переделать. YATI, также как и в свое время Королёв, существенно изменил состав кластеров, которые формируются при анализе ТОПов. Ряд запросов могли поменять свой тип — стать целевыми или наоборот.
Вообще, раз в 3 месяца рекомендуется «освежать» семантику и учитывать актуальный состав выдачи. Всем удачи в продвижении!
Алгоритмы ранжирования в поиске Яндекса: история развития, список и интересные факты о поисковых обновлениях
Согласитесь, интересно, как поисковики понимают, какой из сайтов займет ту или иную позицию. Можно ли создать идеальный ресурс, который сразу ворвется в топ, если все, что для этого нужно – угодить определенным требованиям?
Можно ли создать идеальный ресурс, который сразу ворвется в топ, если все, что для этого нужно – угодить определенным требованиям?
В этой статье поговорим о хронологии развития алгоритмов ранжирования поисковой системы Яндекс, осветим интересные факты из истории их работы и внедрения, ну и попробуем понять, в чем секрет попадания на вершину выдачи, и можно ли его разгадать.
- Найди меня, если сможешь: что такое поисковой алгоритм
- Как развивалась поисковая система Яндекса
- Список всех алгоритмов поиска Яндекса по годам
- Июль 2007 – «Версия 7»
- Декабрь 2007 «Версия 8» и «Восьмерка SP1»
- Май 2008 – Магадан
- Сентябрь 2008 – Находка
- Апрель 2009 – Арзамас/Анадырь
- Сентябрь 2009 – Снежинск
- Декабрь 2009 – Конаково
- Март 2010 – Конаково 1. 1
- Сентябрь 2010 – Обнинск
- Декабрь 2010 – Краснодар
- Август 2011 – Рейкьявик
- Декабрь 2012 – Калининград
- Май 2013 – Дублин
- Март 2014 – Без ссылок
- Июнь 2014 – Острова
- Апрель 2015 – Объектный ответ
- Май 2015 – Минусинск
- Сентябрь 2015 – Многорукие бандиты
- Февраль 2016 – Владивосток
- Ноябрь 2016 – Палех
- Март 2017 – Баден-Баден
- Август 2017 – Королев
- Ноябрь 2018 – Андромеда
- Декабрь 2019 – Вега
- Сентябрь 2020 – Yati
- Июнь 2021 – Y1
- Август 2022 – Мимикрия
- Что в итоге
 1
1Мария Албегова
Главный редактор
Когда в 2015 году я впервые узнала о SEO, то сразу подумала, что это магия на уровне ягод Годжи. Ты делаешь сайт, а потом происходит что-то, что продвигает его повыше, потом ещё выше, а потом его находят люди и покупают твои товары или заказывают услуги. Почему один ресурс занимает 50 место, а другой входит в десятку? Как, почему это случается и кто отвечает за внутренние механизмы, понимания не было. Уже потом я узнала, что в этом есть своя логика. Правда, складывалась она годами и постоянно совершенствовалась. О ней мы и будем говорить дальше.
Ты делаешь сайт, а потом происходит что-то, что продвигает его повыше, потом ещё выше, а потом его находят люди и покупают твои товары или заказывают услуги. Почему один ресурс занимает 50 место, а другой входит в десятку? Как, почему это случается и кто отвечает за внутренние механизмы, понимания не было. Уже потом я узнала, что в этом есть своя логика. Правда, складывалась она годами и постоянно совершенствовалась. О ней мы и будем говорить дальше.
Найди меня, если сможешь: что такое поисковой алгоритм
Чтобы лучше понимать, о чем пойдет речь в статье, погрузимся в мир теории. Да, она мало кому нравится, но не станем сильно усложнять себе жизнь.
Обещаю, в дальнейшем её будет немного.
Набор правил и формул, которые помогают роботам понять, насколько страница ресурса соответствует запросу, чтобы в дальнейшем построить выдачу и определить, по какому принципу ранжировать находящееся в ней, называется поисковым алгоритмом.
Условно разделим фильтры на две группы, разграничив по принципу работы.
