Содержание
Ранжирующие функции (Transact-SQL) — SQL Server
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
- Чтение занимает 2 мин
-
Область применения: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр SQL Azure Azure Synapse Analytics Analytics Platform System (PDW)
Ранжирующие функции возвращают ранжирующее значение для каждой строки в секции. В зависимости от используемой функции значения некоторых строк могут совпадать. Ранжирующие функции являются недетерминированными.
В зависимости от используемой функции значения некоторых строк могут совпадать. Ранжирующие функции являются недетерминированными.
TransactSQL предлагает следующие ранжирующие функции:
DENSE_RANK
ROW_NUMBER
Примеры
В следующем примере показано использование четырех ранжирующих функций в одном запросе. Примеры по каждой ранжирующей функции см. в посвященных им статьях.
USE AdventureWorks2012;
GO
SELECT p.FirstName, p.LastName
,ROW_NUMBER() OVER (ORDER BY a.PostalCode) AS "Row Number"
,RANK() OVER (ORDER BY a.PostalCode) AS Rank
,DENSE_RANK() OVER (ORDER BY a.PostalCode) AS "Dense Rank"
,NTILE(4) OVER (ORDER BY a.PostalCode) AS Quartile
,s.SalesYTD
,a.PostalCode
FROM Sales.SalesPerson AS s
INNER JOIN Person.Person AS p
ON s.BusinessEntityID = p.BusinessEntityID
INNER JOIN Person.Address AS a
ON a.AddressID = p.BusinessEntityID
WHERE TerritoryID IS NOT NULL AND SalesYTD <> 0;
Результирующий набор:
| FirstName | LastName | Row Number | Rank | Dense Rank | Quartile | SalesYTD | PostalCode |
|---|---|---|---|---|---|---|---|
| Michael | Blythe | 1 | 1 | 1 | 1 | 4557045,0459 | 98027 |
| Linda | Mitchell | 2 | 1 | 1 | 1 | 5200475,2313 | 98027 |
| Jillian | Carson | 3 | 1 | 1 | 1 | 3857163,6332 | 98027 |
| Garrett | Vargas | 4 | 1 | 1 | 1 | 1764938,9859 | 98027 |
| Tsvi | Reiter | 5 | 1 | 1 | 2 | 2811012,7151 | 98027 |
| Shu | Ito | 6 | 6 | 2 | 2 | 3018725,4858 | 98055 |
| Josй | Saraiva | 7 | 6 | 2 | 2 | 3189356,2465 | 98055 |
| David | Campbell | 8 | 6 | 2 | 3 | 3587378,4257 | 98055 |
| Tete | Mensa-Annan | 9 | 6 | 2 | 3 | 1931620,1835 | 98055 |
| Lynn | Tsoflias | 10 | 6 | 2 | 3 | 1758385,926 | 98055 |
| Rachel | Valdez | 11 | 6 | 2 | 4 | 2241204,0424 | 98055 |
| Jae | Pak | 12 | 6 | 2 | 4 | 5015682,3752 | 98055 |
| Ranjit | Varkey Chudukatil | 13 | 6 | 2 | 4 | 3827950,238 | 98055 |
См.
 также:
также:
Встроенные функции (Transact-SQL)
OVER, предложение (Transact-SQL)
Функции ранжирования и нумерации в Transact-SQL — ROW_NUMBER, RANK, DENSE_RANK, NTILE | Info-Comp.ru
Изучение Transact-SQL продолжается и на очереди у нас функции ранжирования ROW_NUMBER, RANK, DENSE_RANK и NTILE, сейчас мы узнаем, что делают эти функции и зачем вообще они нужны, все как обычно будем рассматривать на примерах.
