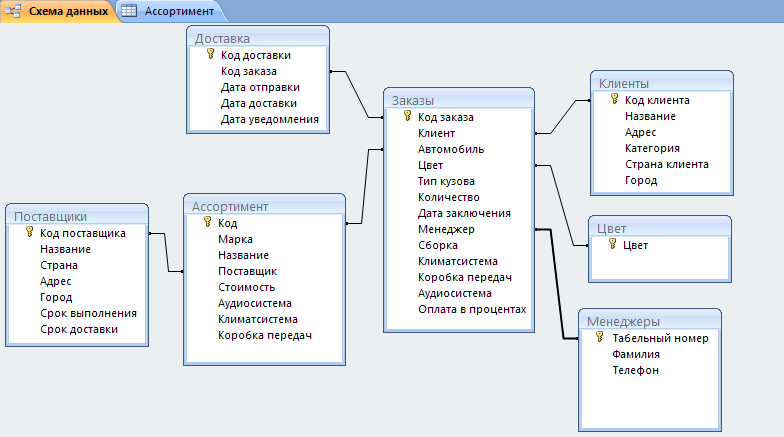
Содержание
Функции ранжирования: ROW_NUMBER (), RANK () и DENSE_RANK ()
Одной из лучших функций в SQL являются оконные функции . Дмитрий Фонтейн выразился прямо:
Был SQL перед оконными функциями и SQL после оконных функций
Если вам повезло использовать любую из этих баз данных, то вы можете использовать оконные функции самостоятельно:
- CUBRID
- DB2
- жар-птица
- Informix
- оракул
- PostgreSQL
- SQL Server
- Sybase SQL Anywhere
- Teradata
(источник здесь)
Одним из наиболее очевидных и полезных наборов оконных функций являются функции ранжирования, в которых строки из вашего набора результатов ранжируются в соответствии с определенной схемой. Есть три функции ранжирования:
ROW_NUMBER()RANK()DENSE_RANK()
