Содержание
Алгоритмы ранжирования Яндекса 2021 — Обзор санкций и фильтров Яндекс
Запуск поисковой системы «Яндекс» состоялся в 1996 году, а уже в 1997 году она стала доступна широкому кругу пользователей. На тот момент им было проиндексировано 5000 сайтов с общим объёмом информации 4 Гб.
Сейчас количество сайтов исчисляется миллионами. Поиск работает по сложным алгоритмам и выдаёт наиболее подходящие конкретному человеку результаты. Мы сделали обзор всех основных поисковых алгоритмов Яндекса и возможных санкций для владельцев сайтов, которые были выпущены и внедрены за последние 10 лет.
Как менялись алгоритмы ранжирования Яндекса с 2010 по 2020
После запуска в 1997 году система могла выдавать информацию по запросу, определять уникальность и предлагать только 1 копию текста в выдачу, был введён первый алгоритм ранжирования. Популярность интернета росла, он стал доступнее, поэтому в 2007 году Яндекс увеличил число факторов ранжирования, чтобы сделать выдачу более качественной. Примерно в это время начали появляться SEO-специалисты, которые искали, как обойти алгоритмы поисковой системы и продвинуть сайты, качество которых не соответствовало требованиям Яндекса.
Примерно в это время начали появляться SEO-специалисты, которые искали, как обойти алгоритмы поисковой системы и продвинуть сайты, качество которых не соответствовало требованиям Яндекса.
В 2008 появились первые фильтры на накрученные ссылки, приоритет стал отдаваться авторитетным сайтам. Начал действовать и был усовершенствован алгоритм «Магадан»: расширена база синонимов, по которым определялась релевантность контента запросам, стал цениться уникальный контент. У Яндекса появился тезаурус — словарь с лексическими значениями всех слов языка.
Яндекс в 2008 году
С 2009 года новые поисковые алгоритмы Яндекса стали учитывать регион расположения пользователя и несколько раз усовершенствовали эту функцию в рамках «Арзамаса». Они стали отличать омонимы друг от друга, то есть слова, которые схожи по написанию или звучанию, но отличаются по смыслу. Например, если пользователь ищет замок в Германии, поисковая система не станет предлагать ему услуги по смене дверного замка, а сразу покажет достопримечательности. После этого был запущен алгоритм «Снежинск» на основе машинного обучения MatrixNet, который увеличил число факторов ранжирования Яндекса в несколько раз.
После этого был запущен алгоритм «Снежинск» на основе машинного обучения MatrixNet, который увеличил число факторов ранжирования Яндекса в несколько раз.
Схема работы MatrixNet
2010 — Новая обработка запросов
В 2010-м году было решено усовершенствовать поисковые алгоритмы Яндекса по обработке запросов. Внедрен алгоритм «Конаково». Он был направлен на улучшение распознавания геонезависимых запросов.
Улучшения коснулись и «Снежинска». В марте у него обновились формулы для запросов, не зависящих от геолокации.
В сентябре «Конаково» становится «Обнинском». Это масштабное обновление увеличило число факторов ранжирования Яндекса для геонезависимых запросов, увеличило производительность поисковой системы и привело к перенастройке формулы.
В конце этого года — 15 декабря, выходит алгоритм «Краснодар» с использованием технологии «Спектр». Это сделало выдачу разнообразнее. Запросы пользователей стали восприниматься не только по значению поисковых слов, но и по общему смыслу. Усилилась локализация по запросам, связанным с геолокацией. Выдача стала более релевантной.
Усилилась локализация по запросам, связанным с геолокацией. Выдача стала более релевантной.
2011 — Первые шаги к персонализации выдачи
В 2011-м году стало понятно, что пользователи могут искать разные вещи, формулируя одинаковый запрос. Специалисты Яндекса создали алгоритм «Рейкьявик». Он учитывает язык, на котором в основном читает или ищет информацию пользователь. Это был первый шаг на пути к современной персонализированной выдачи.
2012 — Учёт долгосрочных интересов
Работа по персонализации выдачи продолжилась. Яндекс запустил обновление «Калининград». Оно содержало привычные всем сейчас подсказки в поисковой строке. Выдача стала формироваться с учётом долгосрочных интересов пользователя и наиболее посещаемых им сайтов. Это позволяло наиболее точно удовлетворить запрос конкретного человека.
2013 — Персонализация в моменте
Дальнейшее улучшение персонализации выдачи велось в сторону учёта краткосрочных интересов пользователей. Для этого был разработан алгоритм «Дублин».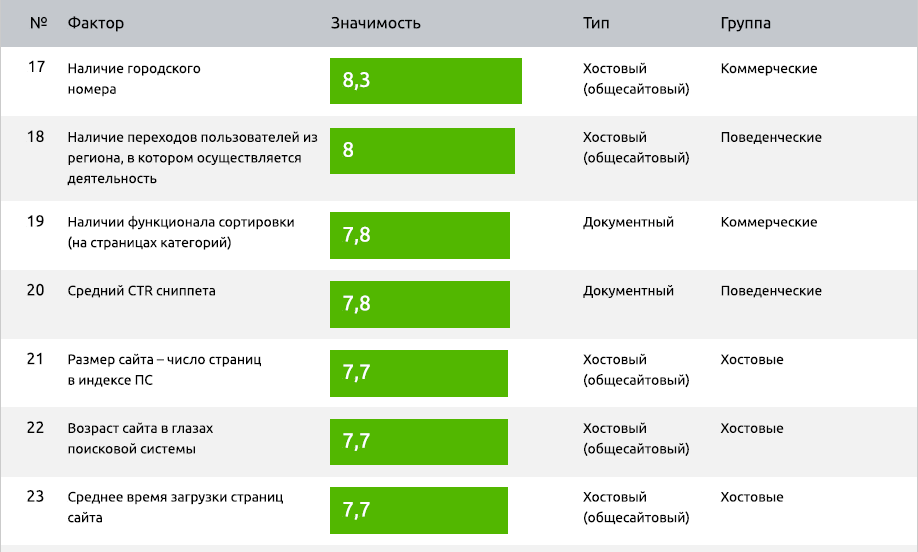 Результаты выдачи корректировались под конкретного человека непосредственно во время поисковой сессии.
