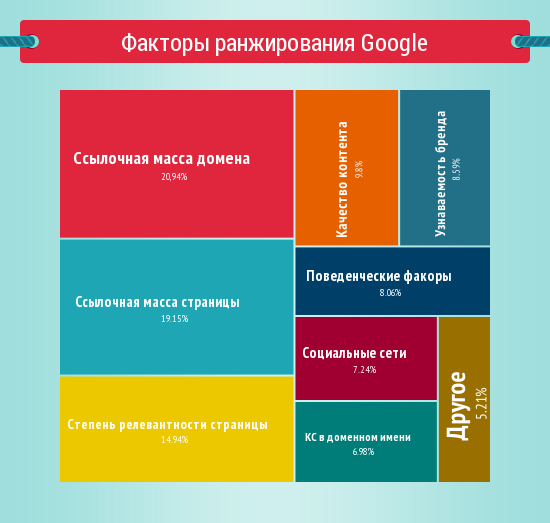
Содержание
Активное обучение ранжированию / Хабр
Этим постом я открываю серию, где мы с коллегами расскажем, как используется ML у нас в Поиске Mail.ru. Сегодня я объясню, как устроено ранжирование и как мы используем информацию о взаимодействии пользователей с нашей поисковой системой, чтобы сделать поисковик лучше.
Задача ранжирования
Что подразумевается под задачей ранжирования? Представим, что в обучающей выборке есть какое-то множество запросов, для которых известен порядок документов по релевантности. Например, вы знаете, какой документ самый релевантный, какой второй по релевантности и т.д. И вам нужно восстановить такой порядок для всей генеральной совокупности. То есть для всех запросов из генеральной совокупности на первое место поставить самый релевантный документ, а на последнее — самый нерелевантный.
Давайте посмотрим, как такие задачи решаются в больших поисковых системах.
У нас есть поисковый индекс — это база из многих миллиардов документов. Когда приходит запрос, мы сначала простыми текстовыми моделями генерируем список кандидатов для финального ранжирования. Самый простой вариант — поднять те документы, в которых в принципе есть слова из запроса. Зачем нужен этот этап? Дело в том, что невозможно для всех имеющихся документов построить признаки и сформировать прогнозирование финальной модели. После мы уже вычисляем признаки. Какие признаки мы можем взять? Например, количество вхождений в документ слов из запроса или число кликов на данный документ. Можно использовать сложные машинно-обученные факторы: мы в Поиске с помощью нейросетей прогнозируем релевантность документа по запросу и вставляем этот прогноз новым столбцом в наше пространство признаков.
Когда приходит запрос, мы сначала простыми текстовыми моделями генерируем список кандидатов для финального ранжирования. Самый простой вариант — поднять те документы, в которых в принципе есть слова из запроса. Зачем нужен этот этап? Дело в том, что невозможно для всех имеющихся документов построить признаки и сформировать прогнозирование финальной модели. После мы уже вычисляем признаки. Какие признаки мы можем взять? Например, количество вхождений в документ слов из запроса или число кликов на данный документ. Можно использовать сложные машинно-обученные факторы: мы в Поиске с помощью нейросетей прогнозируем релевантность документа по запросу и вставляем этот прогноз новым столбцом в наше пространство признаков.
Для чего мы всё это делаем? Мы хотим максимизировать пользовательские метрики, чтобы пользователи как можно проще находили релевантные результаты в нашей выдаче и как можно чаще возвращались к нам.
В нашей финальной модели используется ансамбль деревьев решений, построенный с помощью градиентного бустинга. Есть два варианта построения целевой метрики для обучения:
Есть два варианта построения целевой метрики для обучения:
- Делаем отдел асессоров — специально обученных людей, которым мы даем запросы и говорим: «Ребята, оцените, насколько наша выдача релевантна». Они в ответ будут выдавать числа, оценивающие релевантность. Чем плох такой подход? В данном случае мы будем максимизировать модель относительно мнения людей, которые не являются нашими пользователями. Мы будем оптимизироваться не под ту метрику, которую на самом деле хотим оптимизировать.
- По этой причине мы используем второй подход для целевой переменной: мы показываем пользователям выдачу, смотрим, на какие документы они переходят, какие пропускают. А потом используем эти данные для обучения финальной модели.
Как решается задача ранжирования?
Есть три подхода к решению задачи ранжирования:
- Pointwise, он же поточечный. Мы будем рассматривать релевантность как абсолютное мерило и будем штрафовать модель за абсолютную разность между предсказанной релевантностью и той, которую мы знаем по обучающей выборке.
 Например, асессор поставил документу оценку 3, а мы бы сказали 2, поэтому штрафуем модель на 1.