Разницу легко запомнить. Для примеров, давайте предположим, что у нас есть эта таблица (с использованием синтаксиса PostgreSQL):
CREATE TABLE t(v) AS
SELECT * FROM (
VALUES('a'),('a'),('a'),('b'),
('c'),('c'),('d'),('e')
) t(v)ROW_NUMBER ()
… Присваивает уникальные номера каждой строке в PARTITIONданном ORDER BYпредложении. Итак, вы получите:
Итак, вы получите:
SELECT v, ROW_NUMBER() OVER()
FROM tОбратите внимание, что некоторые диалекты SQL (например, SQL Server) требуют явного ORDER BYпредложения в OVER()предложении:
SELECT v, ROW_NUMBER() OVER(ORDER BY v)
FROM t
Приведенный выше запрос возвращает:
(см. также этот SQLFiddle)
РАНГ()
… Ведет себя так ROW_NUMBER(), за исключением того, что «равные» строки ранжируются одинаково. Если мы подставим RANK()в наш предыдущий запрос:
SELECT v, RANK() OVER(ORDER BY v)
FROM t… тогда мы получаем следующий результат:
(см. также этот SQLFiddle)
Как видите, как и в спортивном рейтинге, у нас есть разрывы между различными рангами. Мы можем избежать этих пробелов, используя
DENSE_RANK ()
Тривиально, DENSE_RANK()это ранг без пробелов, т.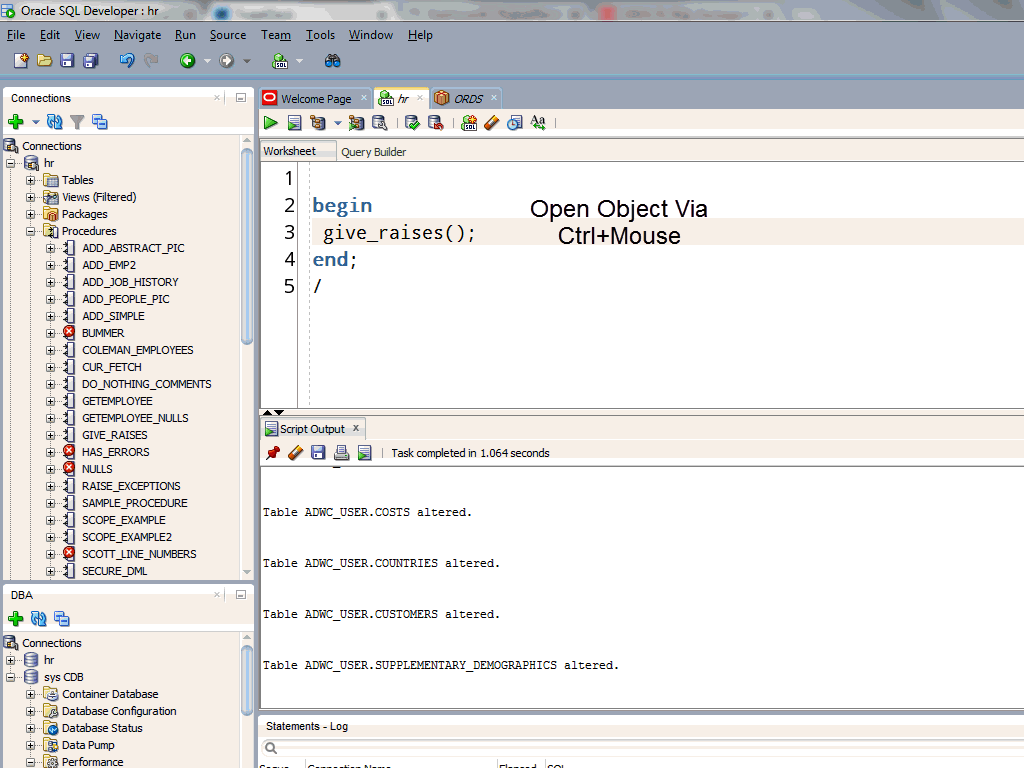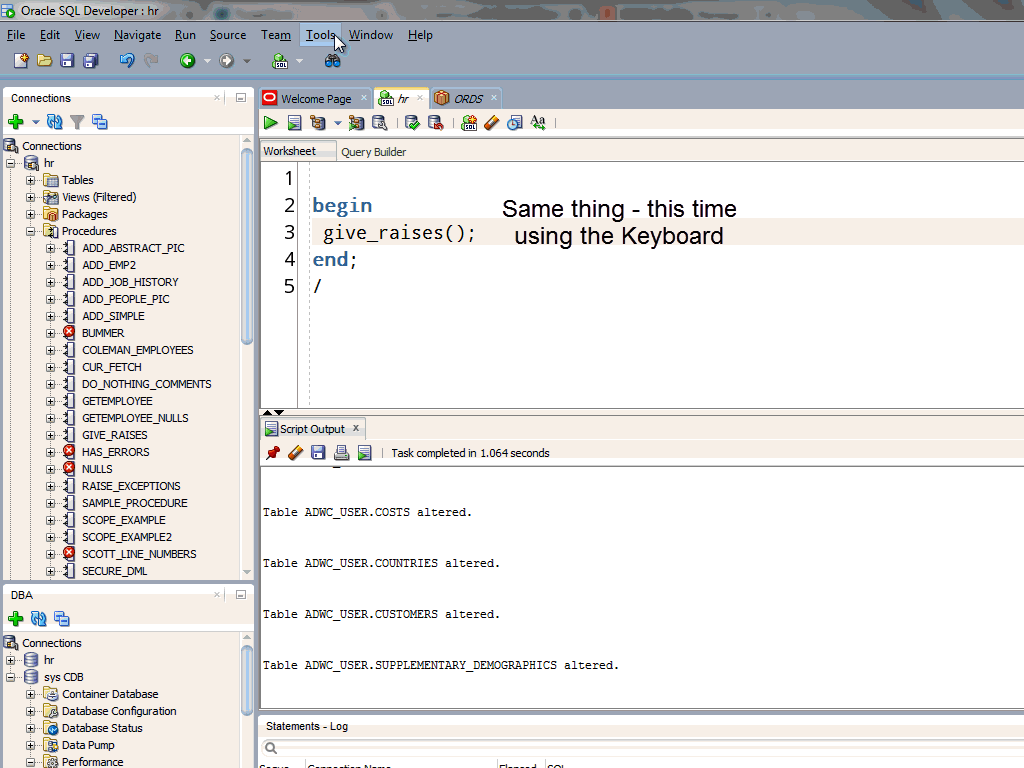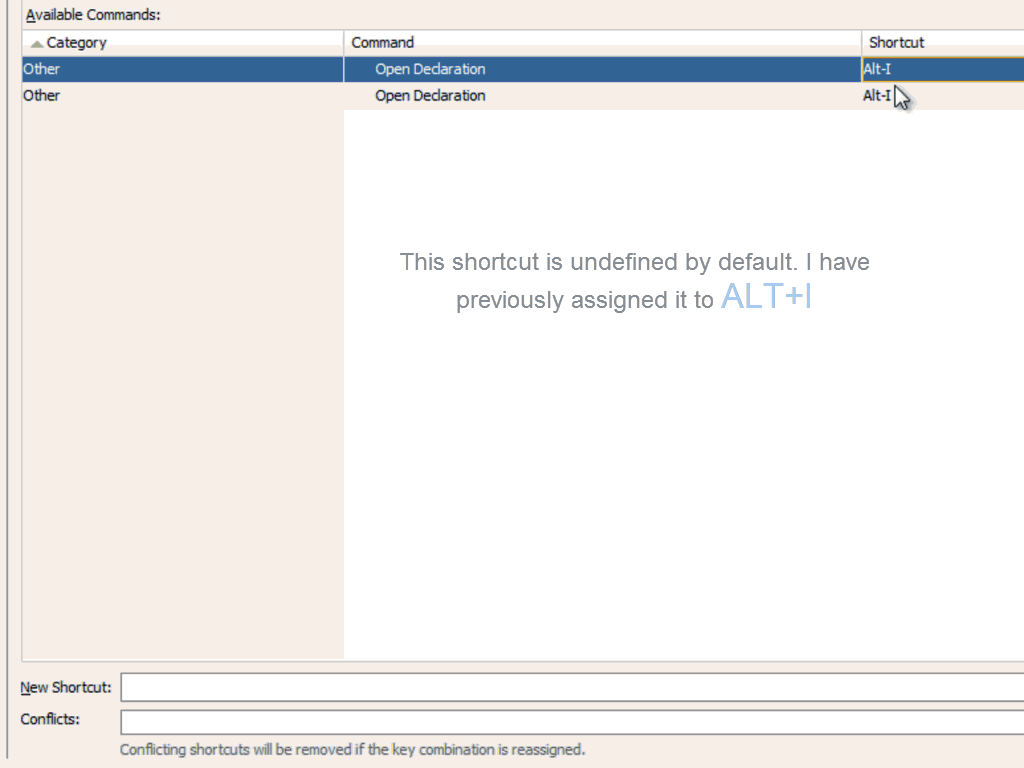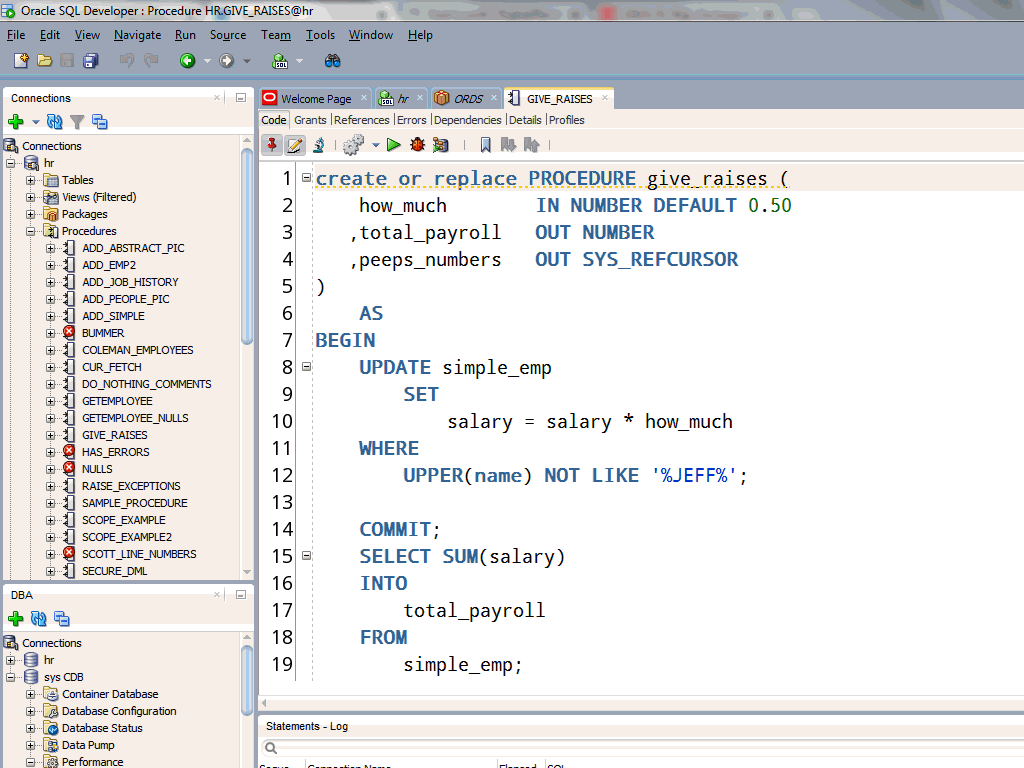 е. он «плотный» . Мы можем написать:
е. он «плотный» . Мы можем написать:
SELECT v, DENSE_RANK() OVER(ORDER BY v)
FROM t… чтобы получить
(см. также этот SQLFiddle)
Одним интересным аспектом DENSE_RANK()является тот факт, что он «ведет себя как», ROW_NUMBER()когда мы добавляем DISTINCTключевое слово .
