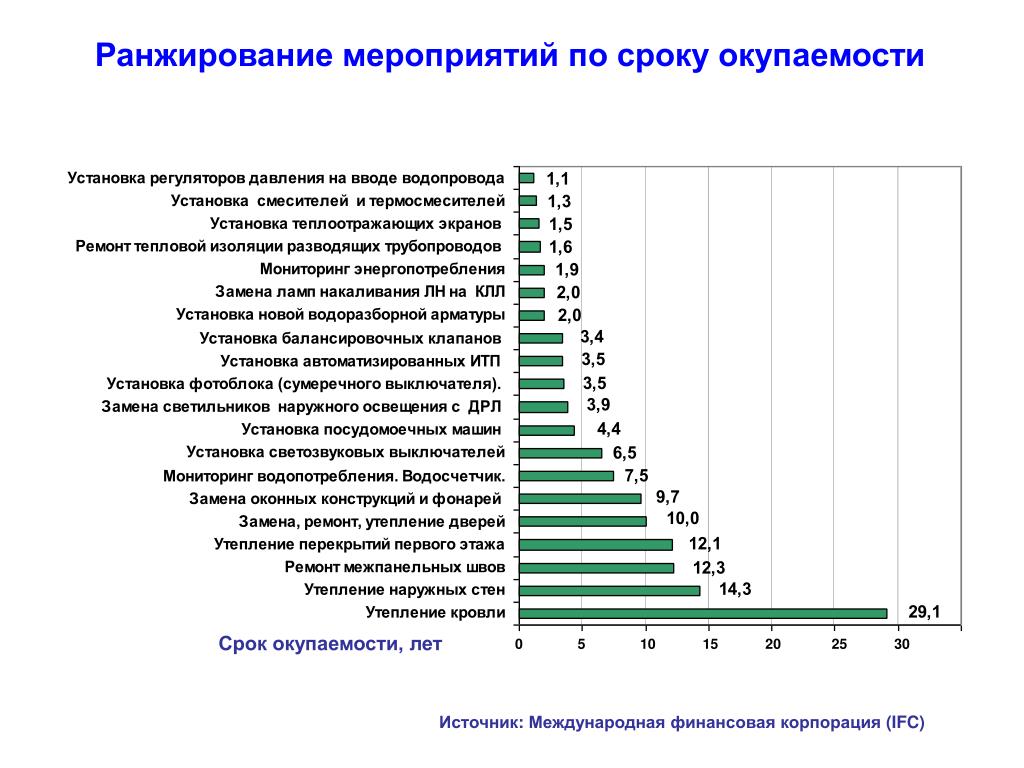
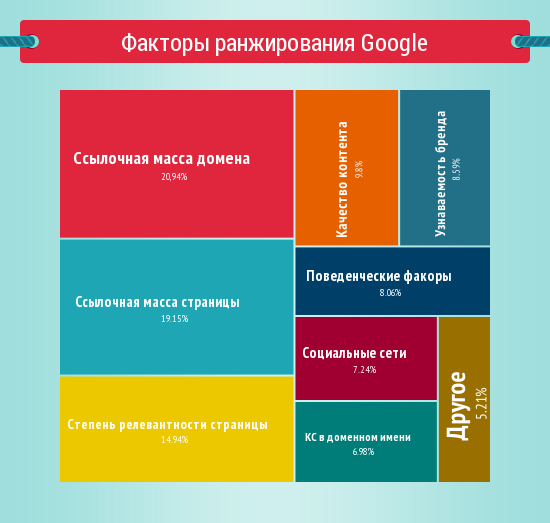
Содержание
Какие есть ссылочные факторы ранжирования?
1962
| SEO | – Читать 9 минут |
Прочитать позже
Анастасия Сотула
Редактор блога Serpstat
Сегодня ссылочные факторы ранжирования играют одну из ключевых ролей в SEO-продвижении сайтов под «Яндекс» и «Google». Без правильной внешней оптимизации, к которой относится работа со ссылками, большинство ресурсов обречено на низкую посещаемость и отсутствие хороших позиций в топах.
Если не хотите, чтобы ваш веб-сайт размещался на задворках выдачи, нужно знать, по каким критериям поисковики оценивают гиперссылки. Именно о них мы поговорим в нашем посте.
Содержание
Что такое ссылочные факторы ранжирования?
Виды внешних ссылок
Перечень основных факторов ссылочного ранжирования сайта
1. Возраст сайта
2. Количество ссылок с главных страниц
3. Скорость увеличения числа гиперссылок
4. Типы ссылок
5. Возраст гиперссылок
Возраст гиперссылок
6. Число ссылок с низкокачественных сайтов
7. Гиперссылки с атрибутом NOFOLLOW
8. Текст вокруг ссылок
9. Региональная принадлежность
Какие методы ссылочного продвижения нарушают правила Google?
FAQ
Выводы
Что такое ссылочные факторы ранжирования?
С точки зрения поисковых систем, ссылочное ранжирование — совокупность факторов для оценки ссылок с одних сайтов на другие. Точного перечня критериев не знает никто, кроме разработчиков поисковиков. Базовые же моменты хорошо известны давно. Речь идет об анкорах, весе гиперссылок, авторитетности сайтов-доноров и пр.
У начинающих вебмастеров и оптимизаторов, возможно, возникнет вопрос, зачем поисковые системы анализируют качество и количество внешних ссылок? Дело в том, что интернет изначально задумывался как среда связанных между собой документов. На гиперссылки как раз ложилась функция связующих элементов.
Ссылки — своего рода фундамент глобальной сети.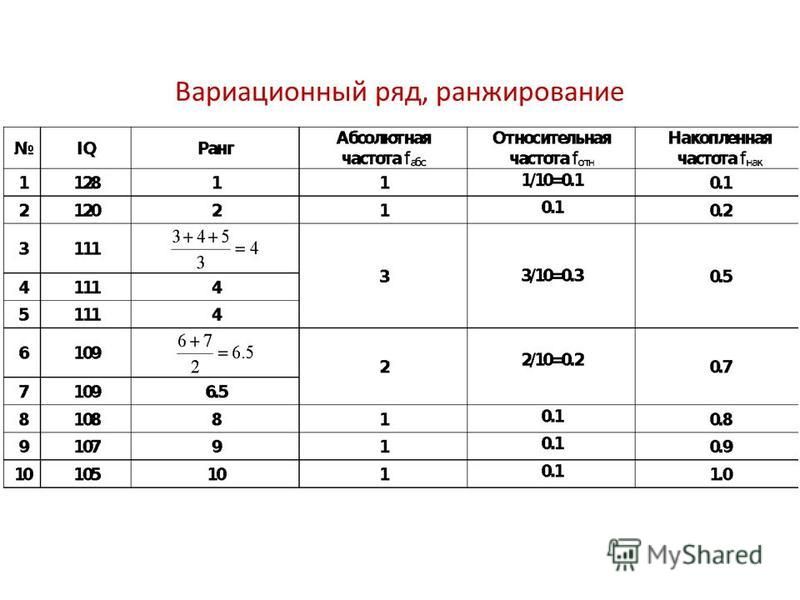 Когда начали появляться первые поисковики, их разработчики прекрасно знали о сущности гиперссылок. Потому анализ ссылочных профилей со временем лег в основу алгоритмов и факторов ранжирования сайтов поисковых систем.
Когда начали появляться первые поисковики, их разработчики прекрасно знали о сущности гиперссылок. Потому анализ ссылочных профилей со временем лег в основу алгоритмов и факторов ранжирования сайтов поисковых систем.
Еще пару десятков лет назад оптимизаторы, которые не брезговали «черным» SEO, с легкостью завоевывали топы за счет многочисленных ссылок с некачественных сайтов. Сейчас за такие действия накладываются штрафные санкции поисковых систем. Старые проекты зачастую теряют позиции, а новые не достигают топа.
Хотя поисковики грозятся перестать учитывать ссылочные факторы ранжирования, сделать это пока не получается. Зато алгоритмы оценки ссылок регулярно улучшаются. За редкими исключениями низкокачественные гиперссылки почти не работают. Без вдумчивого подбора доноров гонку за топ уже не выиграть.
Виды внешних ссылок
Принято различать 2 вида — покупные и естественные ссылки. В первом случае оптимизатор платит деньги за размещение гиперссылок на сторонних сайтах. Благодаря этому увеличивается скорость наращивания ссылочной массы и при правильном подходе повышается эффективность поисковой раскрутки.