В языке Transact-SQL очень много различных функций, конструкций, например, PIVOT или INTERSECT, которые в принципе редко используются, их мы даже в нашем мини справочнике Transact-SQL не указывали, но знать, где и как их можно использовать нужно, так же, как и функции ранжирования или их еще называют функции нумерации. Поэтому сегодня давайте поговорим именно об этих функциях, и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
И начнем мы, конечно же, с определения, что же вообще это за ранжирующие функции.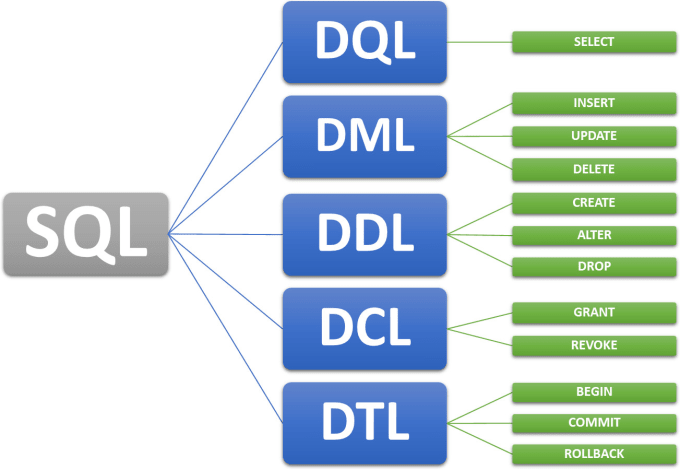
Содержание
- Ранжирующие функции в T-SQL
- Исходные данные для примеров
- ROW_NUMBER
- RANK
- DENSE_RANK
- NTILE
Ранжирующие функции в T-SQL
Ранжирующие функции — это функции, которые возвращают значение для каждой строки группы в результирующем наборе данных. На практике они могут быть использованы, например, для простой нумерации списка, составления рейтинга или постраничной выборки.
И для того чтобы лучше усвоить работу и применение этих функций, давайте рассмотрим все их по очереди, и параллельно будем сравнивать их друг с другом, т.е. таким образом, мы еще и узнаем в чем их отличие. Но для того чтобы начать рассматривать примеры, необходимо определится с исходными данными.
Заметка! Для комплексного изучения языка SQL рекомендую почитать мою книгу «SQL код». Данный книга рассчитана на изучение языка SQL как стандарта, т.е. на изучение тех возможностей SQL, которые доступны и точно будут работать во всех популярных системах управления базами данных (СУБД).
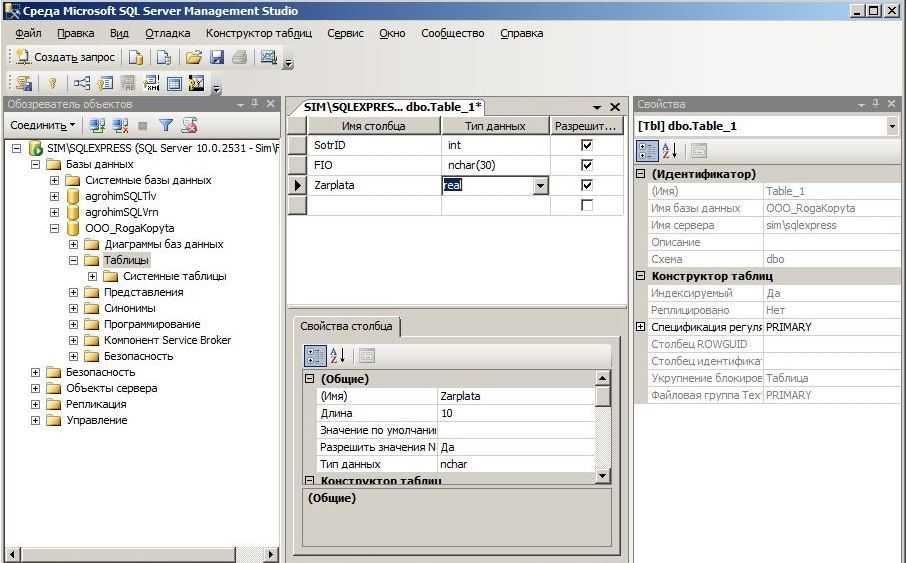
Исходные данные для примеров
Использовать мы будем MS SQL Server Express 2014, а запросы будем писать в Management Studio Express. В качестве тестовых данных будем использовать таблицу selling, которая будет содержать различные товары (телефоны, планшеты, ноутбуки, программы) с выдуманными ценами.
Наша тестовая таблица
CREATE TABLE [dbo].[selling](
[id] [int] IDENTITY(1,1) NOT NULL,
[NameProduct] [varchar](50) NOT NULL,
[price] [money] NOT NULL,
[category] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
Заполним ее тестовыми данными, в итоге получим следующее (для выборки пишем простой запрос select)
Заметка! Функции TRIM, LTRIM и RTRIM в T-SQL – описание, отличия и примеры.