Например, асессор поставил документу оценку 3, а мы бы сказали 2, поэтому штрафуем модель на 1. - Pairwise, попарный. Мы будем сравнивать документы друг с другом. Например, в обучающей выборке есть два документа, и нам известно, какой из них более релевантный по данному запроса. Тогда мы будем штрафовать модель, если она более релевантному поставила прогноз ниже, чем менее релевантному, то есть неправильно сранжировала пару.
- Listwise. Он тоже основан на относительных релевантностях, но уже не внутри пар: мы ранжируем моделью всю выдачу и оцениваем результат — если на первом месте оказался не самый релевантный документ, то получаем большой штраф.
 Например, асессор поставил документу оценку 3, а мы бы сказали 2, поэтому штрафуем модель на 1.
Например, асессор поставил документу оценку 3, а мы бы сказали 2, поэтому штрафуем модель на 1.
Какой из подходов лучше использовать для выбранной нами целевой переменной? Для этого стоит обсудить важный вопрос: «можно ли использовать клики как мерило абсолютной релевантности документа?». Нельзя, потому что они зависят от позиции документа в выдаче. Получив выдачу, вы, скорее всего, кликните на документ, который будет выше, потому что вам кажется, что первые документы более релевантные.
Получив выдачу, вы, скорее всего, кликните на документ, который будет выше, потому что вам кажется, что первые документы более релевантные.
Как можно такую гипотезу проверить? Берем два документа в топе выдачи и меняем их местами. Если бы клики были абсолютным мерилом релевантности, то их количество зависело бы только от самого документа, а не от позиции. Но это не так. Тот документ, который выше, всегда получает больше кликов. Поэтому клики ни в коем случае нельзя использовать как мерило абсолютной релевантности. Поэтому можно использовать либо pairwise, либо listwise.
Собираем датасет
Теперь извлекаем данные для обучающей выборки. У нас была вот такая сессия:
Из четырёх документов был клик по второму и четвёртому. Как правило, люди смотрят выдачу сверху вниз. Вы посмотрели на первый документ, вам он не понравился, кликнули на второй. Потом вернулись в поиск, посмотрели третий и кликнули на четвертый.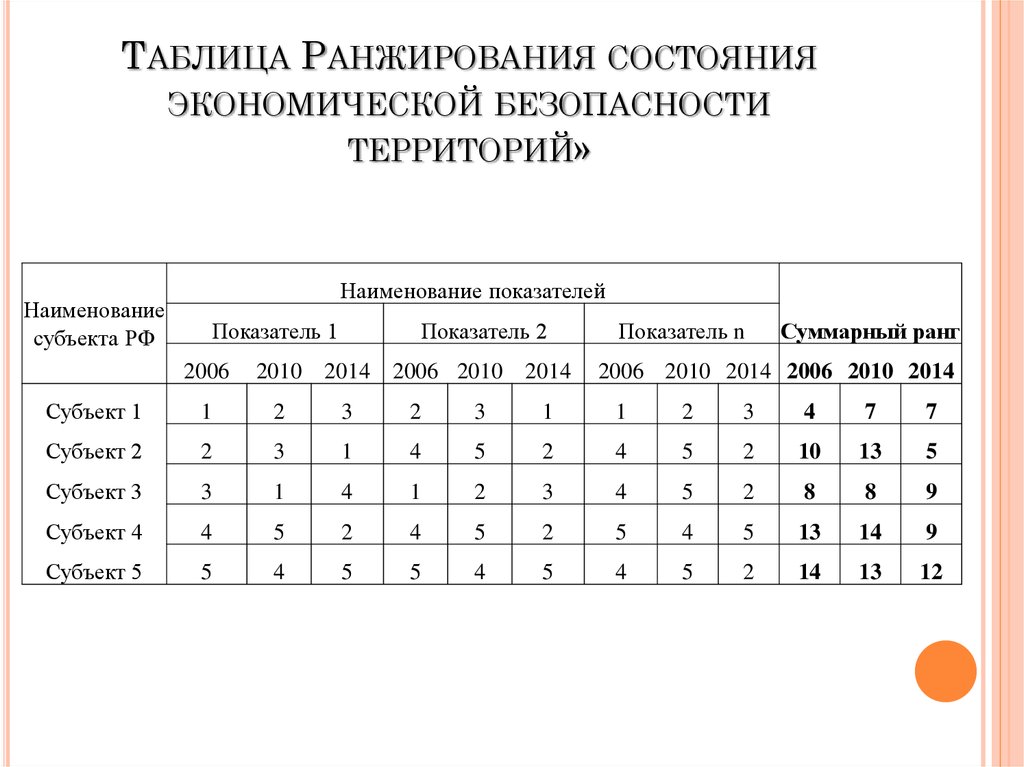 Очевидно, что второй вам понравился больше, чем первый, а четвертый больше, чем первый и третий. Вот такие пары мы генерируем для всех запросов и используем для обучения модели.