Благодаря этому увеличивается скорость наращивания ссылочной массы и при правильном подходе повышается эффективность поисковой раскрутки.
Специалисты до сих пор спорят о моральной стороне вопроса покупки гиперссылок. После заказа ссылки на каком-либо сайте оптимизатор фактически искусственно влияет на ссылочное ранжирование, что запрещено правилами поисковиков. Правда, из-за несовершенств алгоритмов их работы часто не остается иного выбора.
Наше мнение следующее — если специалист продвигает полезные для пользователей сайты, то в покупке гиперссылок нет ничего плохого. Более того, оптимизатор помогает роботам лучше ранжировать качественные страницы. Продвижение же сомнительного контента пускай остается на совести сеошников, которые с ним работают.
Естественные гиперссылки оставляют пользователи. Последние редко заботятся об анкорах ссылок и размещают их «как есть». Постоянный рост натуральной ссылочной массы в больших объемах указывает на высокое качество сайтов. Подобные веб-ресурсы приносят огромную пользу интернет-аудитории и обычно оккупируют топы.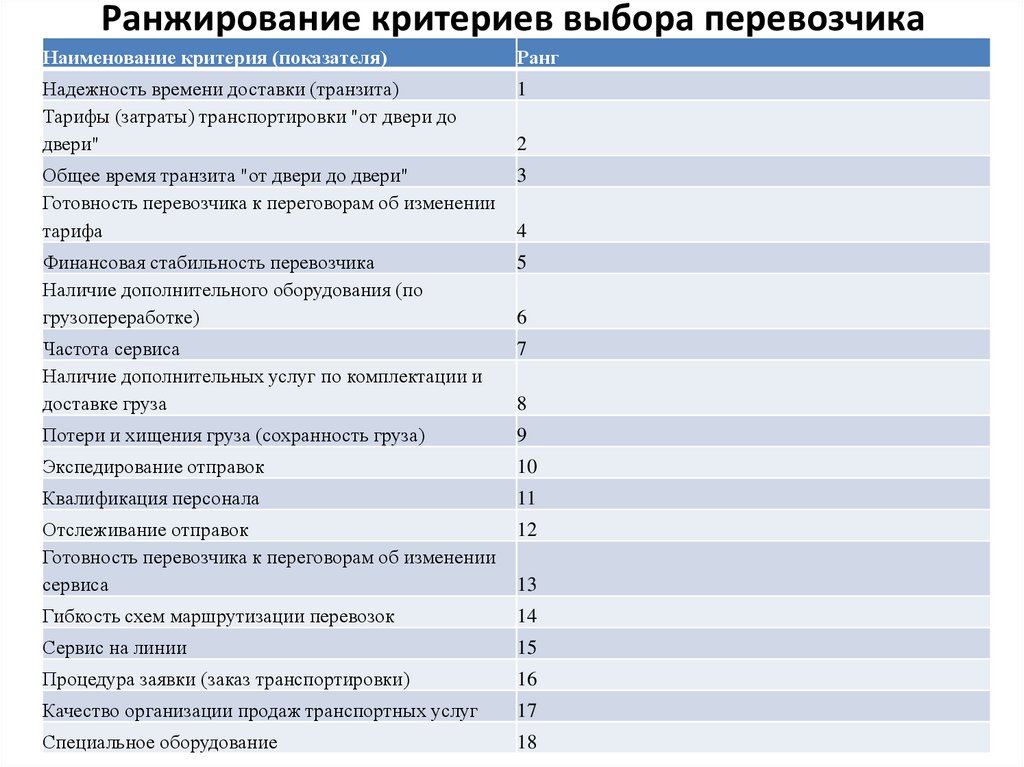
Перечень основных факторов ссылочного ранжирования сайта
Среди основных факторов, которые поисковые системы учитывают при анализе внешних ссылок, стоит выделить следующие:
1. Возраст сайта.
Правило «чем старше, тем лучше» работает не всегда. Особенно если сайт давно не обновляется, распространяет незаконный контент или не несет пользы для интернет-сообщества. Высока вероятность, что веб-сайт когда-нибудь попадет под фильтры.
2. Количество ссылок с главных страниц.
Считается, что гиперссылки с главных страниц имеют больший вес. Если рассуждать логически, мнение выглядит правдоподобным. Раз на сайт ведут ссылки с заглавных страничек веб-ресурсов, видимо, он представляет большую ценность для пользователей.
3. Скорость увеличения числа гиперссылок.
Начинающие оптимизаторы часто покупают много ссылок в короткие промежутки времени. Расчет делается на быстрый рост позиций. В результате роботы фиксируют ссылочный взрыв и накладывают санкции.
В результате роботы фиксируют ссылочный взрыв и накладывают санкции.
Резкое увеличение количества внешних ссылок не отражается на сайтах уровня Amazon или Wikipedia. Большинство новых проектов таковыми не являются. Потому ссылочную массу им надо наращивать медленно.
4. Типы ссылок.
Гиперссылки бывают в виде картинок, индексируемые и неиндексируемые, с анкорами и без них. В теории на естественно развивающиеся сайты должны вести все виды ссылок. Об этом нужно помнить в процессе планирования ссылочной стратегии.
Анализ ссылок в Serpstat
5. Возраст гиперссылок.
Чтобы ссылки просуществовали максимально долго, их надо покупать навсегда или размещать на перспективных сайтах. К ним относятся рассчитанные на длительное развитие проекты. Например, авторские блоги или новостные порталы. Подобрать качественный релевантный сайт для размещения гостевой статьи можно через специальные онлайн-биржи, например, Collaborator.
6.
 Число ссылок с низкокачественных сайтов.
Число ссылок с низкокачественных сайтов.
Есть тысячи сайтов, которые поисковики относят к низкокачественным. Нельзя сказать, что гиперссылки оттуда сильно вредят. Иначе конкуренты «топили» бы друг друга ссылочным спамом по плохим площадкам. Но и особой пользы ссылки с них не приносят.
Анализ ссылок в Serpstat
7. Гиперссылки с атрибутом NOFOLLOW.
NOFOLLOW указывает, что не следует переходить по ссылке. Гиперссылки с этим атрибутом роботами не учитываются и не влияют на позиции. Зато их наличие говорит о естественности ссылочного профиля сайта. Значит, они должны быть.
Анализ ссылок в Serpstat
8. Текст вокруг ссылок.
Поисковики анализируют как текст ссылки, так и окружающие слова, фразы или предложения. Идеально, когда контекст страницы не расходится с анкором гиперссылки. Специалисты полагают, что это положительно отражается на ранжировании.
9. Региональная принадлежность.
Немало сайтов ориентировано на конкретные регионы.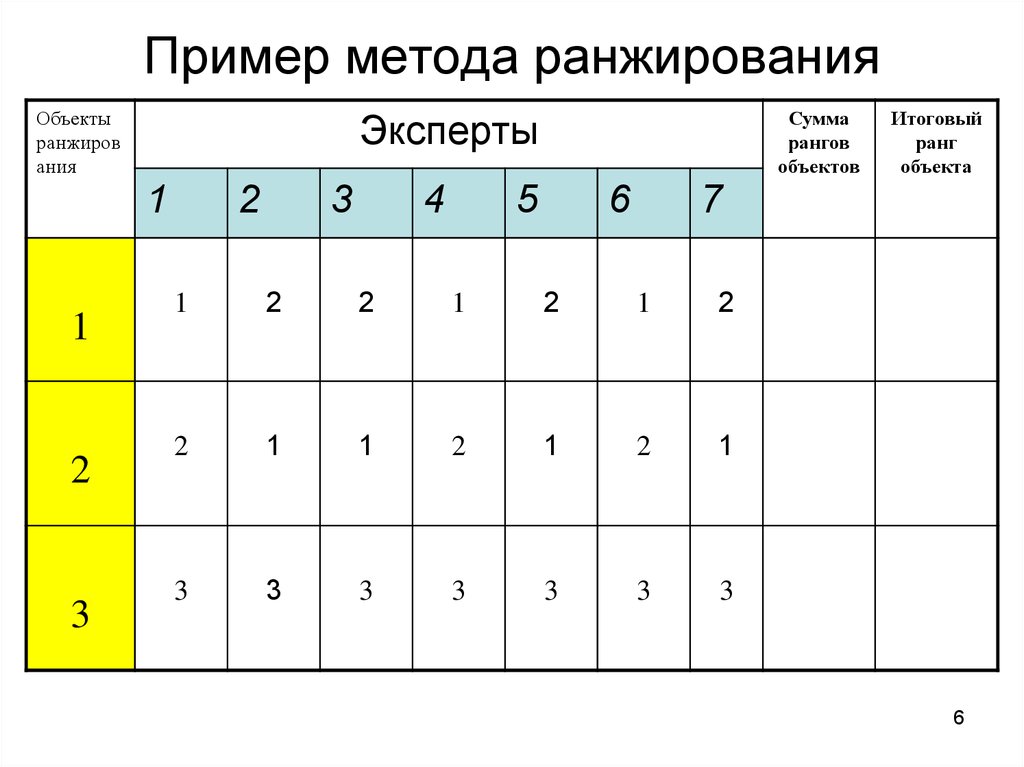 Логично, что ссылки со страниц проектов с аналогичной региональной принадлежностью должны способствовать продвижению. На практике так и происходит.