ROW_NUMBER
ROW_NUMBER – функция нумерации в Transact-SQL, которая возвращает просто номер строки.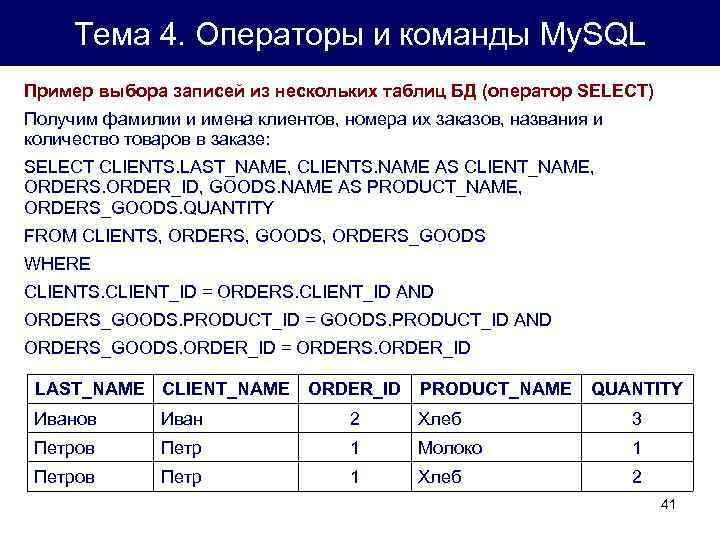
Синтаксис
ROW_NUMBER () OVER ([PARTITION BY столбы группировки] ORDER BY столбец сортировки)
где, partition by — это не обязательное ключевое слово, после которого указывается столбец или столбцы, по которым группировать данные, а order by столбец для сортировки, т.е. по данному столбцу будут отсортированы данные, а потом пронумерованы, он уже обязателен. Сразу скажу, чтобы не возвращаться, что эти ключевые слова относятся ко всем функциям ранжирования, которые мы будем сегодня использовать.
Пример без группировки с сортировкой по цене
Текст запроса
SELECT NameProduct, price, category,
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER]
FROM selling
Пример с группировкой по категории и с сортировкой по цене
Текст запроса
SELECT NameProduct, price, category,
ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART]
FROM selling
Как видите, здесь уже нумерация идет в каждой категории.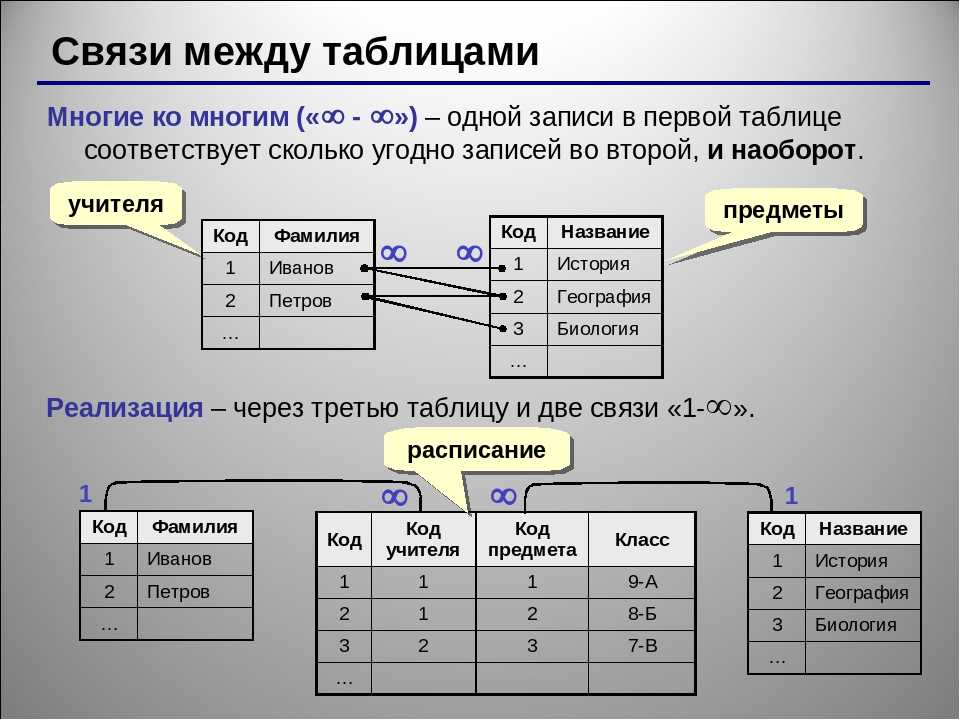
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
Пример без группировки с сортировкой по цене и отличие от row_number()
Текст запроса
SELECT NameProduct, price, category,
rank() over (order by price desc) [RANK],
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER]
FROM selling
Пример с группировкой по категории и с сортировкой по цене и отличие от row_number()
Текст запроса
SELECT NameProduct, price, category,
rank() over (partition by category order by price desc) [RANK],
ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART]
FROM selling
DENSE_RANK
DENSE_RANK — ранжирующая функция, которая возвращает ранг каждой строки, но в отличие от rank, в случае нахождения одинаковых значений, возвращает ранг без пропуска следующего.