- Прямого действия – медленные, потому что, пытаясь угодить пользователю, перелопачивают всю доступную информацию. При этом ответ создают максимально полный.
- Обратного индекса – формируют базу, где на каждый термин собраны ссылки с документами, которые его содержат. Производят менее релевантный массив итоговых данных, однако работают куда быстрее и используются в современных ПС.
Как развивалась поисковая система Яндекса
Все началось с учета количества и расположения ключевиков на странице. Если у вас их больше, чем у конкурентов – ваш сайт будет выше в топе.
Такой метод был необъективным и существенно мешал пользователям. Ведь найти нужную информацию среди переоптимизированных потолотен было практически невозможно. Именно поэтому еще с самого начала работы ПС разработчики корпели над усовершенствованием методик ранжирования. Сейчас рассмотрим, как это происходило на протяжении 15 лет.
Читайте также
ТОП инструменты для SEO-продвижения: 20+ бесплатных сервисов
Список всех алгоритмов поиска Яндекса по годам
Чтобы вам было проще составить целостную картину развития, мы рассказали о каждом обновлении в хронологическом порядке.
Июль 2007 – «Версия 7»
Отмечу, что до этой даты про то, как всё устроено, вообще мало кто знал. Официально компания не рассказывала деталей. «Версия 7» считается первым нововведением, о котором было объявлено.
Что изменилось: выдача стала более релевантной, по-разному ранжируются однословные и многословные виды запросов.
Декабрь 2007 «Версия 8» и «Восьмерка SP1»
Появился фильтр, борющийся с накруткой ссылок. Более авторитетные ресурсы получили приоритетность в ранжировании.
После 2008-го поисковик 1-2 раза в год анонсировал очередной алгоритм. Интересны их названия. Они составлялись по принципу игры в города. Каждый новый назывался в честь топонима на последнюю букву предыдущего.
Май 2008 – Магадан
Можно назвать революционным.
- В 2 раза выросли факторы ранжирования.
- Расширилась база сокращений и аббревиатур, синонимы и транслитерация тоже теперь учитываются. Поисковик начал считывать иностранные написания и ресурсы на зарубежных языках. Выдача наполнилась порталами на немецком, английском, итальянском, испанском и других.
- Корректнее различаются типы и виды ссылок и страниц друг от друга.
- Повысились требования к уникальности контента.
 Выдача наполнилась порталами на немецком, английском, итальянском, испанском и других.
Выдача наполнилась порталами на немецком, английском, итальянском, испанском и других.Сентябрь 2008 – Находка
- Учитываются стоп-слова, что, естественно, увеличило количество вариантов с междометиями, знаками препинания, местоимениями.
- Тезаурус получил большое расширение. Например, система стала лучше понимать слова, которые могут писать как слитно, так и раздельно: видеоигры и видео игры.
Апрель 2009 – Арзамас/Анадырь
Основные изменения после обновления алгоритма выдачи Яндекса:
- Значительно лучше ранжируются запросы, которые потенциально могли иметь несколько разных значений. Например «фото львов». В этом случае непонятно, что ожидает увидеть человек – город или животное. Во внимание берется история поиска конкретного пользователя для более точного попадания.
- При формировании ответа на вопрос начало учитываться и местоположение персоны. Выделили 19 основных регионов для разделения по принципу положения на карте.
- Сами вопросы теперь разделились на зависимыми от географии и независимые от неё. ПС сама определяла вид вопроса и меняла принципы ранжирования. Сайты получили свои регионы, которые определял IP хостинга.

Сентябрь 2009 – Снежинск
Известен прежде всего появлением Matrixnet, который сделал качество поиска в разы лучше.
Он поменял привычную выдачу – появились региональные факторы, фильтры АГС, которые исключали некачественные ресурсы из показов. А вот страницы с кучей ключей в тексте стали понижаться.
Декабрь 2009 – Конаково
Главная задача – расширение географических факторов. Ранее ранжировались 19 регионов, теперь еще – 1250 городов.