Очевидно, что второй вам понравился больше, чем первый, а четвертый больше, чем первый и третий. Вот такие пары мы генерируем для всех запросов и используем для обучения модели.
Вроде бы всё хорошо, но есть одна проблема: люди кликают только на документы из самого верха выдачи. Поэтому, если вы будете делать обучающую выборку только таким образом, то распределение в ней будет совершенно такое же, как в тестовой выборке. Нужно как-то выровнять распределение. Мы делаем это с помощью добавления негативных примеров: это документы, которые были на дне ранжирования, пользователь их точно не видел, но мы знаем, что они плохие.
Итак, у нас получилась такая схема обучения ранжированию: показали пользователям выдачу, собрали с них клики, добавили негативные примеры, чтобы выровнять распределение, и переобучили модель ранжирования. Таким образом, мы учитываем реакцию пользователей на ваше текущее ранжирование, учитываем ошибки и улучшаем ранжирование. Эти процедуры повторяем много раз до сходимости. Важно отметить, что мы ищем не только по вебу, но и по видео, по картинкам, и описанная схема отлично работает в любом виде поиска. В результате очень сильно вырастают поведенческие метрики. Во второй итерации чуть поменьше, в третьей итерации еще меньше, и в итоге сходится к локальному оптимуму.
Эти процедуры повторяем много раз до сходимости. Важно отметить, что мы ищем не только по вебу, но и по видео, по картинкам, и описанная схема отлично работает в любом виде поиска. В результате очень сильно вырастают поведенческие метрики. Во второй итерации чуть поменьше, в третьей итерации еще меньше, и в итоге сходится к локальному оптимуму.
Давайте подумаем, почему же мы сходимся в локальный оптимум, а не в глобальный.
Допустим, вы футбольный фанат и вечером не успели посмотреть матч своей любимой команды. Утром просыпаетесь и вводите в поисковую строку название команды, чтобы узнать результат матча. Смотрите первые три документа — это официальные страницы о клубе, тут нет полезной информации. Вы не будете листать всю выдачу, не будете подбирать другой запрос. Возможно, вы даже кликните на какой-нибудь нерелеватный документ. Но в результате расстроитесь, закроете выдачу и откроете другой поисковик.
Хотя эта проблема встречается не только в поиске, здесь она особенно актуальна. Представьте интернет-магазин, который представляет собой одну большую ленту без возможности сказать, какую именно категорию товаров вы хотите посмотреть. Именно это происходит с поисковой выдачей: после отправки запроса вы уже никак не можете пояснить, что вам на самом деле нужно: информацию о футбольной команде или счёт последнего матча.
Представьте интернет-магазин, который представляет собой одну большую ленту без возможности сказать, какую именно категорию товаров вы хотите посмотреть. Именно это происходит с поисковой выдачей: после отправки запроса вы уже никак не можете пояснить, что вам на самом деле нужно: информацию о футбольной команде или счёт последнего матча.
Представим, что какой-нибудь брутальный мужчина зашёл в такой странный интернет магазин, состоящий из одной ленты рекомендаций, и в своих рекомендациях он видит только типично женские товары. Возможно, он даже кликнет на какое-нибудь платье, потому что оно надето на красивую девушку. Мы этот клик отправим в обучающее множество и решим, что мужчине это платье нравится больше, чем спонж. Когда он снова приходит в нашу систему, он уже увидет одни платья. У нас изначально не было товаров, валидных для пользователя, поэтому такой подход не позволит нам эту ошибку исправить. Мы попали в локальный оптимум, в котором бедный человек уже не может нам рассказать, что ему не нравятся ни спонжи, ни платья. Часто эту проблему называют проблемой положительной обратной связи.
Часто эту проблему называют проблемой положительной обратной связи.
Дальнейшее совершенствование
Как сделать поисковую систему лучше? Как выбраться из локального оптимума? Нужно добавлять новые факторы. Допустим, мы сделали очень хороший фактор, который поднимет по запросу с названием футбольной команды релевантный документ, то есть результаты последнего матча. В чем здесь может быть проблема? Если вы обучаете модель на старых данных, на офлайн-данных, то берете старый датасет с кликами и добавляете туда этот признак. Возможно, он релевантный, но вы раньше не использовали его в ранжировании, и поэтому люди не кликали на те документы, по которым этот признак хорош. Он не коррелирует с вашей целевой переменной, поэтому просто не будет использоваться моделью.
В подобных случаях мы часто используем такое решение: в обход финальной модели заставляем наше ранжирование использовать этот признак. Мы насильно показываем по запросу с названием команды результат последнего матча, и если пользователь кликнул на него, то для нас это та информация, которая позволяет понять, что признак хороший.