Результаты выдачи корректировались под конкретного человека непосредственно во время поисковой сессии.
2014 — Новый дизайн, новые правила
В марте 2014 года начал работу алгоритм «Без ссылок». Он прекратил учёт ссылок и некоторых ссылочных факторов для нескольких групп коммерческих запросов, но пока только в Московском регионе.
Обновление «Острова» полностью изменило интерфейс выдачи. В нём появились интерактивные блоки, содержание которых устанавливали владельцы сайта. Там располагались сервисы бронирования, указывали цены и другую информацию об услугах. Эксперимент с дизайном не оправдал ожиданий и был признан неуспешным.
Яндекс Острова довольно быстро «утонули»
2015 — Время ссылок
Специалисты Яндекса вернулись к идее ответа на запрос без захода на сайт, но модифицировали её. Появился проект «Объективный ответ», действующий до сих пор. Это карточка, которая появляется с правой стороны выдачи. Она содержит общую информацию, отвечающую на запрос пользователя.
Ещё один ныне действующий алгоритм из 2015-го — «Минусинск». Он понижает позиции сайтов, на которых расположено слишком много SEO-ссылок. Это сделало почти невозможным накрутку позиций с помощью массовой закупки ссылок. Одновременно с этим в ранжировании снова обрели вес ссылочные факторы.
В сентябре запустили ещё один алгоритм — «Многорукие Бандиты Яндекса». Он поднимал в ТОП один сайт из низа выдачи, информация на котором по мнению роботов наиболее отвечала запросу пользователя. После этого собиралась информация для оценки поведенческих факторов. Если результаты были хорошие, сайт закреплялся в ТОПе по конкретному запросу или существенно поднимался в выдаче. При незначительных изменениях поведенческих факторов позиции могли немного ухудшиться. Если сайт показывал плохие результаты, он стремительно опускался вниз. Это заставляло всех владельцев сайтов выдавать контент высокого качества, если они не хотели пропасть из выдачи.
2016 — Мобильные устройства и нейросети
Стремясь не отставать от Google и его Mobile-friendly, Яндекс запускает «Владивосток». Алгоритм учитывает при ранжировании адаптивность сайта для мобильных устройств. Такие сайты получали самые высокие позиции в мобильной выдаче.
Алгоритм учитывает при ранжировании адаптивность сайта для мобильных устройств. Такие сайты получали самые высокие позиции в мобильной выдаче.
С ноября на службе Яндекса появляется нейросеть. Проект «Палех» отслеживает соответствие семантики сайта и его метатегов запросу пользователя, что ещё больше улучшает выдачу. Сеть также умеет распознавать содержимое документов и сопоставлять его с искомой человеком информацией. Теперь поисковая система может разговаривать на естественном человеческом языке. Также повысилось качество выдачи для редких запросов.
Принцип работы алгоритма «Палех»
2017 — Тексты для людей
В конце марта в факторы ранжирования поисковой системы Яндекс был встроен алгоритм «Баден-Баден». Он находит и понижает в выдаче сайты, в текстах которых слишком много ключевых слов. Качество контента становится важнее, чем соответствие требованиям роботов.
Конец лета ознаменовался выпуском алгоритма «Королёв», который стал продолжением «Палеха». Теперь анализируются не только метатеги и заголовки, а весь контент на странице. Это тоже положительно сказывается на качестве контента.
Теперь анализируются не только метатеги и заголовки, а весь контент на странице. Это тоже положительно сказывается на качестве контента.
2018 — Удобство превыше всего
Ноябрь принёс обновление «Андромеда». Оно коснулось как поисковой выдачи, так и сервисов Яндекса. Теперь искать ответ можно не только в строке с поиском, но и среди «Коллекций», например, в картинках.
Улучшения коснулись и быстрых ответов. Пользоваться ими стало ещё удобнее. Теперь в них выводят не только небольшие факты, но и анонсы фильмов, наличие билетов в нужном направлении, счёт текущих футбольных матчей и многое другое.
Изменился алгоритм ранжирования: на первое место встало решение задач пользователей. Система также стала оценивать долю лояльной аудитории, а также соотношение полезного и навязчивого контента. Для наглядной демонстрации пользователям качества сайта были введены значки:
- «Официальный сайт» — подтверждает, что это официальный сайт организации;
- «Выбор пользователей» — присваивается за лояльную аудиторию;
- «Популярный сайт» — выдаётся при большой посещаемости и постоянной аудитории.

Специальные метки для сайтов в поисковой выдаче Яндекса
2019 — Всё и сразу
В декабре под конец года выходит масштабное обновление — «Вега». Оно затронуло сразу несколько направлений.
Во-первых, документы в базе хранения теперь разбиты на смысловые кластеры. Так роботам проще их индексировать и сложнее что-то пропустить, а людям намного быстрее находятся нужные страницы. Сама же база из-за этого выросла в 2 раза.
Во-вторых, поисковая выдача сразу генерируется под запрос, который с большей вероятностью интересует конкретного пользователя. Это ускоряет загрузку результатов.
В-третьих, в асессоры Яндекс набрали экспертов различных тематик. Так качество выдачи в темах, где особенно важна экспертность, стало значительно выше.
В-четвёртых, расположение пользователя теперь учитывается не только с учётом города, но и конкретного района. Подбирать места для отдыха или оказания бытовых услуг теперь намного проще.