Логично, что ссылки со страниц проектов с аналогичной региональной принадлежностью должны способствовать продвижению. На практике так и происходит.
Анализ ссылок в Serpstat
Хотите узнать, как с помощью Serpstat нарастить ссылочную массу?
Нажимайте на космонавта и заказывайте бесплатную персональную демонстрацию сервиса! Наши специалисты вам все расскажут! 😉
Процесс анализа ссылочной массы из сторонних сайтов
1. Покупка ссылок.
2. Оплата гиперссылок товарами или услугами.
3. Выдача бесплатных продуктов в обмен на размещение ссылок.
4. Двухсторонний обмен гиперссылками по принципу «ты мне, я тебе».
5. Публикация статей на сторонних ресурсах с SEO-ссылками.
6. Использование автоматических программ или сервисов для размещения гиперссылок.
7. Вставка ссылок с SEO-анкорами в пресс-релизы или рекламные статьи.
8. Прогоны по низкокачественным каталогам или сайтам закладок.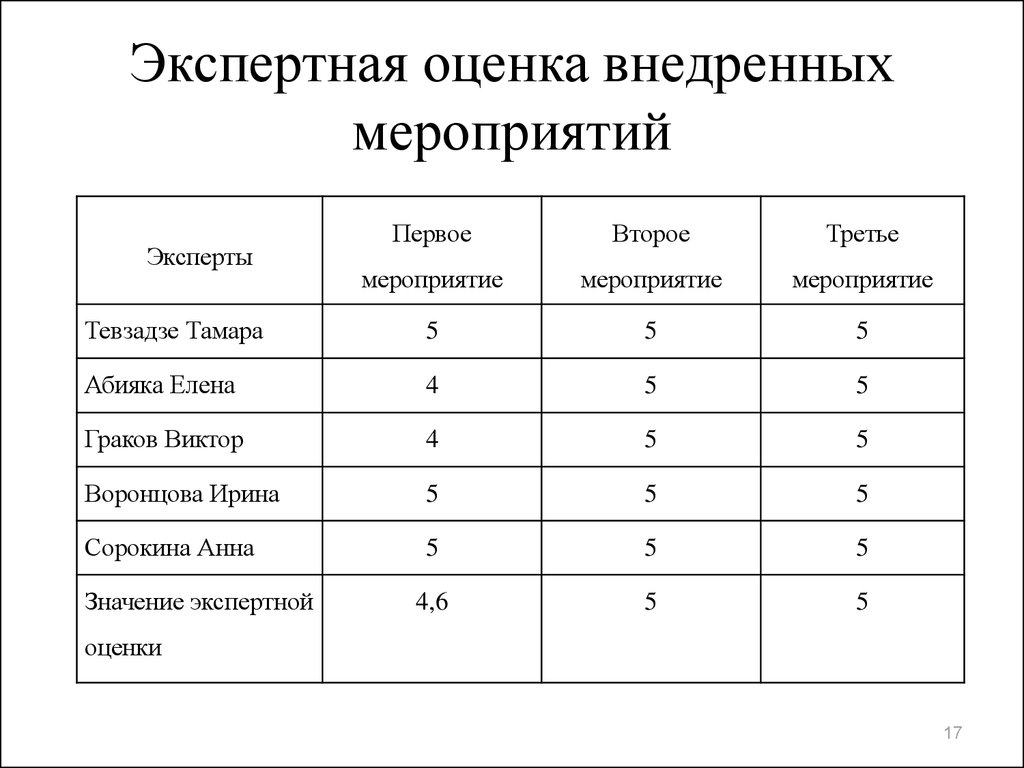
9. Скрытие ссылок в бесплатно распространяемых виджетах или плагинах CMS.
Говоря короче, Google не приемлет любые ссылки за исключением естественных. Если вы найдете хороший сайт и купите там ссылку для наращивания ссылочной массы, то нарушите правила поискового гиганта. Как быть?
Google признает, что покупка и продажа ссылок для рекламы сайтов – неотъемлемая часть интернет-экономики. Однако рекламные гиперссылки не должны влиять на результаты выдачи. Во избежание нарушений правил рекомендуется:
1. Добавлять в рекламные ссылки атрибут или.
2. После перехода по рекламным гиперссылкам направлять пользователей на закрытые от индексации страницы.
Будут ли обратные ссылки по-прежнему важны для SEO в 2022 году?
Да, но при условии правильного подбора сайтов-доноров.
Могу ли я получить трафик без обратных ссылок?
Зависит от сайта. Допустим, если создадите почтовый сервис наподобие Mail.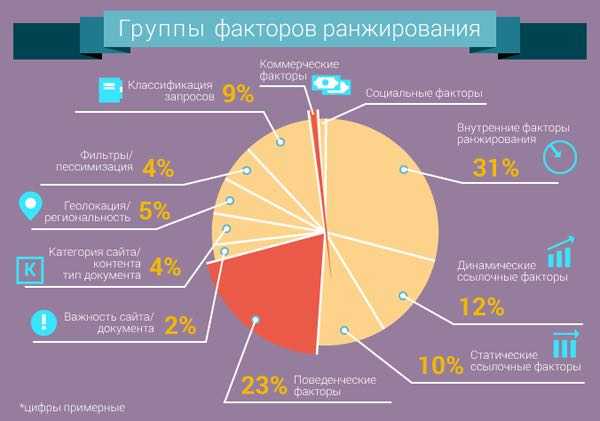 Ru и о нем быстро узнают пользователи, ссылки не понадобятся. Ссылочная масса вырастет без вашего участия. Для нового интернет-магазина или веб-сайта коммерческой фирмы, скорее всего, придется покупать гиперссылки.
Ru и о нем быстро узнают пользователи, ссылки не понадобятся. Ссылочная масса вырастет без вашего участия. Для нового интернет-магазина или веб-сайта коммерческой фирмы, скорее всего, придется покупать гиперссылки.
Хотя ссылки продолжают оставаться важным фактором ранжирования, наращивать ссылочную массу с каждым годом становится все труднее. Для отбора доноров приходится анализировать внушительные объемы информации, на что уходит много времени.
Не хотите тратить его впустую? Пользуйтесь специальными сервисами анализа гиперссылок. Яркий тому пример – инструмент «Анализ внешних ссылок» от Serpstat. Ознакомиться с его возможностями:
Чтобы быть в курсе всех новостей блога Serpstat, подписывайтесь рассылку. А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Получить бесплатный доступ на 7 дней
Мнение авторов гостевого поста может не совпадать с позицией редакции и специалистов компании Serpstat.
Оцените статью по 5-бальной шкале
5 из 5 на основе 7 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
SEO
Анастасия Сотула
Как подключить API Google Search Console
SEO +1
Юлия Дюбанова
Hard skills, инсайты и инвайты в эпоху цифровизации медицины
SEO
Анастасия Сотула
Как перенести сайт без потери позиций?
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Методическая разработка урока «Ранжирование как один из видов проектной деятельности» / Открытый урок
Аннотация
Урок по теме: «Ранжирование как один из приёмов исследовательской деятельности» проводится в 5 классе в разделе «Подготовка к защите исследовательской работы» урок №3, его роль: на основе жизненно важных проблем научить выполнять приёмы ранжирования с целью дальнейшего использования этого приёма в самостоятельной исследовательской деятельности.
Цель урока: На примере ранжирования наиболее опасных ситуаций, возникающих при несоблюдении правил дорожного движения обучить приёмам ранжирования.
Тип урока: усвоение новых знаний.
Форма организации деятельности: групповая, предусматривает общение учителя с группой учащихся, взаимодействующих как между собой, так и с учителем.
Используемые методы: пояснительно-иллюстративный с использованием мультимедийной презентации, метод проблемного изложения, практический метод усвоения новых знаний.