Давайте разберем это на примере. Недавно мы сделали красивые картинки для документов с Instagram:
Кажется, что такие красивые картинки должны максимально удовлетворять наших пользователей. Очевидно, нам нужно сделать признак наличия у документа такой картинки. Добавляем в датасет, переобучаем модель ранжирования и смотрим, как этот признак используется. А потом анализируем изменение поведенческих метрик. Они немного улучшились, но оптимальное ли это решение?
Нет, потому что по многим запросам вы не показываете красивые картинки. Вы не давали пользователю возможность показать, как они ему нравятся. Чтобы решить эту проблему, мы по некоторым запросам, которые предполагают показ Instagram-документов, принудительно в обход модели показывали красивые картинки и смотрели, кликают ли на них. Как только пользователи оценили нововведение, то стали переобучать модель на датасетах, в которых у пользователей была возможность показать важность этого фактора. После этой процедуры на новом датасете фактор стал использоваться во много раз чаще и значительно повысил пользовательские метрики.
Итак, мы рассмотрели постановку задачи ранжирования и обсудили подводные камни, которые вас будут поджидать при обучении на обратной связи от пользователей. Главное, что вам стоит вынести из этой статьи: используя обратную связь в качестве таргета для обучения, помните, что этот фидбек пользователь сможет оставить только там, где ему это позволит текущая модель. Такая обратная связь может сыграть с вами злую шутку при попытке построить новую модель машинного обучения.
Вопрос с ранжированием | SurveyMonkey Help
СТАТЬЯ
В вопросе с ранжированием респондентов просят сравнить элементы между собой, разместив их в порядке предпочтения. В разделе «Анализ результатов» для каждого варианта ответа вычисляется среднее ранжирование, позволяя быстро оценить наиболее предпочитаемый вариант.
Обзор видео
Создание вопроса с ранжированием
Как добавить вопрос такого типа
- В разделе «КОНСТРУКТОР» перетащите в свой опрос элемент Ранжирование.
- В поле текста вопроса введите инструкции, указывающие респондентам проранжировать варианты ответа в порядке предпочтения (где 1 – самая высокая позиция). Рекомендуется также объяснить, что общего имеют между собой все доступные варианты ответа. Например: «Расположите вкусы мороженого в порядке предпочтения (где 1 – Ваш любимый вкус)».
- В полях вариантов ранжирования введите варианты ответов, по которым следует ранжировать респондентов. Вы можете добавить до 250 вариантов ответов.
- При необходимости задайте другие дополнительные параметры.
- Нажмите кнопку Сохранить.
Добавление варианта «Неприменимо»
На вкладке Редактировать вы можете добавить столбец «Неприменимо» и настроить метку. При добавлении параметра «Не указано» в вопрос с ранжированием, в конец каждой строки добавляется флажок «Не указано». Если респондент выбирает флажок «Не указано», эта строка становится серой и не будет включаться в порядок ранжирования для данного респондента.
Важно убедиться, что к респонденту применяются даже варианты с самым низким рангом. Если у респондента нет возможности заявить, что элемент ранжирования к нему не относится, ему придется все равно выполнить ранжирование, что может привести к искажению данных.
Характеристика прохождения опроса
Перед отправкой опроса необходимо выполнить предварительный просмотр его схемы, чтобы проверить, как будет выглядеть опрос для респондентов.
Респонденты могут отвечать на вопросы с ранжированием двумя способами:
- Перетаскивать варианты ответа в соответствии со степенью предпочтения.
- В раскрывающихся меню выбирать числовое значение ранга для каждого варианта ответа.
Анализ результатов
Ознакомьтесь с примерами результатов (только на английском языке) »
Среднее ранжирование
В вопросах с ранжированием для каждого варианта ответа рассчитывается среднее ранжирование, позволяя определить, какой из вариантов ответа был наиболее предпочитаемым для респондентов. Вариант ответа с самым высоким средним ранжированием является самым предпочитаемым ответом среди респондентов.
Вариант ответа с самым высоким средним ранжированием является самым предпочитаемым ответом среди респондентов.