Новые поисковые алгоритмы Яндекса 2020-2021 гг.
Осень 2020 года ушла на запуск алгоритма YATI, что расшифровывается как Yet Another Transformer (with Improvements). За него работают мощные нейросети, которые отдают предпочтение наиболее релевантным запросу страницам и сайтам. При этом возраст домена, количество главных страниц и размер контента становятся на второй план.
Запуск YATI по мнению Яндекса считается лучшим, что произошло с алгоритмами этой поисковой системы за 10 лет. По словам специалистов компании, теперь выдача действительно полезна людям, а накрутить позиции практически невозможно.
Сравнение качества ранжирования нейросетевых алгоритмов
В 2021 году Яндекс анонсировал новый алгоритм Proxima. Он анализирует не только соответствие содержимого страницы запросу пользователя, но и его лояльность к сайту, баланс полезной и навязчивой информации и вероятность решения задачи человека после перехода на сайт. Оценивается также удобство для посетителя: этапы заполнения корзины у интернет-магазинов, оформление заказа, варианты оплаты и другие метрики.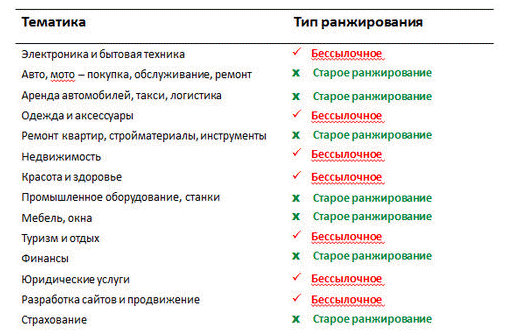 Результаты работы алгоритма отражаются на позициях в поисковой выдаче. Важно, чтобы сайт был не только полезным, но и комфортным в использовании.
Результаты работы алгоритма отражаются на позициях в поисковой выдаче. Важно, чтобы сайт был не только полезным, но и комфортным в использовании.
Санкции Яндекса
Алгоритмами ранжирования работа специалистов Яндекса по наведению порядка в Сети в целом и в выдаче в частности не закончилась. Они создали санкции — фильтры, понижающие в выдаче сайты с низкокачественным контентом, но хитрыми SEO-специалистами. Сейчас «чёрные» и «серые» способы продвижения работают всё меньше. Вы можете потерять позиции сайта не только на короткое время, но и на год и более. Это сулит большие финансовые потери. Мы собрали все работающие сейчас и известные SEO-сообществу санкции Яндекса и распределили их по сферам влияния.
Яндекс Вебмастер сообщит о наложении санкций на сайт
Для содержимого
Сайт должен приносить пользу или не попадёт в выдачу — так решили в Яндексе и создали санкции для содержимого сайтов.
- «АГС» — выпущено несколько обновлений этого фильтра. Сейчас он понижает в выдаче сайты, которые не несут смысла для пользователей и имеют слишком много исходящих SEO-ссылок. Оповещение о попадании под фильтр появится в Яндекс. Вебмастере. Выполните рекомендации поисковой системы и напишите в техподдержку Яндекса о проведённых изменениях. Средний срок выхода из-под фильтра — 1-3 месяца.
- «Партнёрки» — понижает в выдаче сайты, которые содержат только рекламный или партнёрский контент и не несут ценности для обычных пользователей. Добавьте полезный контент для выхода из-под санкции и отметьте в Яндекс. Вебмастере, что всё исправлено.
- «Бан» — полное исключение из поиска. Выдаётся спам-сайтам: «дорвеи» — ресурсы, которые только перенаправляют на другой сайт с помощью редиректа или ссылок, «клоакинг» — сайты, на которых поисковые роботы и пользователи видят разный контент, «списки поисковых запросов» — когда на странице просто перечислены запросы без вхождения в текст, «сайты-клоны» — содержат одинаковый контент, но могут вместе попадать в выдачу и занимать несколько строк. Бан действует 6-12 месяцев.
 Сейчас он понижает в выдаче сайты, которые не несут смысла для пользователей и имеют слишком много исходящих SEO-ссылок. Оповещение о попадании под фильтр появится в Яндекс. Вебмастере. Выполните рекомендации поисковой системы и напишите в техподдержку Яндекса о проведённых изменениях. Средний срок выхода из-под фильтра — 1-3 месяца.
Сейчас он понижает в выдаче сайты, которые не несут смысла для пользователей и имеют слишком много исходящих SEO-ссылок. Оповещение о попадании под фильтр появится в Яндекс. Вебмастере. Выполните рекомендации поисковой системы и напишите в техподдержку Яндекса о проведённых изменениях. Средний срок выхода из-под фильтра — 1-3 месяца. Бан действует 6-12 месяцев.
Бан действует 6-12 месяцев.Иногда под санкции попадают и честно сделанные сайты. В этом случае вопрос о снятии фильтра решает техническая поддержка Яндекса, причём достаточно быстро.
Для текстов
Качеству текстового содержимого в последнее время уделяется больше внимания, чем раньше. Сейчас информация на сайте должна быть для людей, а не для роботов. По этой причине Яндекс создал санкции, контролирующие качество текстов.
Сообщение в Яндекс Вебмастере о применении фильтра «Баден-Баден»
- «Переспам» — оценивает количество употреблённых в тексте запросов одного типа и понижает релевантность документа по ним при слишком большом числе вхождений.
- «Новый» или «Текстовый антиспам» — при переупотреблении ключевыми словами и несоответствии их заявленной тематике понижает позиции сайта на 50 и более строк по конкретному запросу. При этом по остальным запросам позиции не теряются. Если снижение частоты употребления ключевых слов не помогло, лучше переписать текст полностью.
