Содержание
Как работают текстовые факторы ранжирования в алгоритмах поиска Яндекс и Google? – статьи про интернет-маркетинг
Последнее обновление: 23 сентября 2021 года
6429
Независимый SEO-эксперт Алексей Чекушин, создатель just-magic.org, рассмотрел данную тему на нашей конференции Оptimization 2019. Об изменениях, которые произошли с тех пор, вы сможете узнать на конференции Оptimization 2020.
Время прочтения: 8 минут
Тэги: Optimization, SEO, факторы ранжирования
О чем статья?
-
Нейросети развиваются и приближаются к Natural Language Processing (NLP, «обработка естественного языка»). Но пока мы еще только двигаемся к пониманию текста поиском. -
Чтобы написать хороший seo-текст, нужно понимать, в каком направлении развиваются текстовые факторы и насколько быстро, а также в чем различие классических текстовых факторов и их нового поколения.
-
Алгоритм Яндекса Палех/Королев и модель Google BERT меняют требования к работе с ключевыми и релевантными словам.

Классические и new-gen факторы ранжирования
Рекомендации представителей поисковых систем можно свести к двум утверждениям: пишите тексты для пользователя и не делайте SЕО-тексты. Это было бы на 100% верно, если бы мы с вами жили в гипотетическом мире, где уже развита NLP. Пока такие заявления опережают время лет на 5-10.
Сегодня мы рассмотрим классические и new-gen текстовые факторы. Это независимые друг от друга величины. Хорошие классические текстовые факторы никак не влияют на new-gen и наоборот. Для понимания, какой информацией оперирует поиск, можно использовать распространенные в сети формулы TF-IDF, ВМ25, вариации на тему ВМ25 с машиноподобранными весами и так далее. Мы сегодня обойдемся без них. Статистику по факторам ранжирования можно посмотреть в нашем исследовании.
Классические текстовые факторы — модель «мешок слов»
Представьте: мы взяли текст, вытряхнули из него все слова, сложили в мешок, встряхнули и пересчитали. То есть на этапе сбора информации модель уничтожает всю информацию о самом тексте, его связность, и получает просто набор слов. При этом теряется:
То есть на этапе сбора информации модель уничтожает всю информацию о самом тексте, его связность, и получает просто набор слов. При этом теряется:
Рассмотрим правило «мешка слов» на примере предложения: «Это щенок и он очень мил».
Конечно, можно использовать синонимы, но это очень маленькое расширение, к тому криво работающее. Попробуйте задать в поиске Яндекса запросы «мобильный телефон» и «сотовый телефон». Вы увидите, что даже такие примитивные синонимы могут оказаться не взаимными.
Поможем запустить новый продукт
Хотите сформировать позитивное восприятие нового продукта и не допустить стихийного всплеска негатива? Напишите нам — мы проанализируем слабые и сильные стороны вашего продукта, поможем выстроить правильный информационный фон и повысить узнаваемость!
Как работать с классическими текстовыми факторами при новых алгоритмах?
Раньше принцип работы был очень прост: спамь ключевыми словами как можно больше, число ограничивалось только антиспамом. Затем появилось машинное обучение, и возникла необходимость укладываться в некие диапазоны вхождений. Сделаем больше слов — потеряем в ранжировании, сделаем совсем много – попадем под антиспам.
Затем появилось машинное обучение, и возникла необходимость укладываться в некие диапазоны вхождений. Сделаем больше слов — потеряем в ранжировании, сделаем совсем много – попадем под антиспам.
«В высококонкурентной тематике без классических текстовых факторов не обойтись. С появлением алгоритма Палех/Королев стало больше работы, так как уровней информации для учета стало больше»
Размер диапазона непонятен SEO-специалисту, если он раньше с этим запросом не работал. Попытки технического угадывания приводят к большой дисперсии (разнообразию) результатов в выдаче. Плюс на результат влияют и другие факторы, большинство которых мы отсечь не можем. Не стоит уповать на операторы типа intext — они давно перестали работать.