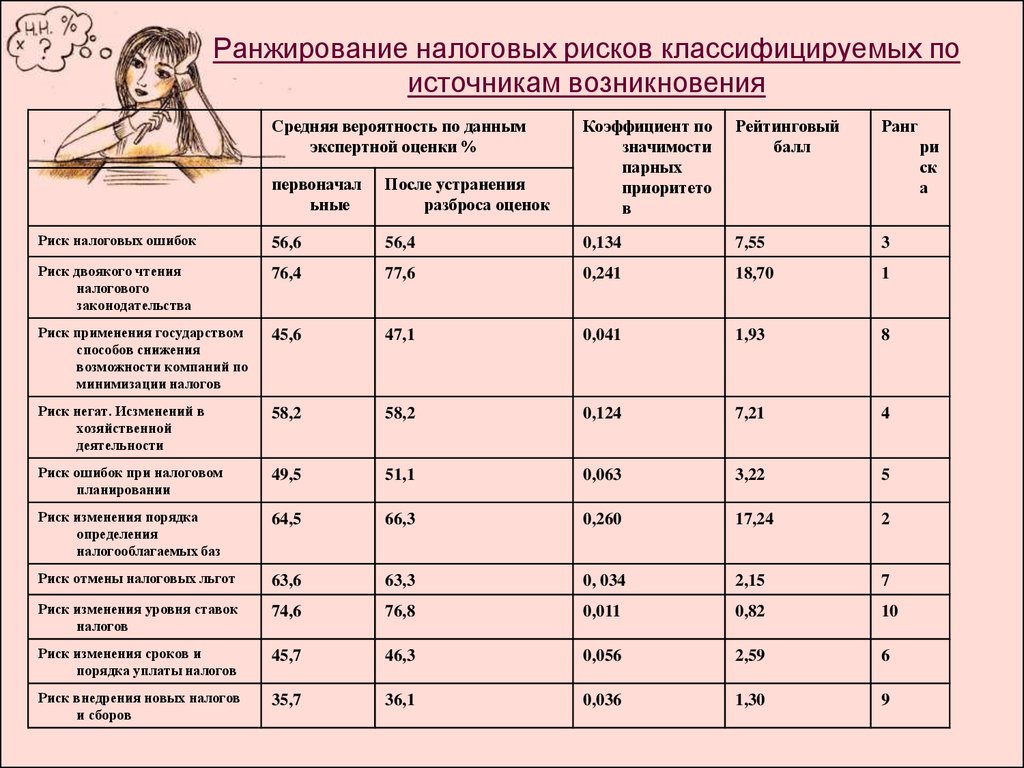
Среднее ранжирование рассчитывается по следующей формуле, где:
w = весовой коэффициент ранга
x = кол-во ответов для варианта ответа
1w1 + x2w2 + x3w3 … xnwn
————————
Общее количество ответов
Весовой коэффициент прямо пропорционален среднему значению ранжирования. Другими словами, самый предпочитаемый среди респондентов вариант ответа (ранг которого равен единице) имеет наибольший весовой коэффициент, а наименее предпочитаемый вариант ответа (с рангом, равным номеру последней позиции) имеет весовой коэффициент, равный единице. Весовой коэффициент по умолчанию изменить нельзя.
Например, если вопрос с ранжированием имеет 5 вариантов ответов, значения весового коэффициента для этих ответов распределяются следующим образом:
- Вариант ответа с рангом, равным 1, имеет весовой коэффициент, равный 5
- Вариант ответа с рангом, равным 2, имеет весовой коэффициент, равный 4
- Вариант ответа с рангом, равным 3, имеет весовой коэффициент, равный 3
- Вариант ответа с рангом, равным 4, имеет весовой коэффициент, равный 2
- Вариант ответа с рангом, равным 5, имеет весовой коэффициент, равный 1
Мы присваиваем вариантам ответов значения весового коэффициента именно таким образом, чтобы во время представления собранных данных в виде таблицы было ясно, какой из вариантов ответов является наиболее предпочитаемым.
Если в вопрос с ранжированием включен вариант ответа «Неприменимо», такие ответы не будут учитываться при определении среднего ранжирования.
Диаграммы
Для параметра отображения «Глубина» можно выбрать один из перечисленных ниже вариантов.
- Взвешенное среднее значение: на диаграмме отображается среднее значение ранжирования для каждого варианта ответа.
- Распространение: на диаграмме отображается абсолютное или процентное количество респондентов, которые выбрали каждый вариант ответа
Доступные типы диаграммы зависят от типа вопроса и настроенных вами параметров отображения. Подробнее: Пользовательские диаграммы и таблицы данных
Брок Пурди из команды 49ers входит в число 25 лучших после захватывающего финиша в регулярном сезоне 2022 года
Поскольку регулярный сезон НФЛ 2022 года находится в планах, бывший скаут НФЛ Дэниел Джеремайя просмотрел свои записи за всю кампанию, чтобы составить рейтинг 25 лучших новичков.
Соус Гарднер
Нью-Йорк Джетс · CB
СОСТАВ: Раунд 1, № 4 в общем зачете
Соус – самый впечатляющий новичок в этом классе. Есть причина, по которой он заслужил награду стартового турнира Pro Bowl.
Ранг
2
3
Эйдан Хатчинсон
Детройт Лайонс · DE
СОЗДАНИЯ: раунд 1, № 2 В целом
Хатчинсон действительно появился во второй половине сезона, отделка с 9.5 Кралами. (больше всего среди новичков). Как пас-рашер, он продемонстрировал несколько способов добраться до квотербека. Он привнес много энергии в возрождающуюся команду Lions.