Особенностью данного урока является то, что это последний урок перед каникулами, поэтому выбор жизненно-необходимого материала для практической работы учащихся является актуальным. Неукоснительное соблюдение правил дорожного движения во время школьных каникул – необходимая мера сохранения здоровья учащихся. «Формирование у детей навыков безопасного поведения на дорогах» – одна из ключевых задач Федеральной целевой программы «Повышение безопасности дорожного движения в 2013–2020 годах» [2]. Находясь в обществе других людей, каждый, так или иначе, влияет на уровень безопасности окружающих, и безопасность каждого во многом зависит от уровня сформированности культуры личной безопасности конкретного человека. Перед школой стоит задача по воспитанию культуры личной безопасности, которая является компонентом общечеловеческой культуры.
Перед школой стоит задача по воспитанию культуры личной безопасности, которая является компонентом общечеловеческой культуры.
Новизна и оригинальность подхода к содержанию урока обусловлена тем, что воспитание культуры личной безопасности происходит опосредованно, ненавязчиво, через освоение знаний необходимых для проведения исследовательской работы, в соответствии с реализацией ФГОС. Благодаря этому, те опасные ситуации, которые возникают на дорогах в реальной жизни детей, предстают перед ними на учебном занятии в неожиданном освещении. Практическая работа, организованная на уроке, поможет учащимся не только освоить приём ранжирования, но и осознать, спрогнозировать свои действия в условиях участия в дорожном движении. В этом заключается практическая значимость проводимого урока. Материал урока, выбранные приёмы и методы соответствуют возрастным особенностям учащихся, способствуют развитию их коммуникативных компетенций.
Планируемые результаты:
Личностные: Вырабатывать готовность и способность обучающихся к саморазвитию и самообразованию через участие в исследовательской деятельности. Формирование осознанного и ответственного отношения к собственным поступкам, становлению гражданской ответственности, в том числе, осознанию ответственности за собственное безопасное поведение на дорогах.
Формирование осознанного и ответственного отношения к собственным поступкам, становлению гражданской ответственности, в том числе, осознанию ответственности за собственное безопасное поведение на дорогах.
Метапредметные;
формирование регулятивных УУД: Умение определять цели обучения, планировать пути их достижения, осуществлять контроль и самоконтроль, формирование способности оценивать свое поведение со стороны, формирование рефлексивных умений: предвидение возможных опасностей в реальной обстановке;
формирование познавательных УУД: умение определять понятия, выполнять целеполагание, строить логическое рассуждение, умозаключение, делать выводы, совершенствование навыка работы с информацией, использование современных источников информации, в том числе материала на электронных носителях, способность решать нестандартные задачи, представлять результаты своей работы в предложенных формах;
формирование коммуникативных УУД: Умение работать индивидуально и в группах, выполнять определенные роли, оценивать свою деятельность и деятельность членов группы. Умение использовать речевые средства в соответствии с коммуникативной задачей работы в малой группе, публичном выступлении, высказывании и обосновании своего мнения, восприятия чужого мнения.
Умение использовать речевые средства в соответствии с коммуникативной задачей работы в малой группе, публичном выступлении, высказывании и обосновании своего мнения, восприятия чужого мнения.
Предметные: на основе практико-ориентированного материала научиться приёму ранжирования, формирование теоретических знаний правил дорожного движения.
Понятия: классификация, парадокс, ранжирование
Виды использования на уроке средств ИКТ: Использование компьютерной презентации
Обеспечение: Компьютерная презентация, карточки для деления на группы, таблица ранжирования
Ход урока
|
Деятельность учителя
|
Деятельность учеников
|
Предполагаемый результат
|
|
Учитель (типичные действия, фразы диалога с обучающимися)
|
Ученики (ожидаемые действия, ответы)
|
|
|
Организационный момент
|
|
|
|
Здравствуйте, для успешной работы на уроке нам нужны тетради, пишущие средства и хорошее настроение.
|
Проверяют готовность к уроку, настраиваются на работу.
|
Регулятивные УУД: организация рабочего места.
|
|
Вхождение в тему урока, создание условий для осознанного восприятия нового материала
|
| |
|
На прошлых уроках проектной деятельности мы с вами усвоили, что для успешного написания проекта учащиеся должны уметь выполнять особые виды работы, давайте вспомним их. (Слайд 1)
|
Ответы учащихся, работа со сладом 1
|
Проверка усвоения пройденного материала, работа с понятиями: определение, классификация, парадокс, ранжирование (Познавательные УУД)
|
|
Давайте потренируемся в создании классификаций, проверка д.
|
Учащиеся отвечают, по какому признаку разделили на классы слова на букву «К» из русского языка, одной из «безусловных» классификаций будет являться: прилагательные 3 слова, 1 слово – существительное.
|
Проверка усвоения пройденного материала, работа над смысловым значением понятия «классификация» (Познавательные УУД)
|
|
Сегодня для урока нам нужно разделиться на группы. Попробуйте создать безусловную классификацию, чтобы разделить класс поровну на 5 групп.
|
Предложение учащихся, ответы учащихся.
|
Проверка усвоения пройденного материала, работа над смысловым значением понятия «классификация» (Познавательные УУД), формирование коммуникативных УУД: организация взаимодействия в группе
|
|
Целеполагание
|
| |
|
На пр. загорелся значок, и я попрошу вас сформулировать тему нашего урока. (возврат на слайд 1)
|
Ответы учащихся: будем учиться ранжированию, так как рядом с этим понятием зажёгся зелёный цвет.
Ответы учащихся о необходимости соблюдать правила дорожного движения.
|
Формирование познавательных УУД: выполнять целеполагание
|
|
Организация и самоорганизация учащихся в ходе дальнейшего усвоения материала
|
| |
|
Прочитайте выдержки из информации, которую я нашла на официальном сайте ГБДД Свердловской области [1] (слайд 3)
|
Самостоятельное чтение информации, оценочные суждения.
|
Познавательные УУД: работа с информацией на электронном носителе, развитие читательских компетенций
|
|
Попробуем разобраться, что мы делаем на дороге не так, назовите наиболее опасные ситуации, когда дети могут стать виновниками ДТП.
|
Коллективное обсуждение, представление ответов участниками группы под №2
|
формирование коммуникативных УУД, формирование теоретических знаний правил дорожного движения
|
|
Вы хорошо поработали, показали хорошее знание ПДД, назвав наиболее опасные ситуации, которые могут возникнуть на дороге. По статистике, примерно три четверти всех ДТП с участием детей происходит в результате их непродуманных действий в различных ситуациях. Среди таких ситуаций наиболее опасными являются: (слайд5)
|
Просмотр ситуаций на презентации, краткое обсуждение.
|
формирование теоретических знаний правил дорожного движения
|
|
Открытие учащимися новых знаний
|
| |
|
Сейчас вы должны обдумать и каждый самостоятельно расставить в свою колонку цифры от 1 до 5: самую опасную ситуацию поставить на 1 место, менее опасную на 2, еще менее опасную на 3 и так до последнего 5 места. Напоминаю, что каждый работает самостоятельно (слайд11, опорные таблицы)
|
Самостоятельная работа учащихся.
|
Работа согласно установленным правилам (комм. УУД)
|
|
Скажите, какой вид работы из перечисленных на слайде 1 вы сейчас выполняли? Какие ключевые слова вам помогли догадаться? В чём смысл ранжирования?
|
Ответы учащихся: Ранжирование, ключевые слова: возрастание или убывание свойств.
|
формирование познавательных УУД: умение делать выводы, работа с определениями, самостоятельное открытие новых знаний
|
|
Приём «ранжирование» вам очень поможет, когда вы будете проводить опросы и анкетирование, очень важно учитывать мнение не только одного человека, но и группы людей. Ведь у каждого свое мнение, как быть? Сейчас мы научимся ранжировать мнение не одного человека, а группы людей. Внимание, участник группы №3 подсчитает числа в каждой строке таблицы и выставит «ранг» ситуации в крайнем столбике. Сделайте вывод, о том, что вы сейчас делали.
|
Подсчёт баллов, присвоение «ранга» каждой ситуации. Вывод: можно «ранжировать» мнение группы людей.
|
Усвоение приёма ранжирования (предметный результат), развитие познавательных УУД, развитие регулятивных УУД: планирование дальнейших действий, взаимодействие в группах, согласно назначенным ролям
|
|
А сейчас мы «проранжируем» мнение всего класса, для этого участники №4 запишут результаты ранжирования в группе на доске, Как вы думаете, что нужно сделать дальше?