Поэтому мы используем старый добрый текстовый анализ, адаптируя его под новые условия.
- Менее важно точно затачивать страницы по вхождениям. Задача «примерно туда попасть», а сколько это «примерно» — определяется по текстовому анализатору. Даже самые опытные SEOшники на «глаз» угадывают хуже, чем текстовые анализаторы, с точки зрения последующего ранжирования.
 Задача «примерно туда попасть», а сколько это «примерно» — определяется по текстовому анализатору. Даже самые опытные SEOшники на «глаз» угадывают хуже, чем текстовые анализаторы, с точки зрения последующего ранжирования.
Задача «примерно туда попасть», а сколько это «примерно» — определяется по текстовому анализатору. Даже самые опытные SEOшники на «глаз» угадывают хуже, чем текстовые анализаторы, с точки зрения последующего ранжирования.
- Важен отбор запросов для анализа из группы. В Палех/Королев немного изменились правила группировок, а это очень важная часть ранжирования в Яндексе.
- Оптимизироваться может не только текст. Раньше везде, в том числе в интернет-магазинах, мы были вынуждены делать тексты. Теперь мы можем оперировать не только текстам
New-gen текстовые факторы: модель DSSM
Здесь рассмотрим алгоритм Яндекса Палех/Королев, который действует с зимы 2018/2019 года. Это один и тот же алгоритм, который работает с разными зонами. Для него использовалась предложенная Microsoft модель DSSM (deep structured semantic model). Эта модель оперирует следующими параметрами: буквенные триграммы, слова и биграммы (пары слов). В итоге:
В итоге:
-
В оценку идут все слова, а не только содержащиеся в запросе. Если модель «мешок слов» 97% слов просто выбрасывала, теперь оценивается все. Несмотря на то, что потеряна основная структура текста, немного остается в биграммах. Таким образом, используется значительно больше данных. -
Модель натренирована на вхождения НЕ слов и биграмм запроса. Нейросеть специально обучали для того, чтобы она не искала классические текстовые факторы, а дополняла их. -
Анализируется «важный» контент страницы (алгоритм Королев). Правда, какая часть контента считается важной, пока известно только Яндексу, точнее, его нейросетям.
В любом случае, мы теперь теряем не два уровня информации, а только один — о расположении слов. Это шаг на пути к NLP.
Влияние DSSM на СЕО
Сейчас уже до 40% всех запросов уникальны, то есть не повторяются хотя бы дважды в течение всего периода наблюдений. В итоге, если ввести в поиск какой-либо рандомный невысокочастотный запрос, мы можем увидеть некие паттерны в title и текстах. Их можно выделять визуально либо автоматически и использовать для дополнительной технической текстовой оптимизации.
В итоге, если ввести в поиск какой-либо рандомный невысокочастотный запрос, мы можем увидеть некие паттерны в title и текстах. Их можно выделять визуально либо автоматически и использовать для дополнительной технической текстовой оптимизации.
Были случаи, когда добавление одного слова в title, причем слова не из запроса и не являющегося синонимом, вытаскивало текст из топ 15 в топ 3. Можно предположить, что при очередном переобучении достоверность фактора возросла, соответственно, возросла его значимость в общей формуле. Вот тут можно посмотреть успешный кейс по поднятию поискового трафика и конверсии за счет текстовой оптимизации.
«Использование биграмм и паттернов формирует положительное ранжирование. Статистически значимым оказывается добавление этих слов в title, тексты и другой контент страницы»
Существуют разные методики автоматического выделения. Из выдачи по соответствующему запросу выделяются определенные текстовые паттерны, используя алгоритмы, определяющие тематическую близость. Поиск оценивает не только текст. Оценивается и дополняющий его контент.
Поиск оценивает не только текст. Оценивается и дополняющий его контент.
Например, в интернет-магазинах есть представление, буквально созданное для размещения всяких биграмм Королева. Нельзя гарантировать, что оно работает, так как никто не знает, какие конкретно зоны выделятся Королевым. Однако в реальности добавление слов, не содержащихся в запросе, но соответствующих ему по тематике, улучшает ранжирование.