SELECT DISTINCT v, DENSE_RANK() OVER(ORDER BY v)
FROM t… чтобы получить
(см. также этот SQLFiddle)
На самом деле, не ROW_NUMBER()позволяет использовать DISTINCT, потому что ROW_NUMBER()генерирует уникальные значения в разделе передDISTINCT применением:
SELECT DISTINCT v, ROW_NUMBER() OVER(ORDER BY v)
FROM t
ORDER BY 1, 2DISTINCT не имеет никакого эффекта:
(см. также этот SQLFiddle)
Собираем все вместе
Хороший способ понять три функции ранжирования — это увидеть их все в действии бок о бок. Запустите этот запрос
Запустите этот запрос
SELECT
v,
ROW_NUMBER() OVER(ORDER BY v),
RANK() OVER(ORDER BY v),
DENSE_RANK() OVER(ORDER BY v)
FROM t
ORDER BY 1, 2… Или этот (используя стандартное WINDOWпредложение SQL , чтобы повторно использовать спецификации окон):
SELECT
v,
ROW_NUMBER() OVER(w),
RANK() OVER(w),
DENSE_RANK() OVER(w)
FROM t
WINDOW w AS (ORDER BY v)… чтобы получить:
(см. также этот SQLFiddle)
Обратите внимание, что, к сожалению, это WINDOWпредложение поддерживается не во всех базах данных.
SQL потрясающий
Эти вещи можно написать очень легко с помощью оконных функций SQL. Как только вы освоите синтаксис, вы больше не захотите пропускать эту убойную функцию в своих ежедневных SQL-выражениях. В восторге?
Для дальнейшего чтения рассмотрим:
- Руководства jOOQ по оконным функциям
- Отличная статья Дмитрия Фонтейна «Понимание оконных функций»
- Реальный пример использования: подсчет соседних цветов в хореографии стадиона
- Реальный пример использования: вычисление промежуточных итогов (не только с оконными функциями)
- SQL 101: окно в мир аналитических функций
Функции ранжирования в MS SQL — .
 NetBlog
NetBlog
Как вы наверняка знаете, в реляционных базах данных строки в таблице не имеют порядка. Можно, конечно, использовать дополнительные механизмы, например IDENTITY-столбец, но это все равно не поможет вам получить, например, порядок строки в результатах запроса. Для возможности как-то соотносить порядок одних строк с другими и придуманы функции ранжирования. Прежде чем я перейду к рассказу о них, отмечу один важный момент: все ранжирующие функции являются недетерминированными, то есть результат их выполнения каждый раз может быть разным (хотя, на одном и том же наборе данных, один и тот же запрос будет возвращать один и тот же результат).
Итак, собственно, функции ранжирования. Представим, что у нас есть вот такая табличка:
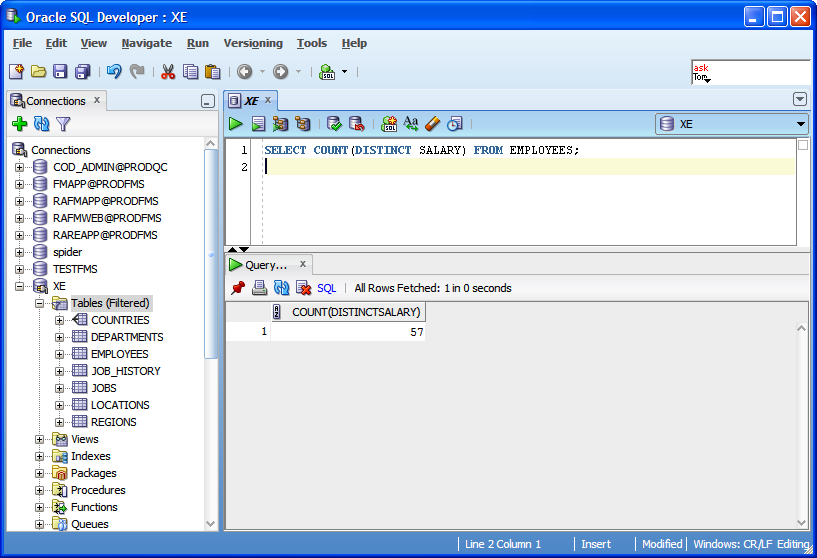
И мы хотим получить порядок строк отсортированных по типу оборудования. Для этого можно использовать функция ROW_NUMBER().
SELECT ROW_NUMBER() OVER (ORDER BY PositionType DESC) as RowNumber ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering]
 [dbo].[rowNumbering]
[dbo].[rowNumbering]
В результате выполнения этого запроса мы получим вот такой результат:
Как вы заметили, для указания на базе какого столбца будет сделана нумерация в запросе используется конструкция ORDER BY. На больших наборах данных из-за этого может пострадать производительность, но, если порядок следования рядов в результате выдачи вам не важен, то сортировки можно избежать, используя примерно такую конструкцию:
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT TOP 1 1 FROM [test].[dbo].[rowNumbering])) as RowNumber ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering]
Основная область применения функции ROW_NUMBER() — это нумерация срок в результирующем наборе, для более интересных задач можно использовать остальные функции.