Пример без группировки с сортировкой по цене и отличие от rank() и row_number()
Текст запроса
SELECT NameProduct, price, category,
rank() over (order by price desc) [RANK],
DENSE_RANK () over (order by price desc) [DENSE_RANK],
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER]
FROM selling
NTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
Пример
Текст запроса
SELECT NameProduct, price, category,
NTILE(3)over (order by price desc) [NTILE]
FROM selling
В заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой
Текст запроса
SELECT NameProduct, price, category,
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER],
rank() over (order by price desc) [RANK],
DENSE_RANK () over (order by price desc) [DENSE_RANK],
NTILE(3)over (order by price desc) [NTILE]
FROM selling
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.

На этом я думаю по ранжирующим функциям достаточно, в следующих статьях мы продолжим изучение Transact-SQL, а на этом пока все. Удачи!
РАНГ
(Transact-SQL) — SQL Server
- Статья
- 3 минуты на чтение
Применимо к:
SQL Server (все поддерживаемые версии)
База данных SQL Azure
Управляемый экземпляр Azure SQL
Аналитика синапсов Azure
Система аналитической платформы (PDW)
Возвращает ранг каждой строки в разделе результирующего набора. Ранг строки равен единице плюс количество рангов, предшествующих рассматриваемой строке.
ROW_NUMBER и RANK похожи. ROW_NUMBER последовательно нумерует все строки (например, 1, 2, 3, 4, 5). RANK предоставляет одинаковое числовое значение для ничьих (например, 1, 2, 2, 4, 5).
Примечание
RANK — это временное значение, вычисляемое при выполнении запроса. Чтобы сохранить числа в таблице, см. Свойство IDENTITY и SEQUENCE.
Соглашения о синтаксисе Transact-SQL
Синтаксис
RANK ( ) OVER ( [ partition_by_clause ] order_by_clause )
Примечание
Чтобы просмотреть синтаксис Transact-SQL для SQL Server 2014 и более ранних версий, см. документацию по предыдущим версиям.
Аргументы
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause делит результирующий набор на разделы, которые применяются к разделам F. Если не указано, функция обрабатывает все строки набора результатов запроса как одну группу. order_by_clause определяет порядок данных перед применением функции. Требуется order_by_clause . Предложение <строки или диапазон/> предложения OVER не может быть указано для функции RANK.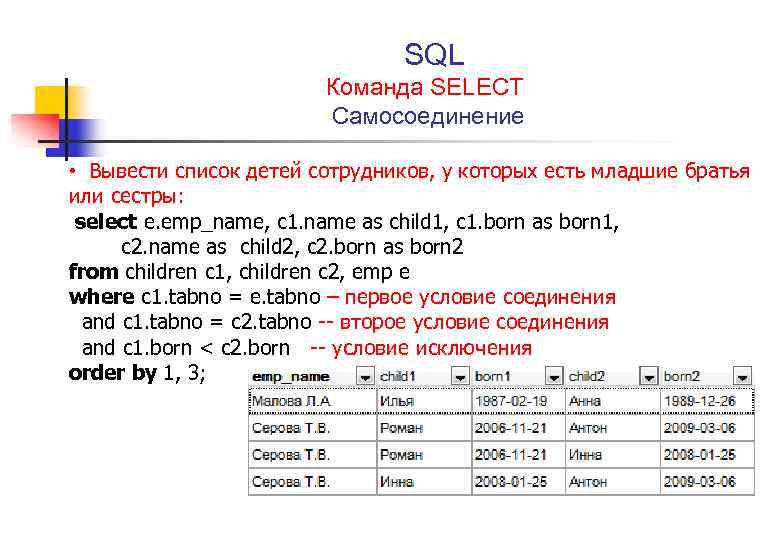 Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
Типы возвращаемых значений
bigint
Если две или более строк имеют одинаковый ранг, каждая связанная строка получает одинаковый ранг. Например, если у двух лучших продавцов одинаковое значение SalesYTD, они оба получают один рейтинг. Продавец со следующим самым высоким значением SalesYTD занимает третье место, потому что есть две строки с более высоким рейтингом. Поэтому функция RANK не всегда возвращает последовательные целые числа.