- «Переоптимизация» — оценивает общее количество запросов в тексте и плотность их распределения. При злоупотреблении ключами снижает релевантность документа заданной теме. Сайт теряет 20-30 позиций в выдаче. Для снятия санкций нужно уменьшить количество вхождений группы ключей в контенте и метатегах. Обычно выйти из-под санкции удаётся за 2-3 обновления.
- «Баден-Баден» — оценивает весь контент документа полностью и понижает сайт в выдаче при наличии слишком большого числа запросов или низкого качества текста. Сайт теряет 10-30 позиций в выдаче. Для снятия нужно переработать контент, убрав переспам и блоки, не несущие смысла, обновлённые страницы отправить на переобход роботами Яндекса.

Результат запуска алгоритма «Баден-Баден»
- «Ты последний» — понижает страницу в выдаче за полностью скопированный текст или при низкой уникальности. Замените контент на уникальный и дождитесь переобхода страницы поисковым роботом.
На самом деле, хорошо написанный текст априори не попадает ни под одну санкцию. Нужно просто думать о читателе и давать максимум полезной информации для него.
Нужно просто думать о читателе и давать максимум полезной информации для него.
Для ссылок
Яндекс позже Google стал уделять внимание ссылочным факторам. Это позволило лучше подготовить систему: если в Google долгое время можно было накручивать ссылки и влиять на позиции в выдаче без последствий, то в Яндекс они играют меньшую роль при ранжировании, а также раньше стали контролироваться санкциями.
- «Ссылочный взрыв» — удар по позициям в выдаче за слишком быстрое наращивание ссылочной массы. Страдают не только акцепторы, доноры также помечаются как ненадёжные. Узнать фильтр несложно: появление новых ссылок игнорируется, имеющиеся не влияют на позиции. Все ссылки, проставленные перед наложением санкции, придётся удалить, наращивать ссылочную массу постепенно, выкладывать качественный контент. Проблема уйдёт сама через 2-3 месяца.
- «Пессимизация» или «Ссылочный спам» — накладывается за махинации со входящими ссылками: прогоны, ссылочные кольца и т. п. Снимается при прекращении нежелательных действий и обращении в техподдержку Яндекс с вопросом о его снятии.
- «Минусинск» — понижение в среднем на 20 строк в выдаче за покупные входящие ссылки и большое число SEO-ссылок. Фильтр оценивает более 125 параметров, которые достоверно знают только в Яндексе. Предупреждение о наложении санкции будет в Яндекс. Вебмастере. Все некачественные ссылки придётся удалить, нажать кнопку в Яндекс. Вебмастере «Я всё исправил» и ждать результатов.
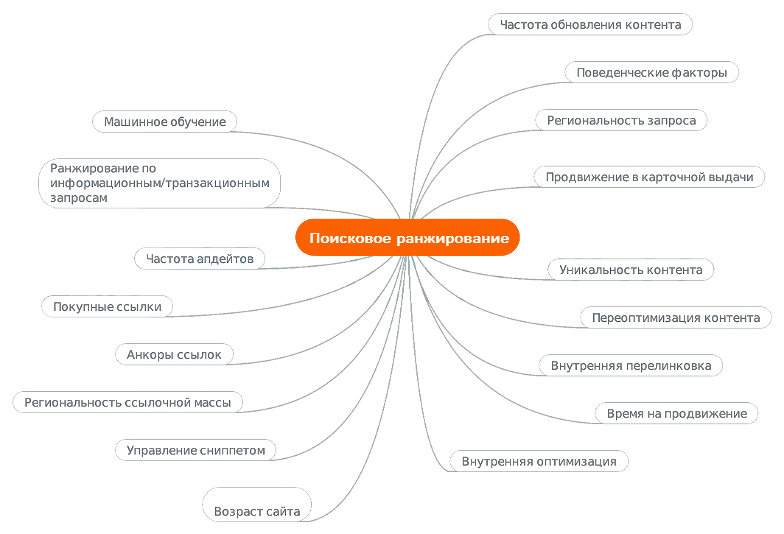
Сообщение в Яндекс Вебмастере о применении фильтра «Минусинск»
- «Непот» — выдаётся за избыточную внутреннюю перелинковку или внешние низкокачественные ссылки. Из ранжирования исключается одна ссылка или сразу несколько, сам сайт фильтр не затрагивает. Фильтр снимется автоматически при удалении некачественных ссылок.
Избежать попадания под санкции Яндекса на сайт поможет тщательный подбор доноров ссылок по качеству и соответствию тематике сайта.
Для поведенческих факторов
Качество сайта во многом определяется тем, как его воспринимают пользователи. Для повышения его статуса в глазах поисковых роботов некоторые недобросовестные специалисты используют накрутку поведенческих факторов. Яндекс постоянно борется с этим с помощью фильтров.
Для повышения его статуса в глазах поисковых роботов некоторые недобросовестные специалисты используют накрутку поведенческих факторов. Яндекс постоянно борется с этим с помощью фильтров.
- «Содействие имитации действий пользователей» — потеря позиций в выдаче за размещение на сайте КАПЧИ для улучшения кликовых показателей. В большей степени это относится к вовлечению случайных посетителей в накрутку.
- «Накрутка поведенческих факторов» — за накрутку кликов с помощью автоматических действий на сайте, выполненных роботами от имени пользователей, или людьми за денежное вознаграждение. В ТОПе сайт остаётся только по запросам, не содержащих прямого указания на него, по остальным же теряет до 20 позиций и 90% трафика. Для нормализации позиций нужно остановить накрутку и связаться с техподдержкой Яндекса.
Качественный сайт не нуждается в накрутке поведенческих факторов, пользователи сами захотят взаимодействовать с ним.
Последствия от получения фильтра Яндекса — трафик из поиска упал почти до нуля
Для обманщиков
За обман поисковых систем Яндекс наказывает довольно жёстко. Неудивительно, ведь это вредит пользователям.