Следующая функция — RANK() более интересна. Она позволяет ранжировать результаты выдачи на основе какого-то столбца.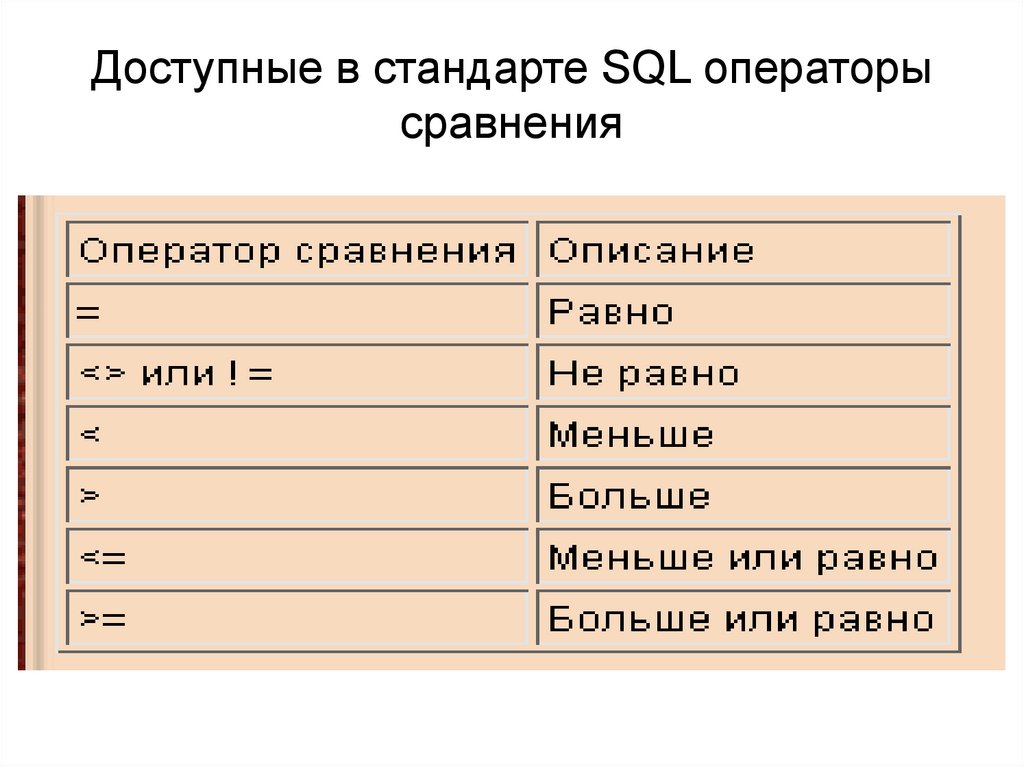 Посмотрите на результат выполнения вот такого запроса:
Посмотрите на результат выполнения вот такого запроса:
SELECT RANK() OVER (ORDER BY PositionType DESC) as rnk ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering]
Как видите, все сервера у нас получили ранг равный 1, а модем — ранг равный 4. Почему не 2? Потому что в функции RANK() ранг каждого ряда вычисляется как номер ряда+1. Ряды с одинаковым значением столбца получают одинаковый ранг, а следующий отличающийся — свой порядковый.
Для того, чтобы избежать подобных «дыр» в нумерации рангов существует функция DENSE_RANK(). Синтаксис у нее точно такой же:
SELECT DENSE_RANK() OVER (ORDER BY positionType DESC) as rnk ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering]
А результат выполнения выглядит уже значительно красивее:
Ну а самое интересное во всех функциях ранжирования — это возможность разделять результирующий набор данных на основании значения какой либо колонки.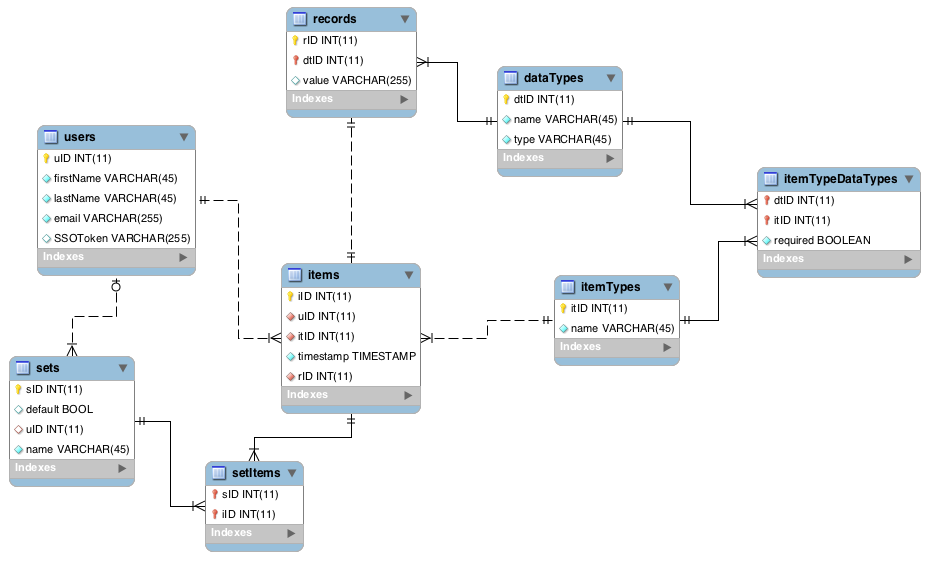 Для этого используется выражение PARTITION BY. Давайте попробуем вывести пронумерованный список продуктов каждой компании. Используем для этого функцию ROW_NUMBER() с выражением PARTITION BY maker.