Март 2010 – Конаково 1.1
Выросла доля информационников в топе – энциклопедии, журналы, обзоры.
А независимые от локации написания начали лучше ранжироваться.
Сентябрь 2010 – Обнинск
Основная цель – улучшение ранжирования по геонезависимым запросам, которых, по данным Яндекса, было до 70 % от общего количества.
- Искусственные ссылки стали хуже продвигаться.
- Улучшилось ранжирование иностранных написаний.
- Появилась возможность определения авторства текста.
Декабрь 2010 – Краснодар
Знаменит появлением технологии «Спектр». Ее особенность состояла в том, что она классифицировала вводимое в строку ПС в зависимости от вида потребности и разделяла этот массив по категориям.
Например:
Человек вводит «Наполеон». Сразу и не поймешь, он про торт или про императора Франции. Что делает алгоритм – изучает массив данных и понимает, что 70% людей в таком случае интересовались биографией известной личности и только 30% исследовали гастрономические изыски.
В итоге наш герой получит следующий результат: 7 ссылок про полководца, 3 – про торт.
А ещё:
- Яндекс начал индексировать ВК.
- Запросы начали делиться на тематические категории.
- Для некоторых организаций введены расширенные сниппеты.

Август 2011 – Рейкьявик
Сделал первый шажок к персонализации. Для начала стали учитываться языковые пожелания. Если вы ранее вводили слова на латинице и отдавали предпочтение зарубежным ресурсам, то теперь система начнет подстраиваться под вас и предлагать больше иностранных порталов, уменьшая количество русскоязычного контента в сети вокруг вас.
Что еще изменилось:
- Данные с опечатками – вы можете видеть варианты выдачи по двум видам написания.
- Авторство контента – в Вебмастере появился инструмент, в который можно было добавить свой текст, чтобы сайт, на котором он размещен, стал считаться первоисточником.
- Яндекс.Справочник – появилась возможность внести туда информацию об организации.
Декабрь 2012 – Калининград
Виват, персонализация! Роботы отныне учитывают интересы конкретного человека и историю его поиска, чтобы выдавать релевантные ответы и в подсказках и в конечных результатах.
Оптимизаторам этот алгоритм точно прибавил работы. Ведь выдача стала практически уникальной для каждого из нас. А продвижение усложнилось учетом многих факторов: ссылок, качества контента и дизайна, оптимизации и полноты семантического ядра.
Май 2013 – Дублин
Обновленный Калининград.
В чем отличие: в более ранней версии во внимание принимались длительные интересы конкретного человека, а вот Дублин начал учитывать и краткосрочные, т.е те, которые актуальны на данный момент. Они и легли в основу формирования ответа.
После этого алгоритма Яндекс заканчивает играть в города. Вот и все. Далее названия формируются по одним только разработчикам системы известным принципам. Среди них будут встречаться и города, и астрономические названия, и иностранные сокращения. О них и расскажем далее.
Март 2014 – Без ссылок
Небольшой кирпичик в фундамент по отмене продвижения за счет линков. В качестве эксперимента по Москве в ряде запросов перестали учитываться данные факторы. На тот момент изменения затронули популярные ниши: туризм, недвижимость, электронная техника.
На тот момент изменения затронули популярные ниши: туризм, недвижимость, электронная техника.
Июнь 2014 – Острова
Появился новый визуал с так называемыми областями. Это интерактивные элементы, которые появлялись прямо на странице и помогали пользователю получить информацию, не переходя на сайт.
Например – курс валют, погода, покупка билетов.
Однако затем эксперимент был признан неудачным и от него отказались.
Апрель 2015 – Объектный ответ
Дизайн выдачи снова поменялся. Справа показывалась довольно объёмная карточка, содержащая сведения о предмете или объекте из запроса. Род деятельности, описание, биографическая справка.
Кстати, у поисковика теперь есть собственная база с несколькими миллионами подобных карточек.
Май 2015 – Минусинск
Убийца сайтов с некачественной ссылочной массой. Произвел своеобразный фурор, пессимизировал многие ресурсы, которые так и не восстановились.