Неудивительно, ведь это вредит пользователям.
- «Кликджекинг» — размещая на страницах невидимые элементы, с которыми пользователи случайно взаимодействуют, нужно быть готовым к существенной потере позиций. Ведь таким способом недобросовестные владельцы сайтов получают доступ к персональным данным гостя. Уведомление о санкции будет в Яндекс. Вебмастере. При удалении части кода с невидимыми элементами нужно нажать кнопку «Я всё исправил».
- «Криптоджекинг» — сайты со скриптами для майнинга криптовалют отмечаются как опасные и теряют позиции в выдаче. Для этого процесса ресурс использует мощности устройств пользователей, что нарушает политику Яндекса. Просто не используйте сайт для майнинга, и не получите санкций.
Не стоит пытаться обмануть роботов и пользователей. Санкции Яндекса — меньшая из проблем, которую можно получить из-за этого.
Для рекламы
Без рекламы нет бизнеса, но не нужно забывать о правилах приличия. Яндекс закрепил их с помощью фильтров.
- «Назойливая реклама» — сайты, реклама на которых всплывает в новом окне вслед за вкладкой, открывается по кнопке «закрыть» на баннере или при первом же клике на странице, а также при использовании других схожих методов размещения объявлений, понижаются в выдаче.
- «Избыточная реклама» — за слишком большое количество рекламы сайт теряет позиции в выдаче. Уменьшите количество рекламы и сообщите об этом в техподдержку Яндекса.
- «За рекламу, вводящую в заблуждение» — за ложные обещания на всплывающих окнах Яндекс понизит позиции сайта. Замените рекламные материалы и сообщите в техподдержку Яндекса.
- «За навязчивые оповещения» — пометку в выдаче и снижение строки Яндекс даёт за принуждение пользователей к подписке на рекламные push-сообщения. Оповещение о фильтре появится в Яндекс. Вебмастер. Там же можно снять санкцию после избавления от навязчивых оповещений.
- «Малополезный контент» — лучше не маскировать рекламу под часть навигации или контента, чтобы не получить понижение в выдаче. При попадании под фильтр придётся исправить рекламу, добавить полезный контент и отметить это в Яндекс. Вебмастере. Если не помогло, можно написать в техподдержку Яндекса.
Сообщение в Яндекс Вебмастере о санкции фильтра «Малополезный контент»
- «За обман мобильных пользователей» — агрессивная реклама для пользователей переносных устройств или автоматические редиректы для таких гостей приведут к потере части трафика на сайт. Уберите такую рекламу с сайта и сообщите об изменениях в техподдержку Яндекса.
Реклама — это хорошо, но она должна быть адекватной и в меру.
Для групп сайтов
Владельцы нескольких сайтов должны уделять одинаковое внимание каждому из них, иначе рискуют попасть под санкции Яндекса.
- «Аффилированность» — среди сайтов одного владельца, похожих на дубли, в выдаче останется только один. Яндекс объединяет их в группы аффилиантов по множеству параметров, включая размещение на одном хостинге, схожие шаблоны, контакты и реквизиты, продвижение по одинаковым запросам, контент на страницах и т. п. Если есть подозрение на попадание под фильтр, стоит разместить каждый сайт на отдельном хостинге, изменить контактную информацию и подождать от недели до нескольких месяцев.
- «Одинаковые сниппеты» — собирает сайты в группы по существенно схожим сниппетам, то есть информации, представленной в выдаче. В результате действия конкретные страницы выпадают из ТОП-100. Для выхода нужно написать уникальные метатеги и пройти 2-3 обновления.
У каждого сайта должны быть уникальные метатеги и контент, чтобы не попасть под фильтры.
Для некоторых направлений
Контент для взрослых регулирует в Яндексе «Adult-фильтр». Он выводит сайт из видимости по обычным запросам и показывает только по специфичным, с явным adult-интентом или при ручном снятии фильтра в настройках поисковой системы. Иногда ограничения накладываются только на определённые разделы, а не на весь сайт. Если «взрослого» контента нет, а санкция есть, стоит связаться с техподдержкой Яндекса. Среднее время устранения последствий — 1 месяц.
Для нарушителей закона
Закон един для всех, в том числе для бизнеса в интернете. Поэтому Яндекс удаляет из результатов поиска сайты, которые нарушают закон. Под санкции попадают и копии этих сайтов. Список запрещённых ресурсов составляет Министерство цифрового развития, связи и массовых коммуникаций. Под запрет попадают сайты, нарушающие ФЗ № 149 и № 156. Приведите сайт в соответствие законам и сообщите об этом в техподдержку Яндекса.
Все алгоритмы и санкции Яндекса направлены на то, чтобы пользователь получил качественный контент. Если ваш сайт разработан и настроен профессионалами, у вас не будет проблем с его продвижением.
Хотите заказать эффективное продвижение компании в поисковых системах? Свяжитесь с нами по телефону: +7 (800) 200-94-60, доб. 321 или оставьте запрос на электронную почту [email protected].
как поставить машинное обучение на поток (пост #3) / Хабр
Сегодня мы завершаем серию публикаций о фреймворке FML, в которых рассказываем о том, как и для чего автоматизировали в Яндексе применение технологий машинного обучения. В сегодняшнем посте мы расскажем:
- почему нужно следить за качеством факторов и как мы это делаем;
- как FML помогает в задачах распределённых вычислений над поисковым индексом;
- каким образом и для чего наши технологии машинного обучения уже применяются и могут быть применены как в Яндексе, так и вне его;
- какую литературу можно посоветовать для более глубокого погружения в затронутую проблематику.