Для этого используется выражение PARTITION BY. Давайте попробуем вывести пронумерованный список продуктов каждой компании. Используем для этого функцию ROW_NUMBER() с выражением PARTITION BY maker.
SELECT ROW_NUMBER() OVER (PARTITION BY maker ORDER BY PositionType DESC) as RowNumber ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering]
В результате выполнения этого запросы мы получим вот такой набор данных:
Ну и напоследок пример практического применения функции ранжирования. Давайте найдем самые дешевые сервера у каждой компании-производителя. Запрос, решающий эту задачу будет выглядеть вот так. (Отступы я сделал для наглядности где какая часть запроса)
SELECT maker, positionName FROM (
SELECT DENSE_RANK() OVER (PARTITION BY maker ORDER BY price) as rnk
,[maker]
,[positionName]
,[positionType]
,[price]
FROM
(SELECT * FROM [test].[dbo].[rowNumbering] where positionType='server') as t1
) as t2
where rnk=1
А вот результат его выполнения:
Функции ранжирования (Transact-SQL) — SQL Server
Редактировать
Твиттер
Фейсбук
Эл. адрес
адрес
- Статья
- 2 минуты на чтение
Применимо к:
SQL Server (все поддерживаемые версии)
База данных SQL Azure
Управляемый экземпляр Azure SQL
Аналитика синапсов Azure
Система аналитической платформы (PDW)
Функции ранжирования возвращают значение ранжирования для каждой строки в разделе. В зависимости от используемой функции некоторые строки могут получить то же значение, что и другие строки. Функции ранжирования недетерминированы.
Transact-SQL предоставляет следующие функции ранжирования:
DENSE_RANK
ROW_NUMBER
Примеры
В следующем примере показаны четыре функции ранжирования, используемые в одном запросе. Примеры для конкретных функций см. в описании каждой функции ранжирования.
в описании каждой функции ранжирования.
ИСПОЛЬЗОВАТЬ AdventureWorks2012;
ИДТИ
ВЫБРАТЬ p.FirstName, p.LastName
,ROW_NUMBER() OVER (ORDER BY a.PostalCode) AS "Номер строки"
,РАНГ() ПРЕВЫШЕН (ЗАКАЗ ПО Почтовому индексу) КАК РАНГ
,DENSE_RANK() OVER (ORDER BY a.PostalCode) AS "Dense Rank"
,NTILE(4) OVER (ORDER BY a.PostalCode) КАК Квартиль
,s.Продажи с начала года
,a.Почтовый индекс
ОТ Sales.SalesPerson AS s
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Person.Person AS p
ON s.BusinessEntityID = p.BusinessEntityID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Person.Address КАК
ON a.AddressID = p.BusinessEntityID
ГДЕ TerritoryID НЕ NULL И SalesYTD <> 0;
Вот набор результатов.
| Имя | Фамилия | Номер строки | Ранг | Плотный ранг | Квартиль | Продажи с начала года | Почтовый индекс |
|---|---|---|---|---|---|---|---|
| Майкл | Блайт | 1 | 1 | 1 | 1 | 4557045. 0459 0459 | 98027 |
| Линда | Митчелл | 2 | 1 | 1 | 1 | 5200475.2313 | 98027 |
| Джиллиан | Карсон | 3 | 1 | 1 | 1 | 3857163.6332 | 98027 |
| Гаррет | Варгас | 4 | 1 | 1 | 1 | 1764938.9859 | 98027 |
| Цви | Райтер | 5 | 1 | 1 | 2 | 2811012.7151 | 98027 |
| Шу | Ито | 6 | 6 | 2 | 2 | 3018725.4858 | 98055 |
| Хосе | Сарайва | 7 | 6 | 2 | 2 | 3189356.2465 | 98055 |
| Дэвид | Кэмпбелл | 8 | 6 | 2 | 3 | 3587378.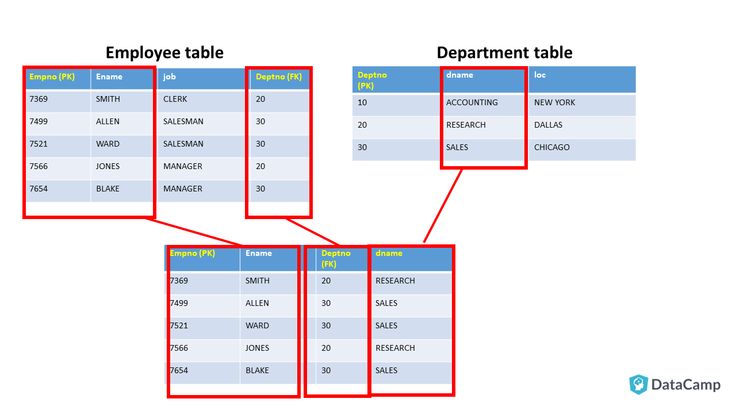 4257 4257 | 98055 |
| Тете | Менса-Аннан | 9 | 6 | 2 | 3 | 1931620.1835 | 98055 |
| Линн | Цофлиас | 10 | 6 | 2 | 3 | 1758385,926 | 98055 |
| Рэйчел | Вальдес | 11 | 6 | 2 | 4 | 2241204.0424 | 98055 |
| Джэ | Пакет | 12 | 6 | 2 | 4 | 5015682.3752 | 98055 |
| Ранджит | Варкей Чудукатил | 13 | 6 | 2 | 4 | 3827950.238 | 98055 |
См. также
Встроенные функции (Transact-SQL)
Пункт OVER (Transact-SQL)
Руководство по функциям окна ранжирования SQL
| by Nima Beheshti
ROW_NUMBER(), RANK(), DENSE_RANK(), NTILE(), PERCENT_RANK(), CUME_DIST()
В мире SQL-запросов нам часто приходится создавать какой-то вид ранжирования, чтобы лучше понимать наши данные. К счастью для нас, функции ранжирования являются одной из основных областей под эгидой оконных функций и могут быть легко реализованы!