Правила продвижения с этих пор поменялись, подход к качеству и количеству линков тоже был пересмотрен.
Сентябрь 2015 – Многорукие бандиты
Немного экспериментов от Яндекса с целью рандомизировать выдачу. Все смешалось – в топе могли оказаться новички или те, кто раньше довольствовался низкими позициями. Такая стратегия помогла проанализировать поведенческие особенности.
Февраль 2016 – Владивосток
Люди все больше времени проводят в телефонах и планшетах.
Технологии позволили делать многое с этих девайсов – учиться, развлекаться, общаться. Собственно доля запросов с них стала расти. Новый алгоритм был призван проверить ресурсы на их пригодность к использованию с мобильных.
Сайты, имеющие адаптацию, повышались в результатах поиска, а без неё – опускались.
Ноябрь 2016 – Палех
Наконец-то помог Яндексу работать со сложными пользовательскими вопросами. Теперь робот ищет не только по словам, которые вбивает человек, но и анализируя смысл и заголовок. Таким образом мы можем получить нужную площадку, даже если на её странице нет ключей, которые мы вбивали.
Как работает на примере: если введем «Фильм про Джека Воробья». То и получим выдачу с названием произведения.
Март 2017 – Баден-Баден
Пришел в наш мир, чтобы победить засилье ключевиков и уничтожить переоптимизированные тексты.
«Мелкий шрифт, скрытый контент, тонна ключей? Будьте добры вниз. Вы нам в топе не нужны» – примерно так бы и разговаривал Баден с плохими сайтами, хотя это сильно сказано, он бы окрестил их неполезными.
Читайте также
SEO-текст: пишем полезную и оптимизированную статью
Август 2017 – Королев
Тоже же Палех, но более усовершенствованный. Теперь легче получить оптимальный ответ на более сложный и многозначный вопрос. Робот уже анализирует не только заголовок, но и содержание всей страницы, сопоставляя этот массив данных с запросом, вводимым в строку.
Искусственный интеллект принимает во внимание и статистику, и асессоров, и даже оценки, выставляемые пользователями.
Как работает: вводим, что нам нужно: «фильм, в котором все кладут телефоны на стол». И сразу же вы увидите название ленты и всю необходимую информацию. Так сработал ИИ.
Ноябрь 2018 – Андромеда
Вот несколько интересных дополнений:
- Яндекс ввел три знака качества. Они влияют и на место ресурса в выдаче.
- Сервис быстрых ответов стал работать действительно лучше и быстрее, помогая решать важные задачи.
- Появились Яндекс.Коллекции – мини-собрания полезной информации по тематике.
Декабрь 2019 – Вега
Нововведение, преобразовавшее подход к запросу пользователей.
Что изменилось:
- Палех определял, что нам нужно, по словам и смыслу, Вега же находит вдобавок и страницы, которые близки по смыслу. Это позволяет сделать основой ранжирования смысловые кластеры.
- Пререндеринг SERP больше не мечта. Он круто ускоряет поиск.
- Гиперлокальность выходит на новый уровень. Теперь человек получит ответы не только по городу, но и по микрорайону.
Сентябрь 2020 – Yati
YATI (Yet Another Transformer with Improvements) – система созданная для оценки качества текстов. В основе – принципы «Палеха» и «Королева». Работает за счет нейросети-трансформера.
Роботы перерабатывают сразу до 10 предложений, обращая внимание на единство заголовков, значений, структуры статьи и другой контент. Это они сопоставляют со смыслом получаемого запроса и предоставляют конечному пользователю наиболее подходящий ресурс.
Появление этого алгоритма заставило специалистов более внимательно подходить к формированию СЯ и качеству текстов. Типовой копирайтинг остался в прошлом.
Июнь 2021 – Y1
В основе обновления – технологии нейросетей YaTI и YaLM. Появилось более 2000 дополнений для реализации основной цели – сберечь время.
Что нового:
- Увеличилось количество быстрых ответов в выдаче, сами они получили более широкую направленность.