Мониторинг качества уже внедрённых факторов
В предыдущем посте мы остановились на том, что с помощью FML нам удалось поставить на поток разработку новых факторов для формулы ранжирования и первоначальную оценку их полезности. Однако следить, что фактор остаётся ценным и не впустую расходует вычислительные ресурсы, необходимо и после его внедрения.
Для этого была создана специальная регулярная автоматическая проверка — так называемый мониторинг качества факторов. Вычислительно он очень сложный, но позволяет решить целый ряд проблем.
Первая – это выявление претендентов на «удаление». Убедившись однажды, что фактор вносит большой вклад и его цена приемлема, и приняв после этого решение о его внедрении, важно следить за тем, чтобы со временем он оставался полезным, несмотря на появление всё новых и новых факторов. Ведь новый может запросто оказаться более общим и сильным, чем старый, и не только создавать новую ценность, но и дублировать его. Например, когда мы сначала внедрили фактор «вхождение слов запроса в URL, записанный латиницей», а спустя какое-то время сделали новый, поддерживающий вхождение в URL-ы, записанные и латиницей, и кириллицей, первый потерял всякую ценность. Старую версию следует удалять как минимум по двум причинам: 1) экономия на времени вычисления старого фактора; 2) уменьшение размерности признаков при обучении.
Иногда возникает другая ситуация. Фактор раньше приносил «много пользы», а теперь он, хотя и остаётся полезным, уже не проходит порог качество / затраты. Такое может случиться, если он потерял свою актуальность, или стал частично дублироваться более новыми факторами. Поэтому нужно создавать здоровую эволюцию — чтобы слабые факторы погибали и уступали место сильным. Но здесь недостаточно одних данных от FML, и окончательное решение об удалении фактора принимается экспертами.
Есть ещё одна проблема, которую решает мониторинг качества. Отслеживая то, что полезность однажды внедрённого фактора не снизилась, он обеспечивает регрессионное тестирование. Качество фактора может упасть, например, из-за случайной модификации или системного изменения в свойствах интернета, на которые он первоначально полагался. В таком случае система уведомит разработчика, что данный фактор нужно «починить» (исправить ошибку или модифицировать его так, чтобы он отвечал новым реалиям).
Третья задача мониторинга, которую он вскоре начнёт решать — избавление от избыточности факторов. До определённого момента мы не проверяли, дублирует ли новый фактор какой-то из уже внедрённых. В результате вполне могло оказаться, что, например, есть два фактора, которые повторяют друг друга. Но если измерить, какой вклад каждый из них в одиночку даёт по отношению ко всем остальным, — окажется, что он равен нулю. А если исключить оба фактора, то качество упадёт. И задача именно в том, чтобы выбрать, какие из дублирующихся факторов эффективнее всего оставить, с точки зрения того же соотношения роста качества к цене вычислений. Вычислительно это на много порядков сложнее, чем оценка нового фактора. Именно для решения этой задачи мы и планируем задействовать расширенный кластер на 300 Tflops.
Ситуация, в которой каждый из двух факторов, I и J,
дают нулевой вклад — (J, K, L) и (I, K, L),
но удаление их обоих приводит к ухудшению качества — (K, L).
Можно исключить любой один (I либо J).
Выгоднее исключить J, как более ресурсоёмкий.
Конвейер распределённых вычислений
В этом и предыдущихпостах говорилось о конкретных применениях для FML в контексте регулярного машинного обучения. Но в итоге фреймворк вышел за рамки этих прикладных задач и стал полноценной платформой для распределённых вычислений над поисковым индексом.
Посвященные читатели наверняка заметили, что везде, где используется FML, речь идёт о примерно одном и том же массиве данных: скаченных документах, сохранённых запросах, асессорских оценках, результатах расчёта факторов. Мы в своё время тоже это заметили, а ещё посмотрели на количество других задач, которые уже решаются в Поиске и так или иначе полагаются на эти данные; и решили извлечь из этого дополнительную пользу. А именно — сделали из FML полноценный конвейер для произвольных распределённых вычислений над этим набором данных, которые выполняются на вычислительном кластере, насчитывающем несколько тысяч серверов.
Мы добились того, что FML облегчает выполнение распределённых расчётов над поисковым индексом и дополнительными данными, специфичными для конкретной задачи. Поисковый индекс обновляется несколько раз в неделю, и с каждым обновлением существенная его часть переезжает между серверами для более оптимального использования ресурсов. FML полностью избавляет разработчика от забот о поиске нужного фрагмента индекса и предоставляет ему полный и консистентный доступ к нему. Фреймворк диагностирует целостность индекса и запускает вычисления именно на тех серверах кластера, где лежат нужные разработчику данные.
В отличие от поискового индекса, специфичные для текущей задачи данные FML сам раскладывает по серверам. Также он берёт на себя управление распределённым выполнением конкурирующих пользовательских задач. Как только вычисления запущены, FML начинает следить за ходом выполнения расчётов и когда какая-то из задач на конкретном сервере становится недоступной, даёт сигнал администраторам. Получив его, они приступают к диагностике конкретной ситуации с этой задачей на этом сервере, будь то поломка диска, неисправности сети или полный выход сервера из строя. В наших дальнейших планах — помогать администраторам как можно более детальной диагностикой и упростить поиск причин тех или иных сбоев. Последние в условиях нескольких тысяч серверов — совершенно заурядное дело, и происходят много раз в день. Поэтому мы сильно сэкономим ручной труд администраторов, если хоть немного его автоматизируем.
На первый взгляд, всё это очень похоже на задачи YAMR — то же распределение вычислений, сбор результатов и обеспечение надёжности. Но есть два кардинальных отличия. Во-первых, FML имеет дело с поисковым индексом, а не с классической структурой «ключ-значение», принятой в YAMR. Поисковый индекс подразумевает, что все выборки происходят по комбинации сразу большого количества ключей (в простейшем случае — нескольких слов запроса). Работа с такими выборками в парадигме «ключ-значение» принципиально затруднена. А во-вторых, если YAMR сам решает, как разложить данные по серверам, то FML умеет работать с любым распределением данных, заранее заданным внешней системой по её собственным законам.