К счастью для нас, функции ранжирования являются одной из основных областей под эгидой оконных функций и могут быть легко реализованы!
Шесть типов функций ранжирования:
- Row_number ()
- Rank ()
- Dense_rank ()
- процент_ранк ()
- NTIL каждой функции ранжирования, мы должны посмотреть, как эти функции обычно записываются:
[Функция ранжирования]() OVER([конкретная операция] имя_столбца)
Например, на практике команда SQL будет выглядеть так:
SELECT *, ROW_NUMBER() OVER(PARTITION BY column1 ORDER BY column2 DESC)
FROM tableВ этом примере мы выбираем все строки в нашей таблице и ранжируем выходные данные в порядке убывания столбца 2, разделенного по каждому значению столбца1. Это станет более понятным, когда мы перейдем к описанию и примерам каждой функции ранжирования.
Данные:
Данные, использованные в этой статье, были созданы только для демонстрационных целей и не отражают точного представления изображаемых чисел. Данные состоят из трех столбцов: c_name — название города, c_state — штат города и coffee_shop_num — количество кофеен в этом городе. *Ниже показана только часть данных*Изображение автора
ROW_NUMBER:
Функции ранжирования ROW_NUMBER() обеспечивают последовательное ранжирование данного раздела по количеству строк в этом разделе. Если две строки имеют одинаковую информацию, функция определяет, какая из них занимает первое место на основе информации, предоставленной в операторе OVER(). Используя ранжирование Row_Number, каждая строка в данном разделе получает собственный ранг без дубликатов или пропущенных номеров. Пример этой функции ниже:SELECT *,
ROW_NUMBER() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) as rank
FROM cityИзображение автора
соответствуют ничьим, выбираются случайным образом для определенного места в рейтинге.
RANK :
Функция ранжирования RANK() дает тот же результат, что и функция ROW_NUMBER(), однако в функции RANK() связям присваивается одно и то же значение, а последующие значения пропускаются. Используя функцию RANK(), можно получить повторяющиеся рейтинги в разделе и иметь непоследовательные рейтинги, поскольку числа пропускаются после совпадений. Ниже приведен пример функции RANK().SELECT *,
RANK() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) as rank
FROM cityImage by Author
Как видно из приведенных выше результатов, Сан-Диего и Малибу имеют одинаковое количество кофеен и оба получили ранг 3 за этот раздел, следующий ранг подскочил до 5, что также оказалось равным. Точно так же Лисбург и Ричмонд сравнялись по количеству кофеен и оба получили рейтинг 4, а следующий город, Блэксбург, получил рейтинг 6.