- Возник поиск по видео-фрагментам. Работает это так – вы вносите вопросы в строку поисковика, система анализирует результат и представляет вам фрагмент ролика с того времени, где содержится информация об искомом вопросе.
- Появилась оценка отзывов. Яндекс анализирует их массив и предоставляет пользователям уже сформированную шкалу.
- Стало возможным найти что-то с помощью умной камеры, которая распознает объекты.
Август 2022 – Мимикрия
Пока про это обновление известно немного. Суть довольно понятна: если один сайт копирует графический или текстовый контент другого, более успешного, то получит понижение в выдаче.
Оценивать это будут по следующим пунктам:
- текст;
- визуал;
- как оптимизированы страницы под навигационные запросы.
Если фавикон вашей площадки, или его дизайн похожи на аналогичные элементы какого-то популярного портала, то у нас для вас плохие новости. Скорее всего вы столкнетесь с пессимизацией и восстановить утраченные позиции будет очень сложно.
Что в итоге
В этой статье я собрала информацию, чтобы вам стало понятнее, как произошла эволюция Яндекса, по каким правилам он индексирует сайты и от чего зависит расположение того или иного ресурса в выдаче. Именно это станет началом на пути понимания механики продвижения.
Чтобы добиться результатов SEO, недостаточно просто написать текст с ключами или закупить ссылок. Это сложный процесс, который требует знаний и опыта. Читайте наш блог и учитесь, или сразу обращайтесь к нам за помощью в раскрутке площадки.
Яндекс — Технологии — Персонализированный поиск
Персонализированный поиск извлекает результаты и выдает поисковые подсказки индивидуально для каждого пользователя, исходя из его интересов и предпочтений. Интернет-пользователи в России, например, вводя в Яндексе запрос [ничего], скорее всего, ищут альбом Nirvana, а не хотят узнать, что означает это слово. Персонализированный поиск будет знать разницу и действовать соответствующим образом.
Персонализированный поиск Яндекса основан на языковых предпочтениях пользователя, его истории поиска и его кликах в результатах поиска. История поиска пользователя сообщает поисковой системе, что в данный момент может быть актуально для этого конкретного пользователя. Тот, кто ищет в Интернете бесплатное программное обеспечение, книги или музыку, скорее всего, заинтересуется этим типом контента как таковым. Те пользователи, которые часто посещают сайты на английском языке, могут очень оценить результаты поиска именно на этом языке. Поскольку личные предпочтения имеют тенденцию со временем меняться, Яндекс учитывает только относительно свежую историю поиска за период в несколько месяцев, чтобы предложить пользователям персонализированные результаты поиска и сделать персонализированные поисковые предложения.
Поисковые подсказки
В отличие от обычных поисковых подсказок, персонализированные поисковые подсказки адресованы индивидуально каждому пользователю Интернета. Угадывая, что искатель может захотеть найти, Яндекс предлагает потенциальные поисковые запросы, основываясь на том, что искали в Интернете другие люди со схожими онлайн-предпочтениями. Поисковая система классифицирует всех в одну из примерно 400 000 групп пользователей с более или менее общими интересами. Эта классификация изменчива — она меняется для каждого пользователя в соответствии с изменениями его онлайн-поведения.
На практике веб-пользователи повторяют около 25% своих поисковых запросов и часто нажимают на одни и те же результаты поиска. Такое поведение можно интерпретировать как посещение часто посещаемых веб-сайтов или просмотр популярных или лично важных веб-документов. Яндекс предлагает пользователям быстрый доступ к любимому контенту, показывая им недавно сделанные запросы и их любимые веб-сайты в поисковых подсказках, когда они вводят первую букву своего нового запроса.
При выборе поисковых подсказок для конкретного пользователя Яндекс также учитывает, какие поиски были выполнены ранее за весь поисковый сеанс. Таким образом, поисковая система будет знать, что Кристофер Ллойд, вероятно, будет лучшим предложением для поиска «с» в окне поиска, чем любое другое, если искатель ранее искал «Назад в будущее».