Решение оказалось настолько удачным, что большинство команд разработки Поиска по собственной инициативе перешло на использование FML, и, по нашим оценкам, сегодня около 70% (в смысле количества процессорного времени) вычислений в разработке Яндекс. Поиска находится под управлением FML.
Области применения и сравнение с аналогами
Как мы уже говорили, FML и Матрикснет являются частями технологии машинного обучения Яндекса. И используется она у нас не только в веб-поиске. Например, с её помощью подбираются формулы для так называемых «вертикальных» поисков (по изображениям, видео и т.п.) и для предварительного отсева совсем нерелевантных документов в веб-поиске. Она помогает обучать алгоритм классификации товаров по категориям в Яндекс.Маркете. Кроме того, машинное обучение подбирает формулы для поискового робота (например, для стратегии, которая определяет, в каком порядке обходить сайты). И во всех этих случаях решает одну и ту же задачу — строит функцию, которая наилучшим образом соответствует экспертным данным, поданным на вход. Думаем, в ближайшее время мы найдём для него ещё множество применений в Яндексе. Например, используем в обучении классификаторов, которых у нас очень много.
FML в паре с библиотекой машинного обучения Матрикснет может быть полезен не только в разработке поисковых систем, но и в других областях, где требуется обработка данных. С некоторыми коллективами мы уже опробовали их для построения поиска по специализированным видам данных с учётом специфических факторов. Например, CERN (Европейский Центр ядерных исследований) использует Матрикснет для обнаружения редких событий в больших объёмах данных (единицы на миллиард). Традиционно там использовался пакет TMVA, основанный на Gradient Boosted Decision Trees (GBDT). Поскольку Матрикснет на наших задачах и наших метриках давно стал точнее, чем простой GBDT, мы расчитываем, что и физики ЦЕРНа смогут использовать его для повышений точности своих исследований.
Почему Матрикснет может открыть дорогу Нобелевской премии
Один из видов событий, к подсчёту которых может быть применен FML/Матрикснет — это случаи распада странного B-мезона на мюон-антимюонную пару. Физически реальные показания одного из детекторов Большого Андронного Коллайдера после столкновения пучков протонов сравниваются с эталонными значениями, полученными в симуляторе событий.
Стандартная модель считает такие распады очень редким событием (примерно 3 события на миллиард столкновений). И если в результате анализа экспериментальных данных Матрикснет достоверно покажет, что таких событий больше и их количество совпадает с предсказаниями одной из новых физик, это будет означать справедливость этих теорий и может стать первым долгожданным поводом для вручения Нобелевской премии их авторам.
Глядя более широко на то, что умеет наша технология, мы уверены, что она может быть полезна и во многих сферах, в которых встречаются типовые задачи машинного обучения — тем более, если они имеют дело с большим массивом данных, меняющимся во времени. Например, в крупных интернет-магазинах, онлайн-аукционах, социальных сетях.
Сейчас нам известно только одно промышленное решение для близкой задачи, помимо нашего собственного, — Google Prediction API. Есть и несколько стартапов, таких как BigML. К сожалению, мы не смогли найти сведений об их эффективности для тех или иных применений. В качестве конвейера для вычислительных задач может ещё служить Amazon Cloud Service, но его пристальное рассмотрение показало, что это очень общее решение, для совершенно произвольных задач. В то время как наше создано именно для поисковых и максимально раскрывается в них. Аналоги же FML в решении задач «Оценка эффективностипо нового фактора» и «Мониторинг качества факторов» нам и вовсе неизвестны.
Внешний наблюдатель может косвенно судить об эффективности нашей технологии, опираясь на результаты международных соревнований по машинному обучению. Например, специалисты Яндекса занимали высокие места в состязаниях по ранжированию Yahoo Learning to Rank и Facebook Recruiting, в которых борьба за точность ранжирующей функции идёт в терминах тысячных долей ERR/NDCG. Хорошие результаты они показывали на конкурсах по машинному обучению и в других областях.
Чтобы быть уверенными в том, что наши технологии остаются лучшими в своей области, мы регулярно проводим и собственные конкурсы по машинному обучению — в рамках серии «Интернет-математика». Среди тем: машинное обучение ранжированию, предсказание пробок на дорогах, классификация панорамных фото. Два года назад наши соревнования стали международными, и завершающий этап конкурса по пресказанию релевантности по поведению пользователей прошёл в рамках конференции WSDM 2012 в Сиэттле (США). Совсем недавно завершился конкурс, посвящённый прогнозированию переключения поисковой системы.
Несмотря на то, что фреймворк FML, о котором мы рассказали вам в этой серии постов, изначально создавался для работы с Матрикснетом, он может быть адаптирован к любой другой известной библиотеке машинного обучения (например, Apache Mahout, Weka, scikit-learn).
Рекомендуемая литература
В последнее время появилось несколько хороших онлайн-курсов по машинному обучению. На английском можно порекомендовать курс Стенфордского университета, на русском — курс Константина Воронцова, который читается в Школе Анализа Данных.
Из «бумажных» изданий отметим два издания: The Elements of Statistical Learning: Data Mining, Inference, and Prediction (Trevor Hastie, Robert Tibshirani, Jerome Friedman) (доступна и в электронном виде) и Pattern Recognition and Machine Learning (Christopher M. Bishop).
Кроме этого, будет полезной обширная подборка курсов и учебников, собранная на Kaggle.