DENSE_RANK:
Функция ранжирования DENSE_RANK() действует как гибрид между RANK() и ROW_NUMBER() в том смысле, что эта функция допускает наличие связей внутри раздела, но также обеспечивает последовательное ранжирование после совпадений. Например, порядок ранжирования в разделе может выглядеть так: 1, 2, 3, 3, 4, 4, 5. Это можно увидеть в примере кода и выводе ниже, где снова Сан-Диего и Малибу занимают третье место, а следующие город получает ранг 4.SELECT *,
DENSE_RANK() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) as rank
FROM cityImage by Author
NTILE:
Функция ранжирования NTILE() работает иначе, чем три функции, которые мы уже видели. Эта функция делит строки внутри раздела на указанное количество делений. Затем строки назначаются одной из этих групп в соответствии с их рангом, начиная с 1 и продолжая до указанного количества групп. Используя пример кода и выходные данные ниже, мы видим, что мы передали число 5 в функцию NTILE(), что означает, что мы разбиваем каждый раздел на 5 групп. Мы видим, что каждой строке присвоен ранг от 1 до 5, а некоторые группы содержат более одной строки, как и ожидалось, учитывая, что в каждом разделе более 5 городов. В этом случае связи могут быть внутри одной группы или разделены, как в случае с Calexico и La Jolla.SELECT *,
NTILE(5) OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) as rank
FROM cityImage by Author
PERCENT_RANK:
Функция PERCENT_RANK() предоставляет процентиль ранга каждой строки . Самый низкий ранг начинается с 0 и продолжается до единицы, при этом каждое значение интервала равно 1/(n-1), где n — число или строки в данном разделе. В приведенном ниже примере кода мы видим, что Лос-Анджелес является самым низким процентилем (самым высоким рейтингом) со значением 0, после Лос-Анджелеса каждая строка будет соответствовать значению 1/(7–1) = 0,1666, при этом работают связи. так же, как функция RANK(). Как видно ниже, Калексико и Ла-Холья имеют один и тот же ранговый процентиль, но, поскольку в совокупности они представляют 0,166 + 0,166, после Ла-Хойи следующий назначенный процентиль равен 1 для Ирвина.SELECT *,
PERCENT_RANK() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) как процентиль
FROM cityImage by Author ), но вместо того, чтобы начинать с 0 и продолжать с 1/(n-1), CUME_DIST() начинается со значения 1/n и продолжается с 1/n до конечного значения 1 в данном разделе.
Совпадения в CUME_DIST() обрабатываются так же, как и в PERCENT_RANK(). Как видно из примера кода и выходных данных ниже, Лос-Анджелес начинается со значения 0,143, а процентиль каждой строки соответствует прибавлению примерно 0,143, а связи соответствуют сумме количества связанных строк. В конечном итоге раздел заканчивается процентилем 1,9.0003SELECT *,
CUME_DIST() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) как процентиль
FROM cityИзображение автора
Заключение :
Эти шесть оконных функций ранжирования имеют множество вариантов использования и являются важным навыком для освоения . Многие функции похожи только в нескольких различных аспектах, что поначалу может сбивать с толку, но после некоторой практики вы будете точно знать, какую функцию использовать в любом конкретном сценарии. Я надеюсь, что это руководство было полезным, и, как всегда, благодарю вас за то, что вы нашли время, чтобы прочитать эту статью. Если вы хотите прочитать больше моих статей, подпишитесь на мою учетную запись, чтобы получать уведомления о выпуске других статей по науке о данных.
 Данные состоят из трех столбцов: c_name — название города, c_state — штат города и coffee_shop_num — количество кофеен в этом городе. *Ниже показана только часть данных*
Данные состоят из трех столбцов: c_name — название города, c_state — штат города и coffee_shop_num — количество кофеен в этом городе. *Ниже показана только часть данных* Используя функцию RANK(), можно получить повторяющиеся рейтинги в разделе и иметь непоследовательные рейтинги, поскольку числа пропускаются после совпадений. Ниже приведен пример функции RANK().
Используя функцию RANK(), можно получить повторяющиеся рейтинги в разделе и иметь непоследовательные рейтинги, поскольку числа пропускаются после совпадений. Ниже приведен пример функции RANK().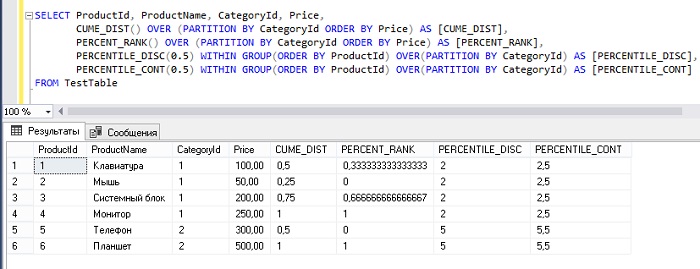 Это можно увидеть в примере кода и выводе ниже, где снова Сан-Диего и Малибу занимают третье место, а следующие город получает ранг 4.
Это можно увидеть в примере кода и выводе ниже, где снова Сан-Диего и Малибу занимают третье место, а следующие город получает ранг 4.
 Совпадения в CUME_DIST() обрабатываются так же, как и в PERCENT_RANK(). Как видно из примера кода и выходных данных ниже, Лос-Анджелес начинается со значения 0,143, а процентиль каждой строки соответствует прибавлению примерно 0,143, а связи соответствуют сумме количества связанных строк. В конечном итоге раздел заканчивается процентилем 1,9.0003
Совпадения в CUME_DIST() обрабатываются так же, как и в PERCENT_RANK(). Как видно из примера кода и выходных данных ниже, Лос-Анджелес начинается со значения 0,143, а процентиль каждой строки соответствует прибавлению примерно 0,143, а связи соответствуют сумме количества связанных строк. В конечном итоге раздел заканчивается процентилем 1,9.0003