Персональные результаты
Помимо предоставления персонализированных поисковых подсказок, Яндекс помогает своим пользователям в достижении целей поиска, предоставляя им наиболее релевантные результаты поиска. При этом поисковая система использует специальный персонализированный алгоритм ранжирования, который пересчитывает в соответствии с постоянно меняющимися интересами и языковыми предпочтениями каждого пользователя.
Персонализированный алгоритм ранжирования позволяет поисковой системе понять, насколько каждый из полученных результатов соответствует ожиданиям пользователя. Результаты поиска оцениваются и ранжируются в соответствии с их полезностью для конкретного веб-пользователя. Один и тот же поисковый запрос, сделанный двумя разными людьми, приведет к тому, что одни и те же результаты ранжируются по-разному в соответствии с их индивидуальными интересами. Заядлый геймер и любитель художественного кино, например, увидят в верхней части результатов поиска ссылки на веб-сайты, соответствующие их интересам, даже если они оба ищут «Сталкер».
Алгоритм ранжирования Яндекса учитывает долгосрочные, среднесрочные и краткосрочные интересы каждого пользователя. Все это так или иначе влияет на результаты поиска. Долгосрочные интересы отражают язык, местонахождение, демографию, постоянные потребности или предпочтения пользователя, а краткосрочные интересы выражают то, что важно для пользователя прямо сейчас. Даже если вы более-менее всегда интересовались музыкой и кино, вы можете неожиданно обнаружить, что ищете компьютерную игру онлайн, и то только один раз. Поисковые интересы, которые приходят и уходят, составляют более половины всех поисковых запросов на Яндексе.
Чтобы быть в курсе долгосрочных интересов пользователя, Яндекс анализирует историю поиска за последние два месяца и последнюю неделю. Краткосрочные интересы отслеживаются в режиме реального времени путем просмотра текущих сеансов поиска, что позволяет поисковой системе отслеживать поисковые намерения пользователя. Когда человек с давним пристрастием к чтению выполняет поиск по названию популярного веб-сайта со списком фильмов, Яндекс может с уверенностью предположить, что этот человек ищет экранизацию:
Яндекс использует собственную технологию доставки данных для обработки запросов в режиме реального времени. Эта технология позволяет собирать данные и отправлять их в поисковую систему каждые семь секунд, чтобы каждый клик или поиск, который пользователь делает на Яндексе, учитывался и напрямую влиял на результаты поиска.
Персонализированный поиск включен по умолчанию для каждого более или менее частого пользователя поиска. Чем больше запросов делает пользователь, тем лучшие результаты и предложения может предоставить поисковая система. Персонализированный поиск деактивируется, если недостаточно поисковых запросов, на которых может быть основана персонализация, и снова активируется, когда начинают поступать запросы. Персонализацию также можно включить или отключить вручную в настройках поисковой системы.
В настоящее время персонализация на Яндексе лучше всего работает для поиска на русском языке, но по мере того, как поисковая система накапливает поисковую статистику на других языках, другие пользователи также смогут в полной мере ею пользоваться.
Состояние поисковой оптимизации Яндекса в мае 2015 года: интервью с Александром Садовским
В прошлом месяце Александр Садовский, глава естественного поиска Яндекса, сообщил подробности последних изменений в алгоритме Яндекса с обновлением под названием «Минусинск». Минусинск, названный в честь российского города, как и остальные обновления поискового алгоритма Яндекса, вызвал настоящий ажиотаж в поисковом мире из-за интерпретации, что объявление будет означать сильное изменение способа учета ссылок в алгоритме ранжирования Яндекса.
В марте 2014 года Яндекс объявил об удалении ссылок как фактора ранжирования коммерческих запросов во многих топовых вертикалях поиска, проводимого в Московской области. Когда в апреле 2015 года было объявлено о Минусинске, большая часть освещения этой темы интерпретировала обновление как «обратные ссылки Яндекса на алгоритм». По сути, Минусинск означает, что пока ссылки возвращаются по коммерческим запросам в Московской области, Яндекс продолжает работу по искоренению черного SEO, а не просто возвращается к прежнему алгоритму взвешивания ссылок. Минусинское обновление наказало покупку платных ссылок, создав отрицательный капитал для этих типов ссылок.