|
Выполнение задания.
|
развитие познавательных УУД, регулятивных УУД: планирование дальнейших действий, взаимодействие в группах, согласно назначенным ролям
|
|
Для чего нужно уметь ранжировать различные мнения, ситуации, предметы?
|
Ответы учащихся: чтобы узнать, мнение о важности чего-либо в общем, общее мнение о чём-то.
|
развитие познавательных УУД: строить логическое рассуждение, умозаключение, делать выводы, работа с информацией,
Личностные результаты: Формирование осознанного и ответственного отношения к собственным поступкам, становлению гражданской ответственности, в том числе, осознанию ответственности за собственное безопасное поведение на дорогах.
|
|
Рефлексия
|
| |
|
Давайте подведём итоги урока. С каким приёмом исследовательской деятельности вы сегодня работали? Для чего нужно уметь выполнять ранжирование? А изменилось ли ваше отношение к выполнению ПДД? Оцените работу своей команды, поставив на обратной стороне своей таблицы один из соответствующих работе значков (слайд13):
|
Ответы учащихся: прием исследовательской деятельности – ранжирование. Ранжирование определяет значимость чего-то, расставляет все по порядку, «рангу».
|
Регулятивные УУД: взаимодействие в группе, оценка и самооценка деятельности.
|
 з.
з.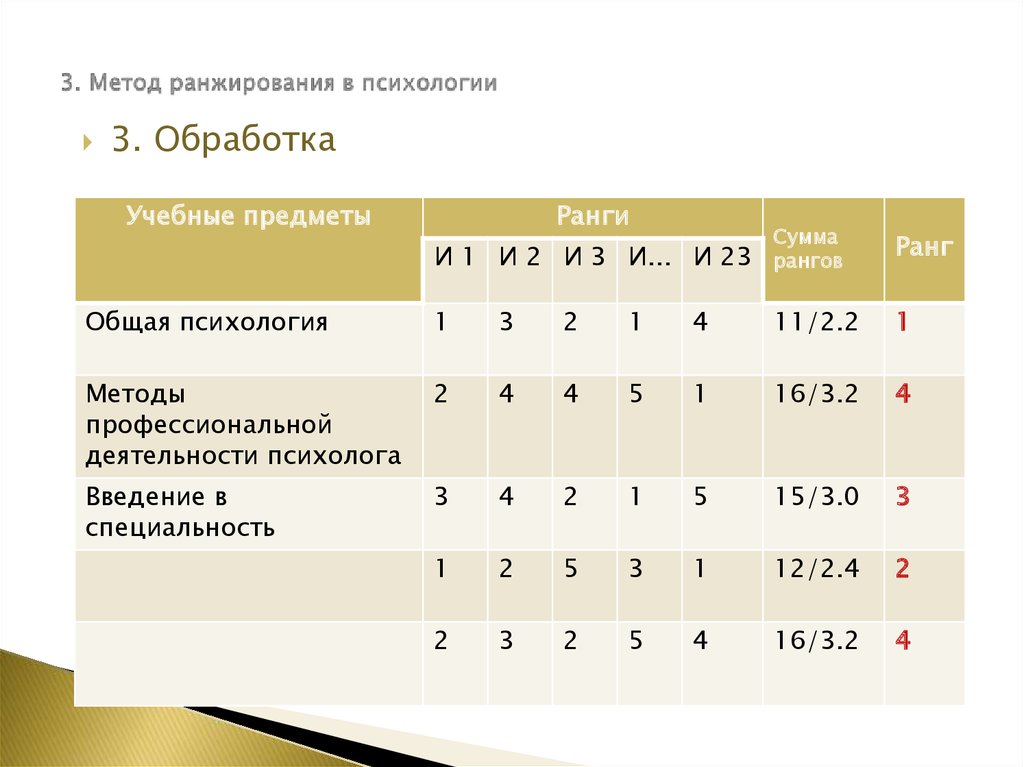 Деление по принципу, предложенному учителем «по 5 человек в алфавитном порядке»
Деление по принципу, предложенному учителем «по 5 человек в алфавитном порядке»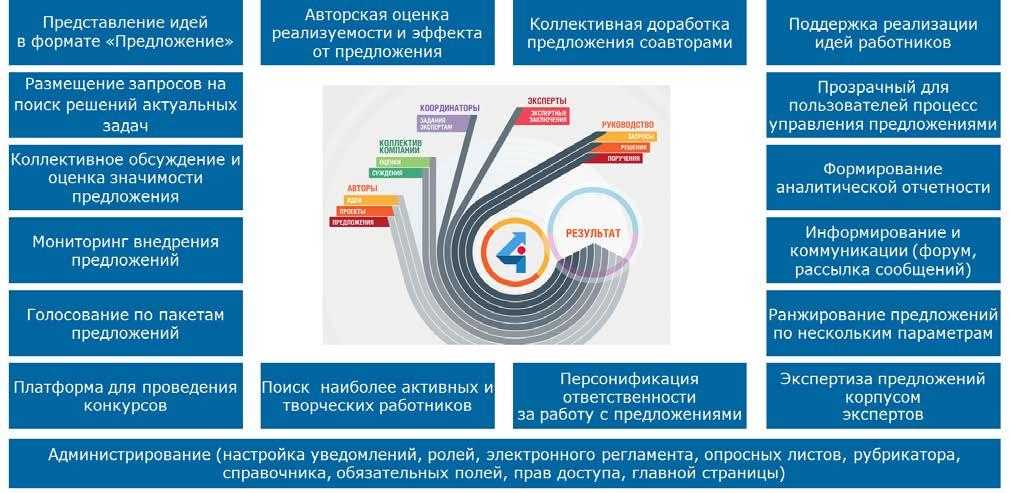
 Обсудите ситуации в группах, запишите не менее 3 опасных ситуаций (слайд 4)
Обсудите ситуации в группах, запишите не менее 3 опасных ситуаций (слайд 4)
 Ранжирование расставляет всё по порядку, присваивает «ранг» по мере важности.
Ранжирование расставляет всё по порядку, присваивает «ранг» по мере важности. Учащиеся планируют свои действия. Получают результат ранжирования ситуаций.
Учащиеся планируют свои действия. Получают результат ранжирования ситуаций.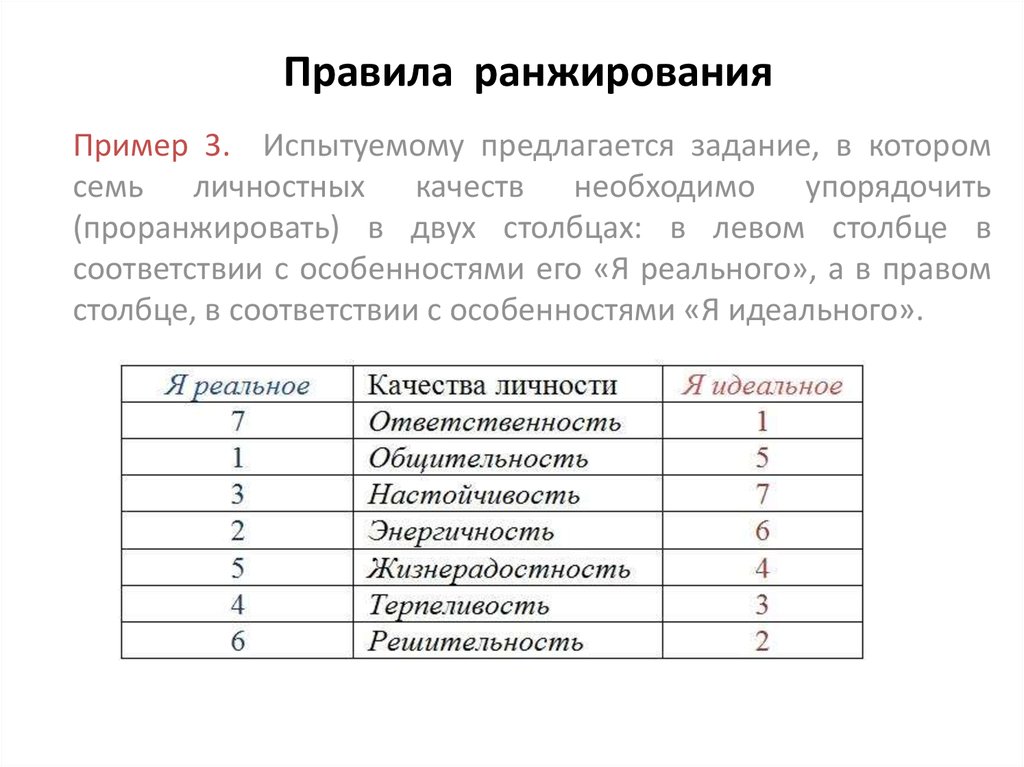
Список использованных источников
1. Анализ состояния детского дорожно-транспортного травматизма на территории Свердловской области за 6 месяцев 2016 года. Опубликовано 05.07.2016 | Автор: Елена Владимировна Лабутина [http: // www.gibdd.ru]
2. Федеральная целевая программа «Повышение безопасности дорожного движения в 2013-2020 годах, принята постановлением Правительства Российской Федерации от 03. 10.13 №864 [http://base.garant.ru/70467076/]
10.13 №864 [http://base.garant.ru/70467076/]
Приложения
1. Презентация «Ранжирование опасных ситуаций на дорогах»
2. Раздаточный материал «Таблица ранжирования»
Алгоритмы и типы ранжирования: концепции и примеры Алгоритмы ранжирования можно разделить на две категории: детерминированные и вероятностные. Алгоритмы ранжирования используются в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. В этой статье мы обсудим различные типы алгоритмов ранжирования и приведем примеры каждого типа.