Ранг
3
1
Гаррет Уилсон
«Нью-Йорк Джетс» · WR
СОСТАВ: Раунд 1, № 10 в общем зачете
Уилсон лидировал среди всех новичков с 1103 ярдами на приеме, несмотря на очень нестабильную ситуацию с квотербеком. Он может быть на грани монстра 2-го года, если Джетс найдут решение под центром.
Место в рейтинге
4
1
Крис Олав
New Orleans Saints · WR
НАРАБОТАН: с 1042 приемными ярдами — соответствовал его заявлению новичка. Он был шелковисто гладким, полированным и продуктивным.
Ранг
5
1
Tariq Woolen
Сиэтл Сихокс · CB
Сделано: раунд 5, № 153 в целом
Woolen опубликовано в роли. перехваты. «Сихоукс» проделали замечательную работу, найдя его на драфте.
Ранг
6
1
Кеннет Уокер III
Сиэтл Сихокс · РБ
ПОДГОТОВЛЕН: Раунд 2, № 41 в общем зачете
Уокер — хоумран, но он может и на крутых ярдах. Он лидировал среди всех новичков, пробежав 1050 ярдов, и это главная причина возвращения Сиэтла в постсезон.
Ранг
7
NR
Brock Purdy
Сан -Франциско 49ers · QB
. но это впечатляет. Он шокировал кадровое сообщество тем, насколько хорошо он играл, помогая направлять 49Нападение игроков после травм Трея Лэнса и Джимми Гаропполо.
Rank
8
4
Jalen Pitre
Houston Texans · S
ПОДГОТОВЛЕН: Раунд 2, № 37 в общем зачете Pitre
5 90. Он играет быстро и лидирует среди всех новичков, сделав 147 отборов мяча. Я думаю, что он будет постоянным профессиональным боулером.
Ранг
9
3
Дэмеон Пирс
Хьюстон Тексанс · РБ
НАДРАБОТАНО: Раунд 4, № 107 в общем зачете
Из-за травмы лодыжки Пирс выбыл из игры в последний месяц регулярного сезона, но в год своего новичка он зарекомендовал себя как один из лучших бегунов лиги.
Ранг
10
7
Джордж Карлафтис
Канзас -Сити Кеждцы · DE
Сделано: раунд 1, № 30 в целом
Он играл так же, как и любой защитник -роужи за последние семь недель
. сезон с 5,5 мешками за этот период.
Ранг
11
7
Кайвон Тибодо
Нью-Йорк Джайентс · OLB
НАРАБОТАН: Раунд 1, № 5 он получает больше опыта,
25 Вы видите, как растет его уверенность.

Ранг
12
3
Кристиан Уотсон
Green Bay Packers · WR
. Сделано: раунд 2, № 34 В целом
Watson был машиной приземления для упаковщиков, забитые восемь раз по 10 недель. до 13. Он оправился от тяжелого начала сезона, чтобы играть по-крупному в важные моменты.
Ранг
13
5
IKEM EKWONU
Carolina Panthers · OT
Сделано: раунд 1, № 6 в целом
Бывшая штата Н.С. начал проявляться по ходу сезона. Он сокрушительный блокировщик рывков и стал лучше как защитник паса.
Ранг
14
3
Девин Ллойд
Джексонвилл Джагуарс · LB
СОСТАВ: Раунд 1, 27-е место в общем зачете
Ллойд, как и было заявлено, вышел из Юты, наполнив таблицу статистики 115 отборами мяча, тремя перехватами и двумя восстановленными нащупываниями. Он является строительным материалом для молодой защиты «Ягуаров».
Ранг
15
1
Travon Walker
Jacksonville Jaguars · OLB
Сделано: раунд 1, № 1 в целом
Его лучший футбол еще впереди, но мы видели Мямовые в отставке. на протяжении всего сезона, включая доминирующее выступление на прошлой неделе в решающей победе в дивизионе над Титанами.
на протяжении всего сезона, включая доминирующее выступление на прошлой неделе в решающей победе в дивизионе над Титанами.
Ранг
16
3
Drake London
Атланта Соколы , физическая сила и навыки игры с мячом очень хорошо перешли в профессионалы.
Ранг
17
7
Джордж Пикенс
Питтсбург Стилерс · WR
ПОДГОТОВЛЕН: Раунд 2, № 52 в общем зачете
Бывший выдающийся игрок Джорджии выглядит как будущий ресивер номер один. Он сыграл свою долю в вау- играх и стал более стабильным по ходу сезона.
Ранг
18
NR
Tyler Smith
Dallas Cowboys · OT
Сделано: раунд 1, № 24 в целом
Есть кое -что, что можно сказать для Manning Left Spate Spot для ковбоев и и и
. выполнение под давлением, которое приходит с работой. Я думал, что Смит выдержал хорошо. Он по-прежнему лучше блокирует выносы, чем защитник пасов, но, судя по тому, что мы видели в этом сезоне, у него есть много преимуществ.