Новая работа с группировками
Кто работал с продвижением под Яндексом, знает, что группировка запросов — самый важный этап. Если сделана ошибка в группировке, то дальше можно не оптимизировать — ничего не поможет.
Теперь предпочтительно делать так:
-
Меньше одинаковых слов в запросах. Посмотрите на пример на картинке. Только слово «зимняя» эти запросы и объединяет. Раньше такого большого разброса в конкурентных тематиках не было.
-
Большие кластеры, больше низкочастотных запросов на страницы. -
Гораздо сложнее деоптимизировать страницу. Раньше, если запрос вел «не туда», вы убирали ключевые слова с оптимизированной страницы. Теперь, поскольку ранжируются не только ключевые слова, убрать страницу из поиска по запросу стало трудно. Иногда проще смириться и оставить ее Яндексу так, как он считает нужным.

Модель BERT от Google — следующий шаг к NLP
BERT (Bidirectional Encoder Representations from Transformers) — алгоритм Google, который был анонсирован в 2018 году и запущен в октябре 2019. На тот момент он работал только с английским языком и обрабатывал 10% запросов. БЕРТ является следующим этапом развития нейросетей по сравнению с Палехом/Королевым.
В чем его основные отличия и применение?
-
Bidirectional означает, что алгоритм «читает» текст как слева направо, так и справа налево. То есть он использует даже больше информации, чем человек.
-
Обучение его строится на простом принципе маскирования. Берут текст, закрывают одно слово, и модель пытается по контексту «угадать» слово, которое там заложено. - За счет этого BERT имеет большое число применений. Если Палех/Королев просто ищут соответствие запросу, то BERT может искать ответ на вопрос (Q/A). То есть, если задать вопрос, то алгоритм из куска текста, в котором содержится этот вопрос, вытащит ответ. Также он способен проверять гипотезу: мы можем сформулировать гипотезу, задать ответ, а BERT скажет, да или нет.
 То есть он использует даже больше информации, чем человек.
То есть он использует даже больше информации, чем человек.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации «Ашманов и партнеры»:
«Не сказать, что BERT существенно изменил работу наших SEO-специалистов с текстом: мы и раньше советовали писать человекопонятные тексты для пользователей, и дальше планируем придерживаться этого подхода. Ни о каких накрутках и перенасыщении ключами уже давно речи не идет (во всяком случае, наши специалисты давно к этому пришли. И, как подтверждают результаты – не зря). Определяйте интенты согласно группировке запросов, работайте со смыслом и структурой текста, пользуйтесь данными поисковых подсказок и синонимами».
Ни о каких накрутках и перенасыщении ключами уже давно речи не идет (во всяком случае, наши специалисты давно к этому пришли. И, как подтверждают результаты – не зря). Определяйте интенты согласно группировке запросов, работайте со смыслом и структурой текста, пользуйтесь данными поисковых подсказок и синонимами».
BERT использует еще больше данных, чем Палех/Королев. Он учитывает не только все слова, не содержащиеся в запросе, он учитывает и информацию о расположении слов. Тем не менее, говорить о понимании поиском текста пока рано. Так, для решения задачи Q/A мы даем алгоритму кусок текста, в котором этот ответ содержится. Тогда он, с высокой вероятностью, может выделить запрос. Но сам найти ответ в интернете пока не может.
Блиц-интервью с Алексеем Чекушиным
— Как быстро поисковики обсчитывают все текстовые фичи?
Всё считается довольно быстро. Обучение нейросети происходит заранее, так что прогон текста — достаточно быстрое вычисление. В отношении Яндекса, когда вы видите, что ваш результат обновился в поиске, значит, все значимые факторы, кроме тех, что требуют накопления во времени, по нему уже посчитаны. Другой вопрос, учтены ли они, тут может быть небольшая разница между предварительным ранжированием и основным. Что касается Google, возможно, есть небольшая задержка в 15-30 минут. В любом случае, счет не идет на дни или месяцы.