Чтобы лучше прояснить детали Минусинска, я взял интервью у руководителя поисковой службы Яндекса Александра Садовского о состоянии поисковой оптимизации Яндекса.
Как Яндекс классифицирует ссылки?
Яндекс классифицирует естественные ссылки как положительные, а платные — как отрицательные. 74% ссылок, которые мы видим на российском рынке, являются платными ссылками, приобретаемыми с целью улучшения позиций в поисковой выдаче, а не для улучшения пользовательского опыта.
Как определить разницу между ними?
Наш алгоритм машинного обучения определяет, какие ссылки являются естественными, а какие платными. Мы берем примеры ссылок, которые считаются естественными, и ссылки, которые считаются платными, и используем их в качестве образцов, на которых наш алгоритм может учиться. Затем алгоритм строит модель для классификации ссылок как естественных или платных.
При просеивании ссылок алгоритм обучения фильтрует большое количество факторов, которые в конечном итоге определяют, является ли ссылка естественной или платной. Поскольку у нас есть большой набор примеров ссылок, из которых извлекается наш алгоритм, точность нашего алгоритма довольно высока. По нашему опыту более 99% ссылок классифицируются правильно.
Как Яндекс относится к платным ссылкам? В каких вертикалях и регионах?
В Минусинске будут штрафовать тех, кто покупает платные ссылки. Среди других элементов, два основных фактора способствуют наказанию веб-сайта: процент платных ссылок, ведущих на сайт, и абсолютное количество входящих ссылок на сайт. Сочетание этих двух факторов будет определять, насколько сильно будут затронуты веб-сайты.
Это будет применяться ко всем веб-сайтам, во всех регионах, для всех поисковых запросов. Яндекс не только проиндексирует сайты с платными ссылками, но и создаст обширную базу платных ссылок.
Как Яндекс обрабатывает естественные ссылки?
Естественные ссылки не обязательно являются положительным фактором для ранжирования, а скорее уравновешивающим фактором для веб-сайтов с платными ссылками. Веб-сайт без естественных ссылок будет наказан в зависимости от количества и процента платных ссылок по сравнению с естественными ссылками. Высокий процент естественных ссылок может предотвратить понижение данного сайта в поисковой выдаче.
Например, если небольшой веб-сайт с очень небольшим количеством ссылок имеет 66% платных ссылок и 33% естественных ссылок, это не повлияет на это из-за низкого абсолютного количества платных ссылок. На противоположном конце спектра, когда есть хорошо зарекомендовавший себя авторитетный сайт с 10 000 платных ссылок, но 100 000 естественных ссылок, он также не будет наказан, потому что процент платных ссылок низок.
Первый этап наказаний касается платных ссылок, которые веб-мастера купили или арендовали на несколько лет. Естественные ссылки и ссылки, направляемые другими веб-мастерами, не имеют такого значительного веса.
Почему Яндекс внес эти коррективы в свой алгоритм?
Десять месяцев назад было решено, что ссылки больше не будут фактором ранжирования для значительной части московских коммерческих запросов. Цель этого решения заключалась в том, чтобы побудить веб-мастеров уделять больше внимания улучшению пользовательского опыта своих веб-сайтов и сокращению покупки ссылок.
За этот период покупка ссылок снизилась на 14%, что было намного медленнее, чем мы ожидали. Из-за того, что веб-мастера поддерживали платные ссылки для ранжирования в других поисковых системах и, как правило, просто следовали своим привычкам покупать ссылки, черная шляпа SEO в России сохранилась.
Для дальнейшего решения этой проблемы имело смысл снова ввести ссылки в качестве фактора ранжирования коммерческих запросов. Путем наказания веб-сайтов с платными ссылками количество платных ссылок должно быть значительно сокращено, а веб-мастера должны сосредоточиться на улучшении контента, пользовательских интерфейсов и т. д.
Какой процент сайтов, по вашему мнению, будет затронут?