Ранг
19
3
Тайлер Линдербаум
Baltimore Ravens · C
ПОДГОТОВЛЕН: Раунд 1, очень надежный № 25 в целом
5 Он мог бы стать якорем линии нападения Балтимора на следующее десятилетие.
Ранг
20
NR
Керби Джозеф
Детройт Лайонс · S
ПОДГОТОВЛЕН: Раунд 3, № 97 в общем зачете, в NFL
Джозеф перевел много мяча в колледж, кульминацией стал перехват на 18-й неделе против Packers, который поставил под сомнение надежды Грин-Бей на выход в плей-офф.
Ранг
21
3
Джеймс Хьюстон
Детройт Лайонс · OLB
Сделано: раунд 6, № 217. дело доходит до торопливого прохожего. Он возглавил лигу с процентом мешков 9,2 согласно статистике Next Gen Stats (минимум 75 быстрых снимков). Я взволнован, чтобы увидеть, что он может сделать в следующем сезоне с полным количеством повторений.
Ранг
22
NR
Тайлер Алгейер
Atlanta Falcons · RB
НАНЕСЕНИЕ: Раунд 5, № 151 в общем зачете
Аллгейер – бегун-наказатель. Согласно статистике Next Gen Stats, ни у одного защитника-новичка не было больше ярдов, чем ожидалось (154).
Согласно статистике Next Gen Stats, ни у одного защитника-новичка не было больше ярдов, чем ожидалось (154).
Ранг
23
NR
Kenny Pictett
Питтсбург Стилерс · QB
Сделано: раунд 1, № 20 в целом
Pickett сделал большие игры в больших местах, чтобы помочь в завершении Стилеров. 500. Его постановка не выпрыгнет из поля зрения, но он сыграл хорошо. Я с нетерпением жду возможности увидеть, как «Питтсбург» будет развиваться вокруг него.
Ранг
24
1
Jamaree Salyer
Los Angeles Chargers · OT
Сделано: раунд 6, № 195 в целом
Это, вероятно, гиперболический , что надуманные. Он укрепил позицию левого тэкла после того, как Рашон Слейтер получил травму бицепса, из-за которой он не выходил на поле с конца сентября.
Ранг
25
3
Малькольм Родригес
Детройт Лайонс · LB
СОСТАВ: Раунд 6, № 188 в общем зачете
Еще одна жемчужина драфт-класса Львов, Родригес впечатлил своей интуицией, скоростью и дальностью полета. Этот список с четырьмя представителями «Детройта» подчеркивает, почему при таком режиме у «Львов» такое яркое будущее.
Этот список с четырьмя представителями «Детройта» подчеркивает, почему при таком режиме у «Львов» такое яркое будущее.
Подписывайтесь на Дэниела Джереми в Твиттере.
Рейтинг Возможные соперники Eagles в раунде дивизиона
Eagles заработали посев № 1 в NFC и прощальную неделю, которая приходит с ним.
Так что в эти выходные они ждут.
Они будут смотреть три игры NFC, желая узнать своего соперника в матче дивизионного раунда, который они проведут на следующих выходных. Самый низкий посев для продвижения будет в Филадельфии на следующих выходных.
Напоминаем, что это расписание NFC на эти выходные:
Суббота в 16:30: № 7 Seahawks на № 2 49ers
Воскресенье 16:30: № 6 Giants на № 3 Vikings
Понедельник, 20:15: Ковбои № 5 в Буканьерах № 4
В дивизионном раунде у Орлов есть четыре возможности. Они будут играть за «Бакс», «Ковбоев», «Джайентс» или «Сихокс». Единственные две команды, о которых мы знаем, что они не сыграют в следующие выходные, — это 49ers и Vikings, потому что они никак не могут быть самыми низкими оставшимися посевными.
Независимо от того, какая команда приедет в Филадельфию на следующих выходных, предпочтение будет отдано «Иглз». И не попасть на матч чемпионата NFC было бы большим разочарованием.
Имея все это в виду, давайте ранжируем четыре возможности от наилучшего до наихудшего сценария:
№ 7 «Сихокс» (9–8): «Сихоукс» смогли выйти в плей-офф с результатом 9–8 благодаря победе «Лайонс» над «Пэкерс» в Sunday Night Football. Из этих трех команд «Сихоукс» — самая легкая ничья. Трудно представить, что они поедут в Сан-Франциско и победят 49ers, поэтому такая возможность кажется надуманной. Но случаются сумасшедшие вещи. И мало того, что «Сихоукс» — самая слабая команда в плей-офф NFC, но если они приедут в Филадельфию, это значит, что они уже победили самую большую угрозу в конференции. Вот почему это явно лучший сценарий. Получение 49Если бы они ушли с дороги, это действительно открыло бы ситуацию.