В отношении Яндекса, когда вы видите, что ваш результат обновился в поиске, значит, все значимые факторы, кроме тех, что требуют накопления во времени, по нему уже посчитаны. Другой вопрос, учтены ли они, тут может быть небольшая разница между предварительным ранжированием и основным. Что касается Google, возможно, есть небольшая задержка в 15-30 минут. В любом случае, счет не идет на дни или месяцы.
— Какие кластеризаторы можно порекомендовать SEO-специалисту?
Практически все они работают по одной схеме. Их работа сводится к анализу того, что есть в топе, без глубокого анализа, насколько оно связано с самим запросом. Можно выбрать тот, с которым вам удобнее работать.
— Как оптимизировать под BERT?
На момент создания доклада это было неизвестно. Скорее всего, какой-то опыт уже будет озвучен на Оptimization 2020.
Выводы:
-
Говорить о понимании текста поиском пока рано. Модель BERT — еще один шаг в этом направлении, в ближайшее время увидим, насколько он успешный.
-
Работая над оптимизацией, следует использовать больше слов, не входящих в запрос, но соответствующих тематике. Биграммы и поисковые паттерны могут быть успешны как в title, так и на других уровнях текста. -
Особое значение приобретает группировка запросов. Оптимизировать следует не только контент, но и другие ниши для вхождения. -
Если раньше текст оценивался по одному параметру, то новые модели учитывают все больше уровней информации, в том числе – поведенческие факторы.
 Модель BERT — еще один шаг в этом направлении, в ближайшее время увидим, насколько он успешный.
Модель BERT — еще один шаг в этом направлении, в ближайшее время увидим, насколько он успешный.
Статья
Изменения в Яндексе на 2022 год: новые метрики качества
#SEO, #Optimization
Статья
Барри Шварц: «Google Page Experience вряд ли повлияют на ранжирование, но внедрить их стоит». Главное из интервью
Главное из интервью
#SEO, #Optimization
Статья
Как получить максимальный эффект от SEO-продвижения? Совмещаем цели бизнеса и подрядчика
#SEO, #Optimization
Статью подготовила Татьяна Минина. Профессиональный журналист, копирайтер. Увлечения: журналистика, текст, SEO, спорт.
Новый фильтр Яндекса, алгоритм против некачественного бизнеса
В октябре «Яндекс» запустил новый алгоритм, который учитывает жалобы пользователей на недобросовестную деятельность бизнеса. Компании, которые получили такие жалобы, могут быть понижены в поисковой выдаче. 19 ноября в блоге «Яндекса» вышел официальный анонс.
19 ноября в блоге «Яндекса» вышел официальный анонс.
Читайте также:
Факторы ранжирования Google и «Яндекс»: что это и как работает
Новый алгоритм «Яндекса»: в чем суть
Если совсем кратко и совсем просто — «Яндекс» получает сигналы от пользователей об антикачестве и недобросовестности какого-либо сайта. Например, люди жалуются, что перевели компании X деньги за товар, а он не пришел. Или на сайте агентства Y указана одна цена за услугу контекстной рекламы, а по факту она стоит в 2 раза больше. А компания Z, которая обещала 10 уроков курса о красивой и богатой жизни, прислала только 2 письма и пропала, деньги не возвращает.
Люди всегда жаловались на недобросовестные компании. Но именно сейчас «Яндекс» стал не просто учитывать такие сигналы — он включил их в алгоритм ранжирования. То есть наряду с другими факторами ранжирования количество жалоб теперь напрямую влияет на позиции сайта в выдаче.
Вот такие сообщения получили вебмастера пострадавших сайтов
Кому полезен новый фильтр «Яндекса»
В первую очередь новшество будет полезно пользователям: снижается шанс быть обманутыми и получить некачественную услугу или товар.
Выгоден новый алгоритм и честному бизнесу. Сомнительные сайты будут понижаться в выдаче, а их место займут добросовестные компании. Клиентоориентированный бизнес укрепит свои позиции, получит больше трафика на сайт и новых клиентов.