Содержание
Что такое алгоритм ранжирования?
Алгоритм ранжирования — это процедура, которая ранжирует элементы в наборе данных в соответствии с некоторым критерием. Алгоритмы ранжирования используются во многих различных приложениях, таких как веб-поиск, рекомендательные системы и машинное обучение.
Алгоритм ранжирования — это процедура, используемая для ранжирования элементов в наборе данных в соответствии с некоторым критерием. Алгоритмы ранжирования можно разделить на две категории: детерминированные и вероятностные.
Алгоритмы ранжирования можно разделить на две категории: детерминированные и вероятностные.
- Алгоритмы детерминированного ранжирования : Алгоритм детерминированного ранжирования — это алгоритм, в котором порядок элементов в ранжированном списке фиксирован и не изменяется независимо от входных данных. Примером детерминированного алгоритма ранжирования является алгоритм ранжирования по признаку. В этом алгоритме каждому элементу присваивается ранг на основе значения его признака. Элементу с наивысшим значением признака присваивается ранг 1, а элементу с наименьшим значением признака присваивается ранг N, где N — количество элементов в наборе данных. Одним из реальных приложений алгоритма детерминированного ранжирования является заказ товаров в продуктовом магазине. Товары в продуктовом магазине обычно упорядочены по отделам, таким как продукты, мясо, молочные продукты и т. д. Внутри каждого отдела товары обычно располагаются в алфавитном порядке. Этот тип организации является примером детерминированного алгоритма ранжирования.
 Алгоритмы сортировки используются в алгоритмах детерминированного ранжирования для упорядочения элементов в ранжированном списке. Существует множество различных типов алгоритмов сортировки, каждый из которых имеет свои преимущества и недостатки. Одними из наиболее распространенных алгоритмов сортировки являются сортировка вставками , сортировка слиянием и быстрая сортировка .
Алгоритмы сортировки используются в алгоритмах детерминированного ранжирования для упорядочения элементов в ранжированном списке. Существует множество различных типов алгоритмов сортировки, каждый из которых имеет свои преимущества и недостатки. Одними из наиболее распространенных алгоритмов сортировки являются сортировка вставками , сортировка слиянием и быстрая сортировка . - Алгоритмы вероятностного ранжирования : В алгоритме вероятностного ранжирования порядок элементов в ранжированном списке может варьироваться в зависимости от входных данных. Примером вероятностного алгоритма ранжирования является алгоритм ранжирования по достоверности. В этом алгоритме каждому элементу присваивается ранг на основе его значения достоверности. Элементу с наивысшим значением достоверности присваивается ранг 1, а элементу с наименьшим значением достоверности назначается ранг N, где N — количество элементов в наборе данных. Еще одним примером вероятностного алгоритма ранжирования является байесовский спам-фильтр. В этом алгоритме каждому электронному письму назначается вероятность того, что оно является спамом. Электронные письма с самой высокой вероятностью ранжируются первыми, а электронные письма с самой низкой вероятностью ранжируются последними. Алгоритмы вероятностного ранжирования могут использоваться в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. Алгоритм ранжирования использует входные данные, такие как количество ссылок на веб-страницу с других веб-сайтов и количество раз, когда ключевое слово появляется на странице, для расчета показателя релевантности страницы. Чем выше показатель релевантности, тем выше рейтинг страницы в результатах поиска. Алгоритмы вероятностного ранжирования также могут использоваться в алгоритмах машинного обучения для ранжирования элементов в наборе данных в соответствии с их вероятностью быть положительным примером. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером. Существует множество различных типов алгоритмов вероятностного ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые распространенные типы алгоритмов вероятностного ранжирования:
- Байесовский алгоритм ранжирования : Байесовский алгоритм ранжирования — это вероятностный алгоритм ранжирования, который использует байесовскую сеть для расчета оценки релевантности элемента. Байесовская сеть — это графическая модель, представляющая набор случайных величин и их условных зависимостей. Алгоритм байесовского ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером.
- Алгоритм ранжирования лог-линейной модели : Алгоритм ранжирования лог-линейной модели представляет собой вероятностный алгоритм ранжирования, который использует лог-линейную модель для расчета оценки релевантности элемента. Логлинейная модель — это математическая модель, описывающая взаимосвязь между двумя или более переменными в терминах линейной комбинации логарифмов переменных.
 Алгоритмы сортировки используются в алгоритмах детерминированного ранжирования для упорядочения элементов в ранжированном списке. Существует множество различных типов алгоритмов сортировки, каждый из которых имеет свои преимущества и недостатки. Одними из наиболее распространенных алгоритмов сортировки являются сортировка вставками , сортировка слиянием и быстрая сортировка .
Алгоритмы сортировки используются в алгоритмах детерминированного ранжирования для упорядочения элементов в ранжированном списке. Существует множество различных типов алгоритмов сортировки, каждый из которых имеет свои преимущества и недостатки. Одними из наиболее распространенных алгоритмов сортировки являются сортировка вставками , сортировка слиянием и быстрая сортировка . В этом алгоритме каждому электронному письму назначается вероятность того, что оно является спамом. Электронные письма с самой высокой вероятностью ранжируются первыми, а электронные письма с самой низкой вероятностью ранжируются последними. Алгоритмы вероятностного ранжирования могут использоваться в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. Алгоритм ранжирования использует входные данные, такие как количество ссылок на веб-страницу с других веб-сайтов и количество раз, когда ключевое слово появляется на странице, для расчета показателя релевантности страницы. Чем выше показатель релевантности, тем выше рейтинг страницы в результатах поиска. Алгоритмы вероятностного ранжирования также могут использоваться в алгоритмах машинного обучения для ранжирования элементов в наборе данных в соответствии с их вероятностью быть положительным примером. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента.
В этом алгоритме каждому электронному письму назначается вероятность того, что оно является спамом. Электронные письма с самой высокой вероятностью ранжируются первыми, а электронные письма с самой низкой вероятностью ранжируются последними. Алгоритмы вероятностного ранжирования могут использоваться в поисковых системах для ранжирования веб-страниц в соответствии с их релевантностью поисковому запросу пользователя. Алгоритм ранжирования использует входные данные, такие как количество ссылок на веб-страницу с других веб-сайтов и количество раз, когда ключевое слово появляется на странице, для расчета показателя релевантности страницы. Чем выше показатель релевантности, тем выше рейтинг страницы в результатах поиска. Алгоритмы вероятностного ранжирования также могут использоваться в алгоритмах машинного обучения для ранжирования элементов в наборе данных в соответствии с их вероятностью быть положительным примером. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером. Существует множество различных типов алгоритмов вероятностного ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые распространенные типы алгоритмов вероятностного ранжирования:
Чем выше показатель релевантности, тем больше вероятность того, что элемент является положительным примером. Существует множество различных типов алгоритмов вероятностного ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые распространенные типы алгоритмов вероятностного ранжирования: Логлинейная модель — это математическая модель, описывающая взаимосвязь между двумя или более переменными в терминах линейной комбинации логарифмов переменных.