Каждый веб-сайт может быть оштрафован. Не зная, какие веб-сайты будут соответствующим образом корректироваться, мы не можем точно знать, сколько из них. Я могу с уверенностью сказать, что сначала будут затронуты тысячи веб-сайтов, и мы готовы увеличить количество оштрафованных сайтов по мере того, как это будет продолжаться.
Как Яндекс внедряет эти изменения?
Изменения будут внедряться постепенно. 15 мая 2015 г. ознаменовался первым этапом штрафных санкций для веб-сайтов. Первый раунд затронул сотни веб-сайтов, которые наиболее вопиющим образом не очистили большую часть своих платных ссылок. Позже будет затронут второй раунд из 1000 веб-сайтов и так далее.
В течение какого времени сканеры индексируют изменения?
Веб-сайты с высоким авторитетом могут быть проиндексированы несколько раз в день. Веб-сайты с низким авторитетом и те, которые, как правило, имеют много платных ссылок, с большей вероятностью будут индексироваться примерно раз в неделю. Поэтому рекомендуется как можно скорее очистить платные ссылки.
Что могут сделать издатели для защиты своих веб-сайтов?
Яндекс.Вебмастер разослал уведомления сайтам, которые были идентифицированы как сайты, на которые может негативно повлиять развертывание Минусинска. У этих сайтов был месяц, чтобы внести соответствующие коррективы в свои веб-сайты.
Как правило, веб-мастерам приходится договариваться, чтобы получить платные ссылки со своих сайтов. Большинство ссылок в России покупаются через нескольких конкретных брокеров ссылок. Если веб-мастера перестанут арендовать или покупать, то большая часть проблем со ссылками прекратится.
Рунет После Минусинска
Интервью с Садовским помогло выяснить, насколько платные ссылки могут существенно влиять на позиции сайта в результатах поиска Яндекса по всем вертикалям и во всех регионах. После первого раунда санкций Минусинска на прошлой неделе многие веб-мастера узнали, что обновленный алгоритм действительно повлиял на ряд сайтов в различных вертикалях по всей России, независимо от силы их домена. Были затронуты как домены, так и субдомены, что привело к заметному падению рейтинга. Несколько сайтов, избавившихся от платных ссылок, не проявили достаточно агрессивности в своем подходе и все же ощутили влияние Минусинска.
Яндекс.Вебмастер подвел итоги поздно вечером 21 мая по московскому времени. Месяц назад, когда был анонсирован Минусинск, Яндекс.Вебмастер разослал вебмастерам 8890 уведомлений о том, что они должны заняться платными ссылками на своих сайтах. По данным Яндекса, 37% из этих выявленных сайтов отреагировали соответствующим образом, и новый алгоритм их не затронул. Первая партия минусинских «победителей» была отобрана из оставшихся 63% сайтов, которые вообще не обращались к своим платным ссылкам или достаточно агрессивно. 488 веб-сайтов были оштрафованы. Пострадавшие сайты потеряли в среднем 20 позиций в поисковой выдаче.
Чтобы лучше показать, как алгоритм влияет на посещаемость веб-сайта, Яндекс.Вебмастер предоставил скриншоты статистики двух разных сайтов в Яндекс.Метрике, бесплатном инструменте веб-аналитики Яндекса. На первых снимках экрана ниже показан трафик за период в три с половиной недели, а также источники трафика из Google и Яндекса.
С другой стороны, сайт, который не очистил свои платные ссылки, увидел падение своего Яндекс-трафика и общее сокращение посещений сайта.
Яндекс считает первый раунд Минусинска успешным в окончательном достижении цели искоренения черного SEO. Доля самых активных покупателей платных ссылок уменьшилась на 12,5%. В целом доля платных ссылок в базе данных Яндекса упала на 21,7%. Следующий этап штрафных санкций будет проводиться без предупреждения. Веб-мастера, которым уже посоветовали очистить платные ссылки, должны принять меры, чтобы их веб-сайт не подвергся штрафным санкциям при следующем развертывании Минусинска.