Что касается самих «Сихоукс», то они начали сезон со счетом 6-3, а затем стали 1-6..jpg) Отдайте им должное за то, что они обыграли «Джетс» и «Рэмс» за последние две недели и вышли в плей-офф, но это не очень страшная команда, и они в значительной степени полагаются на молодых игроков без опыта плей-офф. И каким бы замечательным ни был год искупления Джено Смита, трудно представить, что он приедет в Филадельфию и уйдет с победой; его игра остановилась во второй половине сезона. «Сихокс» занимают 13-е место в НФЛ в нападении и 26-е в защите. Они также были ужасно против бегства. Они занимают 30-е место в НФЛ, а у «Иглз» одна из лучших O-линий в лиге. Сиэтлу будет трудно их остановить, особенно если Джален Хёртс близок к 100 процентам.
Отдайте им должное за то, что они обыграли «Джетс» и «Рэмс» за последние две недели и вышли в плей-офф, но это не очень страшная команда, и они в значительной степени полагаются на молодых игроков без опыта плей-офф. И каким бы замечательным ни был год искупления Джено Смита, трудно представить, что он приедет в Филадельфию и уйдет с победой; его игра остановилась во второй половине сезона. «Сихокс» занимают 13-е место в НФЛ в нападении и 26-е в защите. Они также были ужасно против бегства. Они занимают 30-е место в НФЛ, а у «Иглз» одна из лучших O-линий в лиге. Сиэтлу будет трудно их остановить, особенно если Джален Хёртс близок к 100 процентам.
Гиганты № 6 (9-7-1): Хитрость гигантов в том, что это будет третья встреча между двумя командами, и не обязательно легко обыграть одну и ту же команду три раза в тот же сезон. Однако та игра на 18-й неделе между «Иглз» и «Джайентс» была странной, и я не стал бы в нее особо вникать. Хотя эта игра, вероятно, была слишком близкой для комфорта, у «Иглз» был ограниченный квотербек, и они сделали то, что им нужно было сделать, чтобы выиграть у резервных копий «Джайентс». И если бы они были чуть лучше в красной зоне — они были 1 к 5 — эта игра могла бы выглядеть совсем по-другому. Если не считать этой игры, «Иглз» весь сезон играли фантастически в составе 20.
И если бы они были чуть лучше в красной зоне — они были 1 к 5 — эта игра могла бы выглядеть совсем по-другому. Если не считать этой игры, «Иглз» весь сезон играли фантастически в составе 20.
Гиганты играют жестко, а это значит, что Орлы могут не победить. Но в плей-офф такого ожидать не приходится. И, увидев «Джайентс» в течение сезона (помните игру со счетом 48–22?), стало ясно, что «Иглз» просто лучшая команда. Теперь, могут ли «Иглз» проиграть, если они перевернут мяч и сделают тупоголовые ошибки? Конечно. Но они могут проиграть кому угодно, если это произойдет. Я думаю, что они чувствовали бы себя довольно уверенно, входя в эту игру, чувствуя, что они просто лучшая команда, и они были бы правы.
Буканьеры № 4 (8-9): Том Брэди. Вот что вас пугает в Баках. Дело в том, что вы беспокоитесь, что Брэди вдруг снова превратится в лучшую версию КОЗЛА и набросится на вас. И, возможно, этот страх не совсем беспочвенный, особенно если «Бак» уже продвинулся вперед. Я перестал считать Брейди еще до того, как он ушел на пенсию. Но эта команда «Бакс» не была хороша весь сезон. Они изо всех сил старались не выиграть самый дрянной дивизион в лиге и закончили сезон на 25-м месте по набранным очкам, хотя мы видели еще некоторые признаки жизни в этом нападении, когда Крис Годвин и Майк Эванс вошли в ритм совсем недавно.
Я перестал считать Брейди еще до того, как он ушел на пенсию. Но эта команда «Бакс» не была хороша весь сезон. Они изо всех сил старались не выиграть самый дрянной дивизион в лиге и закончили сезон на 25-м месте по набранным очкам, хотя мы видели еще некоторые признаки жизни в этом нападении, когда Крис Годвин и Майк Эванс вошли в ритм совсем недавно.
В обороне «Бакс» в плей-офф в прошлом году обыграли «Хёртс» и «Иглз». В тот день они преследовали Хёртса, и на него давили. Но в этом году Hurts — совершенно другой игрок; гораздо удобнее в нападении и в блице. И защита «Бакс» тоже не такая. Фактически, они потеряли более 30 очков в трех из последних пяти игр. С Шакилом Барреттом в IR, этот пас Бакс просто не имеет такого же сока.
Ковбои № 5 (12-5): Вы думали, что на 18-й неделе «Иглз» плохо выступили? Вы видели Ковбоев. Теоретически им еще было за что играть, и они подложили яйца против Командиров. Дак Прескотт был ужасен, выполнив 14 передач из 37 и забросив еще один пик-6.