Логлинейная модель — это математическая модель, описывающая взаимосвязь между двумя или более переменными в терминах линейной комбинации логарифмов переменных.Одним из наиболее распространенных применений алгоритмов ранжирования являются поисковые системы. Поисковые системы используют алгоритмы ранжирования, чтобы определить, какие веб-страницы наиболее релевантны поисковому запросу пользователя. Алгоритмы ранжирования также используются в рекомендательных системах, чтобы рекомендовать элементы, которые могут заинтересовать пользователя. Ниже приводится краткий обзор алгоритма ранжирования, используемого популярными поисковыми системами:
- Алгоритм ранжирования Google : Алгоритм ранжирования Google является секретом, но мы знаем, что это вероятностный алгоритм ранжирования. Google использует различные факторы для ранжирования веб-страниц, включая количество ссылок на страницу, PageRank страницы и релевантность поискового запроса для страницы. Алгоритм Google PageRank — это алгоритм вероятностного ранжирования, который использует количество ссылок на веб-страницу как меру ее важности. Чем выше PageRank веб-страницы, тем больше вероятность того, что она будет занимать более высокое место в результатах поиска.
- Алгоритм ранжирования Amazon : Алгоритм ранжирования Amazon также является алгоритмом вероятностного ранжирования. Amazon использует различные факторы для ранжирования товаров, в том числе количество отзывов о товаре, средний рейтинг товара и цену товара. Алгоритм Amazon предназначен для рекомендации товаров, которые соответствуют поисковому запросу пользователя и популярны среди других пользователей.
- Алгоритм ранжирования Facebook : Алгоритм ранжирования Facebook является секретом, но мы знаем, что это вероятностный алгоритм ранжирования. Facebook использует различные факторы для ранжирования новостей, в том числе количество лайков, репостов и комментариев к статье, PageRank истории и релевантность истории для новостной ленты пользователя. Алгоритм Facebook предназначен для того, чтобы показывать пользователям наиболее актуальные для них истории, о которых говорят их друзья.
- Алгоритм ранжирования Twitter : Алгоритм ранжирования Twitter также является алгоритмом вероятностного ранжирования. Твиттер использует различные факторы для ранжирования твитов, в том числе количество ретвитов, добавленных в избранное и ответов на твит, PageRank автора твита и релевантность твита на временной шкале пользователя. Алгоритм Twitter предназначен для показа пользователям твитов, которые наиболее актуальны для них и о которых говорят их друзья.
 Алгоритм Google PageRank — это алгоритм вероятностного ранжирования, который использует количество ссылок на веб-страницу как меру ее важности. Чем выше PageRank веб-страницы, тем больше вероятность того, что она будет занимать более высокое место в результатах поиска.
Алгоритм Google PageRank — это алгоритм вероятностного ранжирования, который использует количество ссылок на веб-страницу как меру ее важности. Чем выше PageRank веб-страницы, тем больше вероятность того, что она будет занимать более высокое место в результатах поиска. Алгоритм Facebook предназначен для того, чтобы показывать пользователям наиболее актуальные для них истории, о которых говорят их друзья.
Алгоритм Facebook предназначен для того, чтобы показывать пользователям наиболее актуальные для них истории, о которых говорят их друзья.Типы алгоритмов ранжирования
Существует множество различных типов алгоритмов ранжирования, каждый из которых имеет свои преимущества и недостатки. Некоторые из наиболее распространенных типов алгоритмов ранжирования:
- Алгоритмы двоичного ранжирования : Алгоритмы двоичного ранжирования являются простейшим типом алгоритма ранжирования. Алгоритм бинарного ранжирования ранжирует элементы в наборе данных в соответствии с их относительной важностью. Двумя наиболее распространенными типами алгоритмов бинарного ранжирования являются алгоритмы ранжирования по признакам и алгоритмы ранжирования по частоте. Алгоритмы ранжирования по признаку ранжируют элементы по количеству признаков, которые они имеют вместе с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритмы ранжирования по частоте ранжируют элементы по количеству раз, которое они встречаются в наборе данных. Алгоритмы ранжирования по признакам и частоте имеют свои преимущества и недостатки. Алгоритмы ранжирования по признаку более точны, чем алгоритмы ранжирования по частоте, но они также требуют больших вычислительных ресурсов. Алгоритмы ранжирования по частоте быстрее, чем алгоритмы ранжирования по признакам, но они менее точны.
- Ранжирование по сходству : Ранжирование по сходству — это тип алгоритма вероятностного ранжирования, который ранжирует элементы в наборе данных в соответствии с их сходством с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше элемент похож на эталонный элемент. Существует множество различных типов ранжирования по алгоритмам сходства, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по алгоритмам сходства являются алгоритм кластерного ранжирования, алгоритм ранжирования в векторном пространстве и т. д.
- Ранжирование по расстоянию : Алгоритмы ранжирования по расстоянию представляют собой тип вероятностного алгоритма ранжирования, который ранжирует элементы в наборе данных в соответствии с их расстоянием от эталонного элемента. Ссылочный элемент — это элемент, который используется для вычисления значения расстояния для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем дальше элемент находится от эталонного элемента. Существует множество различных типов алгоритмов ранжирования по расстоянию, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами алгоритмов ранжирования по расстоянию являются алгоритм Евклидова расстояния, алгоритм расстояния Махаланобиса и т. д.
- Ранжирование по предпочтениям : Алгоритмы предпочтительного ранжирования представляют собой тип алгоритма вероятностного ранжирования, который ранжирует элементы в наборе данных в соответствии с их предпочтением эталонного элемента. Эталонный элемент — это элемент, который используется для расчета значения предпочтения для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем более предпочтительным является элемент для эталонного элемента.
- Ранжирование по вероятности : Ранжирование по вероятности — это тип вероятностного алгоритма ранжирования, который ранжирует элементы в наборе данных в соответствии с их вероятностью быть положительным примером. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше вероятность того, что элемент будет положительным примером. Ранжирование по вероятности отличается от других типов алгоритмов ранжирования, поскольку оно учитывает неопределенность данных. Это делает его более точным, чем другие типы алгоритмов ранжирования. Существует множество различных типов ранжирования по вероятностным алгоритмам, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по вероятностным алгоритмам являются байесовский алгоритм ранжирования, алгоритм ранжирования AUC и т. д.
 Алгоритм бинарного ранжирования ранжирует элементы в наборе данных в соответствии с их относительной важностью. Двумя наиболее распространенными типами алгоритмов бинарного ранжирования являются алгоритмы ранжирования по признакам и алгоритмы ранжирования по частоте. Алгоритмы ранжирования по признаку ранжируют элементы по количеству признаков, которые они имеют вместе с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритмы ранжирования по частоте ранжируют элементы по количеству раз, которое они встречаются в наборе данных. Алгоритмы ранжирования по признакам и частоте имеют свои преимущества и недостатки. Алгоритмы ранжирования по признаку более точны, чем алгоритмы ранжирования по частоте, но они также требуют больших вычислительных ресурсов. Алгоритмы ранжирования по частоте быстрее, чем алгоритмы ранжирования по признакам, но они менее точны.
Алгоритм бинарного ранжирования ранжирует элементы в наборе данных в соответствии с их относительной важностью. Двумя наиболее распространенными типами алгоритмов бинарного ранжирования являются алгоритмы ранжирования по признакам и алгоритмы ранжирования по частоте. Алгоритмы ранжирования по признаку ранжируют элементы по количеству признаков, которые они имеют вместе с эталонным элементом. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритмы ранжирования по частоте ранжируют элементы по количеству раз, которое они встречаются в наборе данных. Алгоритмы ранжирования по признакам и частоте имеют свои преимущества и недостатки. Алгоритмы ранжирования по признаку более точны, чем алгоритмы ранжирования по частоте, но они также требуют больших вычислительных ресурсов. Алгоритмы ранжирования по частоте быстрее, чем алгоритмы ранжирования по признакам, но они менее точны. Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше элемент похож на эталонный элемент. Существует множество различных типов ранжирования по алгоритмам сходства, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по алгоритмам сходства являются алгоритм кластерного ранжирования, алгоритм ранжирования в векторном пространстве и т. д.
Эталонный элемент — это элемент, который используется для вычисления значения сходства для каждого из других элементов в наборе данных. Алгоритм ранжирования использует входные данные, такие как количество признаков, общих как для положительных, так и для отрицательных примеров, для расчета оценки релевантности элемента. Чем выше показатель релевантности, тем больше элемент похож на эталонный элемент. Существует множество различных типов ранжирования по алгоритмам сходства, каждый из которых имеет свои преимущества и недостатки. Некоторыми распространенными типами ранжирования по алгоритмам сходства являются алгоритм кластерного ранжирования, алгоритм ранжирования в векторном пространстве и т. д.Заключение
Алгоритмы ранжирования используются для ранжирования элементов в наборе данных в соответствии с некоторым критерием. Существует множество различных типов алгоритмов ранжирования, каждый из которых имеет свои преимущества и недостатки. Ранжирование по сходству, расстоянию, предпочтению и вероятности являются наиболее распространенными типами алгоритмов ранжирования. Ранжирование по вероятности является наиболее точным типом алгоритма ранжирования, поскольку оно учитывает неопределенность данных. Если вы хотите узнать больше об алгоритмах ранжирования, оставьте комментарий ниже.