Не попадут ли под раздачу представители честного бизнеса, которых понизят ошибочно? Каждый раз, когда выходит новый алгоритм, под него регулярно попадают нормальные сайты, просто по статистической погрешности и неотлаженности алгоритма. Или, того хуже, не станет ли новый алгоритм руководством к действию для конкурентов или недоброжелателей?
Яндекс длительное время обучал свою нейронную сеть на реальных отзывах, и по заявлениям они отлично научились понимать тональность и смысл отзывов, а также распознавать фейки от реальных. Поэтому алгоритм умеет понимать не критичные нарушения и не наказывать за них.
Поэтому алгоритм умеет понимать не критичные нарушения и не наказывать за них.
Новые правила, по уверениям Яндекса, не коснутся компаний, у которых бывают осечки в сервисе
Читайте также:
Фильтры «Яндекс»: разновидности, опасности, лечение
Дамоклов меч «Яндекса» уже навис над сайтами любой ниши, у которых много негативных отзывов от пользователей. Также эксперты говорят, что наиболее уязвимыми будут следующие ниши:
-
перепродажа лидов;
-
инфобизнес, заработок в интернете;
-
казино, ставки на спорт;
-
лечение БАДами от всех болезней, «чудодейственные» препараты.
Такие отзывы будут учитываться
Как выйти из под фильтра Яндекса?
Если сайт уже потерял позиции, «Яндекс» рекомендует изменить отношение к клиентам и работать более добросовестно. Когда пользователи начнут оставлять положительные отзывы, алгоритм это оценит, и позиции сайта начнут расти.
Когда пользователи начнут оставлять положительные отзывы, алгоритм это оценит, и позиции сайта начнут расти.
Проверьте отзывы о вашей компании на сторонних ресурсах и в Яндекс Вебмастере, постарайтесь отработать негатив. После этого попробуйте объяснить ситуацию «Платонам» Яндекса.
Всем без исключения мы советуем вовремя отрабатывать негатив, отслеживать отзывы о вашей работе на таких площадках, как «Яндекс Карты», «Отзовик», Google Карты и других. Мониторить отзывы можно и вручную, и с помощью специальных программ.
Мы в агентстве Kokoc оказываем услугу SERM: формируем, защищаем и поддерживаем репутацию компании в поисковой выдаче. Делаем это с помощью собственного инструмента SERMometer: он анализирует выдачу и составляет тепловую карту репутационного фона бренда.
Чем больше зеленых полей, тем лучше репутационный фон
Мы не просто мониторим фон репутации, но и принимаем меры: отрабатываем негатив и вытесняем его из топа, мотивируем пользователей оставлять положительные отзывы, модерируем контент на площадках.
SERM — управляем репутацией компании
Сайт
Телефон
Рейтинг Яндекс.Алгоритм (все годы)
Яндекс.Алгоритм (7 конкурсов)
Яндекс.Алгоритм 2018
Проведено
в
Санкт-Петербург и онлайн, Россия
на 20 мая 2018 г.
Победители Топ-3:
| Место | Страна | Имя |
|---|---|---|
| 1 | Беларусь | турист |
| 2 | Россия | Ум_ник |
| 3 | Россия | LHiC |
Посмотреть все результаты
Яндекс.Алгоритм 2017
Проведено
в
Москва и Онлайн, Россия
18.07.2017
Победители Топ-3:
| Место | Страна | Имя |
|---|---|---|
| 1 | Беларусь | турист |
| 2 | Швейцария | W4yneb0t |
| 3 | Япония | ранг. 58 58 |
Посмотреть все результаты
Яндекс.Алгоритм 2016
Прошел
в
Минск и Онлайн, Беларусь
на 29 июля 2016 г.