Рейтинг
Гиперболические трансформаторы зрения: объединение улучшений в метрическом обучении
RankingResentationscomputer Visionaleksandr ermolovleyla mirvakhovalentin khrulkovnicu sebeivan osedets
Cvpr,
2022 2Metrice. выбранные метрики и раздвинуты для непохожих. Общий рецепт заключается в использовании кодировщика для извлечения вложений и функции потерь на основе расстояния для соответствия представлениям — обычно используется евклидово расстояние.
Возникающий интерес к изучению встраивания гиперболических данных предполагает, что гиперболическая геометрия может быть полезна для естественных данных. Следуя этому направлению работы, мы предлагаем новую гиперболическую модель для метрического обучения. В основе нашего метода лежит преобразователь зрения с выходными вложениями, отображаемыми в гиперболическом пространстве. Эти вложения напрямую оптимизируются с использованием модифицированной попарной кросс-энтропийной потери. Мы оцениваем предложенную модель с шестью различными формулировками на четырех наборах данных, достигая нового современного уровня производительности. Исходный код доступен по адресу https://github.com/htdt/hyp_metric 9.0008Neural Side-by-Side: предсказание предпочтений человека для оценки сверхразрешения без эталона
RankingComputer visionВалентин ХрулковАртем Бабенко и промышленность. Однако отсутствие надлежащих мер оценки затрудняет сравнение подходов, препятствуя прогрессу в этой области.
Известно, что традиционные меры, такие как PSNR или SSIM, плохо коррелируют с человеческим восприятием качества изображения. Таким образом, в существующих работах общепринятой практикой является также отчет о средней оценке мнений (MOS) — результатах человеческой оценки изображений со сверхвысоким разрешением. К сожалению, значения MOS из разных статей нельзя сравнивать напрямую из-за разного количества оценщиков, их субъективности и т. д. сравниваться автоматически, эффективно приближаясь к человеческим предпочтениям. А именно, мы собираем большой набор данных выровненных пар изображений, которые были созданы с помощью различных моделей сверхвысокого разрешения. Затем каждая пара аннотируется несколькими оценщиками, которым предлагается выбрать более визуально привлекательное изображение. Учитывая набор данных и метки, мы обучили модель CNN, которая получает пару изображений и для каждого изображения предсказывает вероятность того, что оно будет более предпочтительным, чем его аналог. В этой работе мы показываем, что Neural Side-By-Side обобщает как новые модели, так и новые данные. Следовательно, он может служить естественным приближением человеческих предпочтений, которое можно использовать для сравнения моделей или настройки гиперпараметров без помощи оценщиков. Мы открываем набор данных и предварительно обученную модель и ожидаем, что они станут удобным инструментом для исследователей и практиков.Неметрические графики подобия для поиска максимального внутреннего продукта
РанжированиеПоиск ближайшего соседаСтанислав МорозовАртем Бабенко
NeurIPS,
2018большое количество приложений для машинного обучения. Было показано, что проблема MIPS, похожая на поиск ближайшего соседа (NNS), является более сложной, поскольку внутренний продукт не является правильной метрической функцией. Мы предлагаем решать задачу MIPS с помощью графов подобия, т. е. графов, в которых каждая вершина соединена с вершинами, наиболее сходными с точки зрения некоторой функции подобия.
Первоначально структура графов подобия была предложена для метрических пространств, и в этой статье мы естественным образом расширяем ее на неметрический сценарий MIPS. Мы показываем, что, в отличие от существующих подходов, графы подобия не требуют преобразования данных для сведения MIPS к проблеме NNS и должны использоваться для исходных данных. Более того, мы объясняем, почему такая редукция губительна для графов подобия. Обширным сравнением с существующими подходами мы показываем, что предлагаемый метод меняет правила игры с точки зрения компромисса между временем выполнения и точностью для проблемы MIPS.
API Общие данные API SE Ranking
Список поисковых систем
Описание
Метод позволяет получить список доступных поисковых систем вместе с регионами, которые можно добавлять в проекты для отслеживания позиций.
Формат запроса
GET /system/search-engines
Результат
В случае успеха сервер возвращает массив доступных поисковых систем.
| Наименование | Описание | ||||||||||||||||||||||||||||||||||||
| ID | Уникальный идентификатор поисковой машины | ||||||||||||||||||||||||||||||||||||
| Наименование | Наименование | ||||||||||||||||||||||||||||||||||||
| region_id | Тип идентификатор. { «id»: «200», «name»: «Google USA», «regionid»: «182» }, { «id»: «201», «name»: «Google Andorra «, «regionid»: «4» }, { «id»: «202», «название»: «Google Объединенные Арабские Эмираты», «regionid»: «178» }, … ] Список доступных регионов для ЯндексаОписаниеМетод позволяет получить полный список возможные языки для поисковой системы яндекс. Формат запросаGET /system/yandex-regions РезультатВ случае успеха сервер возвращает массив, содержащий список регионов для Яндекса и их уникальные идентификаторы Пример ответа { Список доступных регионов для Google44 Описание Метод позволяет получить список доступных регионов для поисковой системы Google. Формат запроса GET /system/google-regions Результат В случае успеха сервер возвращает массив, содержащий список регионов для Google. Пример ответа [ Список языков для GoogleОписание90 получить полный список возможных языков для поисковой системы Google. Формат запросаGET /system/google-langs РезультатВ случае успеха сервер вернет массив с полным списком языковых кодов и их названий для поисковой системы Google.
Response example[ Список регионов для получения объема поискаОписание Метод позволяет чтобы получить список всех регионов, в которых SE Ranking может выполнять проверку объема поиска по ключевым словам. ПараметрыЭтот метод не имеет параметров. Формат запросаGET /system/volume-regions РезультатВ случае успеха сервер возвращает массив регионов.
Response example[ Получение данных об объеме поиска по ключевым словамОписаниеМетод позволяет получить данные об объеме поиска для указанного региона и списка ключевых слов. Параметры
Пример ответа {».
|