- Автор
- Последние сообщения
Аджитеш Кумар
Недавно я работал в области анализа данных, включая науку о данных и машинное обучение / глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой, озаглавленной «Основы мышления: создание успешных продуктов с использованием первых принципов».
Недавно я работал в области аналитики данных, включая науку о данных и машинное обучение/глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой под названием «Мышление на основе первых принципов: создание успешных продуктов с использованием мышления на основе первых принципов».0003
Опубликовано в Data Science. Помечены машинным обучением.
Типы рангов
В этом документе представлены типы рангов, которые поддерживаются nativeRank.
и основные функции ранжирования, которые контролируются с их помощью.
См. Справочник по нативному рейтингу
для получения подробной информации о функции nativeRank.
Во-первых, объясняются общие механизмы управления ранжированием с помощью типов рангов.
Затем будет описан каждый тип ранжирования с подробным описанием того, как он использует различные элементы управления ранжированием.
Использование рангового типа
Типы рангов для поля либо контролируются
профиль ранга или по полю.
Использование его для каждого рангового профиля дает более гибкое управление:
продукт Rank-Profile наследует значение по умолчанию {
титул типа ранга: идентифицируйте
корпус рангового типа: о
первая фаза {
выражение: nativeRank
}
}
Средства управления ранжированием
В этом разделе описываются различные общие элементы управления ранжированием, на которые влияет выбор типа ранжирования. {-\frac{x}{t}}$$
где w вес (управляет амплитудой)
и t — параметр настройки (управляет наклоном).
Формы кривых показаны на рис. 1-2.
Рисунок 1. Вес графика FirstOcc: увеличение амплитуды подъемов w
(ось X — это первое место вхождения, а ось Y — первое увеличение)
Рис. 2. Настройка графика FirstOcc: увеличение t уменьшает экспоненциальный спад
(ось X — это первое место вхождения, а ось Y — первое увеличение)
Повышение NumOcc
Количество вхождений термина в поле документа называется NumOcc .
Таблица повышения NumOcc отображает заданное количество вхождений x
к определенному ранговому вкладу.
Для терминов, встречающихся больше или равно размеру таблицы (по умолчанию 256),
используется значение для последнего элемента таблицы.
Уравнение 2. Пример функции таблицы повышения NumOcc:
$$numocc(x) = логарифмический рост(x) = {w} * log(1+\frac{x}{s}) + {t}$$
где w вес (управляет амплитудой)
и t — параметр настройки (управляет смещением).
s — параметр шкалы (управляет чувствительностью к переменной numocc x).
Рисунок 3. Вес графика NumOcc: увеличение w масштабирует логарифм амплитуды/формы
(ось x — количество вхождений в поле, ось y — усиление numocc)
Рисунок 4. Настройка графика NumOcc: увеличение t увеличивает усиление на значение смещения
(ось x — количество вхождений в поле, ось y — усиление numocc)
Повышение близости
Когда выполняется запрос с более чем одним условием запроса,
попарная близость вычисляется между парами терминов запроса.
Для данной пары фактическое значение рейтинга будет основано на поиске в таблице повышения близости.
Для заданной пары терминов-запросов a b ,
вычисляется расстояние в поле документа между позициями терминов
таким образом, что если термины встречаются в одном и том же порядке как в запросе, так и в документе,
расстояние будет положительным. {-\frac{x}{t}}$$
где x — абсолютная разница между
расстояние термина запроса и расстояние термина документа,
w вес (управляет амплитудой) и
t — параметр настройки (управляет наклоном).
См. рис. 5 и 6: используется та же формула, что и в примерах FirstOcc,
но с другими параметрами.
Рисунок 5. Вес графика близости: w масштабирует амплитуду
(ось x представляет собой расстояние пары терминов близости, а ось y — увеличение близости)
Рисунок 6. Настройка графика близости: увеличение t уменьшает спад кривой
(ось x представляет собой расстояние пары терминов близости, а ось y — увеличение близости)
Повышение веса
Таблица увеличения веса предназначена для расчета вклада повышения ранга от атрибутов.
Уравнение 4 показывает, как значения веса атрибута используются для просмотра таблицы в таблице weightboost.
Уравнение 4. Пример таблицы повышения веса:
$$вес(х) = знак(х) * увеличение веса[абс(х)]$$
где знак(х) является знаком x ,
и абс(х) является абсолютным значением x .
Следовательно, атрибуты могут иметь отрицательный ранговый вклад.
Аргумент x , используемый в качестве входных данных в этой таблице повышения, зависит от типа атрибута:
- Взвешенный набор: x равен весу атрибута.
- Массив: х
равно количеству совпадений в массиве атрибутов. - Одно значение: x равно 1.
Типы рангов
В этом разделе описывается каждый отдельный тип ранжирования,
и подробно описывает, как он использует различные общие элементы управления ранжированием.
Тип ранга «удостоверение личности»
Этот тип ранжирования предназначен для полей, содержащих идентификатор документа.
Название книги или название продукта являются примерами этого.
Заголовок обычно появляется в начале документа.
Таким образом, таблица FirstOcc начинается с высокого уровня и резко снижается.
Заголовок обычно не повторяется, поэтому количество вхождений не так важно.
Он начинается на средней высоте и медленно поднимается.
Идентификационные термины хорошо связаны, а поля довольно малы.
Таким образом, таблица близости имеет резкий и высокий пик, а важность быстро падает.
Поддерживается nativeRank с использованием следующих таблиц:
- nativeFieldMatch.firstOccurrenceTable: «expdecay(100,12.50)»
- nativeFieldMatch.occurrenceCountTable: «loggrowth (1500,4000,19)»
- nativeProximity.proximityTable: «expdecay(5000,3)»
- nativeProximity.reverseProximityTable: «expdecay (3000,3)»
- nativeAttributeMatch.weightTable: «линейный (1,0)»
«о» разряд типа
Это для полей, которые содержат информацию, непосредственно относящуюся к документу, описывающую, что это такое.
Типичными примерами являются поле описания каталога или список функций спецификации продукта.
Порядок появления несколько важен,
как обычно самые важные функции будут выставлены первыми.
Стол повышения FirstOcc начинается со средней высоты и довольно медленно опускается.
Приблизительность описания во многом связана с тем, сколько раз используется описательный термин.
Таким образом, таблица повышения NumOcc будет начинаться довольно низко, но подниматься высоко,
с максимальным усилением (точкой кривизны) около 5 вхождений.
Близость довольно важна для о-ности.
Повышение близости будет чем-то похоже на тождество тип,
хотя он будет несколько ниже на пике и будет иметь более пологий спад.
о тип ранжирования по умолчанию
используется, когда явно не указано, какой тип использовать.
Поддерживается nativeRank с использованием следующих таблиц:
- nativeFieldMatch.firstOccurrenceTable: «expdecay (8000,12.50)»
- nativeFieldMatch.occurrenceCountTable: «loggrowth (1500,4000,19)»
- nativeProximity.proximityTable: «expdecay(500,3)»
- nativeProximity. reverseProximityTable: «expdecay(400,3)»
- nativeAttributeMatch.weightTable: «линейный (1,0)»
Тип ранга «метки»
Это для поиска по атрибутам, когда они используются как теги,
например теги имен для изображений, которые могут часто обновляться.
Тип ранжирования тегов использует логарифмическую таблицу, чтобы дать больший относительный импульс в нижнем диапазоне:
По мере добавления тегов они должны оказывать существенное влияние на рейтинг.
но по мере того, как добавляется все больше и больше тегов, каждый новый тег должен вносить меньший вклад.
Тип ранга тегов основан на типе ранга о ,
т.е. отличается только таблица увеличения веса.
Для других типов рангов используется линейная таблица 1-к-1, за исключением типа пустого ранга,
у которого есть таблица с нулями.
Поддерживается nativeRank с использованием этой таблицы:
- nativeAttributeMatch.weightTable: «loggrowth(38,50,1)»
Остальные таблицы аналогичны типам рангов и .