Победители Топ-3:
| Место | Страна | Имя |
|---|---|---|
| 1 | Россия | Егор |
| 2 | Швейцария | W4yneb0t |
| 3 | Япония | ранг.58 |
Посмотреть все результаты
Яндекс.Алгоритм 2015
Проведено
онлайн
на 06.08.2015
Топ-3 победителей:
| Место | Страна | Имя |
|---|---|---|
| 1 | Беларусь | турист |
| 2 | Россия | Петр |
| 3 | Россия | eatmore |
Посмотреть все результаты
Яндекс.
 Алгоритм 2014
Алгоритм 2014
Проведено
в
Берлин, Германия
на 01.08.2014
Топ-3 победителей:
| Место | Страна | Имя |
|---|---|---|
| 1 | Беларусь | турист |
| 2 | Япония | hos.lyric |
| 3 | Китай | s-quark |
Посмотреть все результаты
Яндекс.Алгоритм 2013
Проведено
в
Санкт-Петербург, Россия
на 22.08.2013
Победители Топ-3:
| Место | Страна | Имя |
|---|---|---|
| 1 | Беларусь | турист |
| 2 | Россия | eatmore |
| 3 | Тайвань | peter50216 |
Посмотреть все результаты
Яндекс.
 Алгоритм 2011
Алгоритм 2011
Проведено
в
Долгопрудный, Россия
15.07.2011
Победители Топ-3:
| Место | Страна | Имя |
|---|---|---|
| 1 | Россия | Петр |
| 2 | Украина | джульгаков |
| 3 | Япония | rng_58 |
Посмотреть все результаты
Яндекс SEO. Русская поисковая оптимизация.
Запросить цену
Уровень проникновения Интернета в России составляет поразительные 89%. И 98% этих людей используют поисковые системы хотя бы раз в месяц. Две самые популярные поисковые системы здесь, Яндекс и Google, являются одновременно двумя самыми посещаемыми сайтами в России с более чем 4 миллиардами посещений в месяц, согласно Semrush.
Излишне говорить, что наличие хорошо построенного и поддерживаемого веб-сайта необходимо, если вы хотите привлечь российскую аудиторию.
Запланировать звонок
Русский поиск имеет ряд отличительных особенностей, о которых важно знать при выходе на российский рынок.
✓
Рынок поисковых систем в России поделен между двумя конкурирующими поисковиками, что во многом нетипично для других стран. По большей части Google держит подавляющее большинство поискового трафика, но не в России. Здесь поисковый трафик делится между Яндексом и Google, причем Яндекс имеет большую долю. Это означает необходимость одновременной оптимизации вашего веб-сайта для обоих SE. Хотя общий подход схож, у движков есть некоторые существенные различия в алгоритмах, которые необходимо учитывать, если вы хотите попасть в тройку лидеров.
✓
Наиболее используемой поисковой системой в России является Яндекс, и, как мы упоминали ранее, у нее есть собственный алгоритм ранжирования. Хотя может быть заманчиво просто стремиться к рейтингу в знакомом Google, пренебрежение поисковой оптимизацией Яндекса будет означать потерю серьезного трафика. Не только потому, что у самой поисковой системы большая аудитория, но и потому, что у Яндекса есть множество популярных побочных сервисов, которые могут помочь вам охватить вашу аудиторию. SEO-оптимизация Яндекса — это не только техническая, контентная и мобильная оптимизация для этой поисковой системы, но и закрепление себя на ее сервисах.
Не только потому, что у самой поисковой системы большая аудитория, но и потому, что у Яндекса есть множество популярных побочных сервисов, которые могут помочь вам охватить вашу аудиторию. SEO-оптимизация Яндекса — это не только техническая, контентная и мобильная оптимизация для этой поисковой системы, но и закрепление себя на ее сервисах.
✓
Наконец, стоит помнить о сложности русского характера и менталитета. Русскоязычные люди не всегда открыты к новинкам, часто их доверие нужно завоевывать и заслужить. Ваш сайт может показаться вам идеальным, но если вы выйдете на российский рынок, вы будете лучше осведомлены о подходе и ценностях аудитории для успешного диалога.
Наши отраслевые решения
Путешествия и
Гостиничный бизнес
Наведите курсор, чтобы узнать больше
Любовь россиян к путешествиям известна далеко за пределами нашей страны. Среди огромного количества вариантов, из которых россияне могут выбирать, может быть сложно убедить их согласиться с вашим предложением. Хорошо структурированная SEO-кампания с проанализированной конкуренцией и оптимизированным UX поможет вам стать первым выбором россиян.
Хорошо структурированная SEO-кампания с проанализированной конкуренцией и оптимизированным UX поможет вам стать первым выбором россиян.
Запланировать звонок
Криптовалюта и блокчейн
Наведите курсор, чтобы узнать больше
Криптовалюта в России является одной из самых привлекательных ниш в глазах инвесторов здесь и в то же время находится под пристальным вниманием государства. Чтобы ваше присутствие в сети было привлекательным для потенциального клиента и при этом соответствовало законодательству, требуется особый подход со стороны компетентного специалиста, знающего местный менталитет и законодательство.
Запланировать звонок
→
Узнайте больше
об отраслях
, которые мы обслуживаем
Мы можем помочь вам начать работу над вашей стратегией SEO в России и ответить на любые ваши животрепещущие вопросы.
Вот что вы получите от нашего звонка:
✓
Узнайте больше о своей нише на российском рынке: насыщенность, правила, лучшие подходы и т. д.;
д.;
✓
Узнайте больше о русском менталитете и о том, как добиться наилучшего взаимопонимания со своей аудиторией;
✓
Получите первую оценку текущего состояния вашего сайта и его готовности к завоеванию российского рынка;
✓
Давайте обсудим наброски плана поисковой оптимизации и чего ожидать с точки зрения результата;
✓
Позвольте нам ответить на ваши вопросы о цифровом маркетинге в России и предоставить больше информации о местных особенностях и многом другом.
Запланировать звонок
Рекомендуемые клиенты
Наш рабочий процесс SEO в России
Разработка стратегии
Исследования являются основой любой стратегии SEO. Мы проанализируем ваш бизнес, целевую аудиторию, нишу и конкурентов. Мы также уделим большое внимание поисковой оптимизации на странице, удобству использования, профилю обратных ссылок и данным о трафике.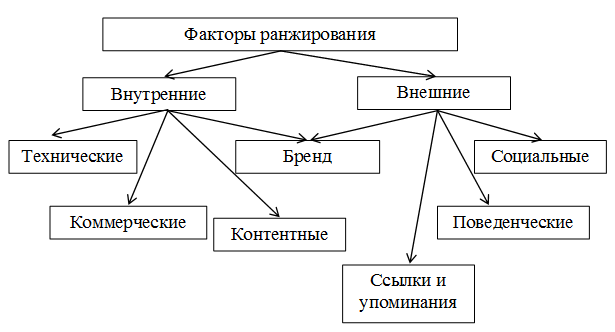 Детальный глубокий анализ вашего присутствия в сети позволит нам разработать оптимально эффективную SEO-стратегию, так как мы хорошо разбираемся в алгоритмах Яндекса.
Детальный глубокий анализ вашего присутствия в сети позволит нам разработать оптимально эффективную SEO-стратегию, так как мы хорошо разбираемся в алгоритмах Яндекса.
Исследование ключевых слов
Оптимизация страницы всегда начинается с исследования ключевых слов. В соответствии с особенностями вашей компании мы подберем наиболее эффективные ключевые слова для оптимизации, чтобы ваши клиенты могли найти ваш сайт как можно быстрее. Мы формируем максимально полный список поисковых запросов для охвата всей целевой аудитории, чтобы вы могли получить хороший объем трафика на свой ресурс.
Стратегия создания ссылок
Хорошая SEO-кампания требует внушительного количества обратных ссылок хорошего качества. Мы работаем только с релевантными ссылками из авторитетных источников, чтобы надежно улучшить ваш рейтинг в поисковой системе. Разработанная нами стратегия линкбилдинга приведет к значительному повышению рейтинга вашего сайта в поисковой выдаче и привлечению большего количества посетителей.
Создание контента
Захватывающий контент имеет большое влияние на успех SEO-кампании. Полезность и уникальность текстов на сайте всегда помогают повысить рейтинг. Грамотный контент-план также способен увеличить его конверсию. Контент должен быть написан хорошим литературным языком, легко читаться и представлять ценность для потенциальных клиентов. Поисковые системы умеют оценивать качество контента, поэтому нужно уделить этому пункту особое внимание.
Управление кампаниями
Разработка и внедрение маркетинговых планов в поисковых системах означает повышение вовлеченности аудитории, конверсий и рейтинга. Благодаря детальному погружению в бизнес клиента, мы сможем построить вам сильное онлайн-присутствие в Интернете. Первые результаты нашей кампании можно ожидать через 3-4 месяца после ее начала. Устойчивые результаты достигаются в течение нескольких месяцев непрерывной работы.
Анализ и отчетность
SEO — это долгосрочный проект, требующий постоянной и кропотливой работы с сайтом.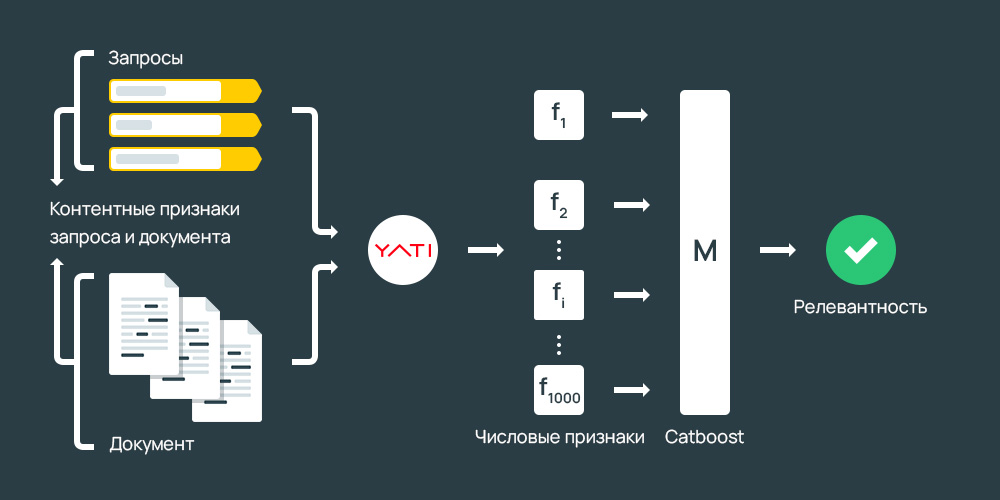 Мы предоставляем вам регулярные отчеты в качестве доказательства нашей работы. Вы будете получать ежемесячные отчеты и быть в курсе того, что происходит с вашим сайтом. Мы всегда ответим на любые ваши вопросы, связанные с SEO-стратегией!
Мы предоставляем вам регулярные отчеты в качестве доказательства нашей работы. Вы будете получать ежемесячные отчеты и быть в курсе того, что происходит с вашим сайтом. Мы всегда ответим на любые ваши вопросы, связанные с SEO-стратегией!
Причины работать с нами
Эксперты Яндекса
Сильная экспертиза Яндекса, знание SEO в России и глубокое понимание специфики русскоязычной аудитории способны помочь вам на всем пути SEO.
Англоговорящие менеджеры
Наши менеджеры говорят по-английски, чтобы обеспечить взаимопонимание. Мы не позволим языковым барьерам помешать вашему успеху.
15 лет опыта
У нас за плечами более 15 лет опыта работы в цифровом маркетинге с крупными и малыми предприятиями. Мы знаем лучшие способы привести ваш проект к успеху.
Обширный отраслевой портфель
Мы работали с широким спектром отраслей — путешествия, здравоохранение, недвижимость, ИТ, электронная коммерция, что дает нам преимущество в любой отрасли.