Порядок сортировки, используемый для всего запроса, определяет порядок, в котором строки появляются в результирующем наборе.
РАНГ недетерминирован. Дополнительные сведения см. в разделе Детерминированные и недетерминированные функции.
Примеры
A. Ранжирование строк в разделе
В следующем примере продукты ранжируются в указанных местах хранения в соответствии с их количеством. Набор результатов разделен на LocationID и логически упорядочен по Количество . Обратите внимание, что продукты 494 и 495 имеют одинаковое количество. Поскольку они равны, они оба занимают первое место.
Обратите внимание, что продукты 494 и 495 имеют одинаковое количество. Поскольку они равны, они оба занимают первое место.
ИСПОЛЬЗОВАТЬ AdventureWorks2012;
ИДТИ
ВЫБЕРИТЕ i.ProductID, p.Name, i.LocationID, i.Quantity
,РАНГ() БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО i.LocationID ORDER BY i.Quantity DESC) AS Ранг
ИЗ Production.ProductInventory AS i
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Производство. Продукт AS p
ON i.ProductID = p.ProductID
ГДЕ i.LocationID МЕЖДУ 3 И 4
ЗАКАЗАТЬ ПО i.LocationID;
ИДТИ
Вот набор результатов.
ProductID Название LocationID Количество Ранг ----------- ------- ------------ ----- --- ---- 494 Краска - Серебро 3 49 1 495 Краска - Синяя 3 49 1 493 Краска - красная 3 41 3 496 Краска — желтая 3 30 4 492 Краска — черная 3 17 5 495 Краска - Синяя 4 35 1 496 Краска – желтая 4 25 2 493 Краска - красная 4 24 3 492 Краска — черная 4 14 4 494 Краска — серебро 4 12 5 (затронуты 10 строк)
B. Ранжирование всех строк в результирующем наборе
В следующем примере возвращаются десять лучших сотрудников, ранжированных по их зарплате. Поскольку предложение PARTITION BY не было указано, функция RANK применялась ко всем строкам результирующего набора.
Поскольку предложение PARTITION BY не было указано, функция RANK применялась ко всем строкам результирующего набора.
ИСПОЛЬЗОВАТЬ AdventureWorks2012
ВЫБЕРИТЕ ТОП(10) BusinessEntityID, Оценить,
RANK() OVER (ORDER BY Rate DESC) AS RankBySalary
ОТ HumanResources.EmployeePayHistory AS eph2
ГДЕ RateChangeDate = (ВЫБЕРИТЕ МАКС(RateChangeDate)
ОТ HumanResources.EmployeePayHistory AS eph3
ГДЕ eph2.BusinessEntityID = eph3.BusinessEntityID)
ЗАКАЗАТЬ ПО BusinessEntityID;
Вот набор результатов.
BusinessEntityID Ставка RankBySalary ---------------- -------------------- ------------- ------- 1 125,50 1 2 63,4615 4 3 43,2692 8 4 29,8462 19 5 32,6923 16 6 32,6923 16 7 50.4808 6 8 40,8654 10 9 40,8654 10 10 42.4808 9
Примеры: Azure Synapse Analytics and Analytics Platform System (PDW)
C: ранжирование строк в разделе
В следующем примере торговые представители ранжируются в каждой территории продаж в соответствии с их общим объемом продаж. Набор строк разделен на
Набор строк разделен на SalesTerritoryGroup и отсортировано по SalesAmountQuota .
-- Использует AdventureWorks
ВЫБЕРИТЕ Фамилию, СУММУ (SalesAmountQuota) AS TotalSales, SalesTerritoryRegion,
RANK() OVER (PARTITION BY SalesTerritoryRegion ORDER BY SUM(SalesAmountQuota) DESC ) AS RankResult
ОТ dbo.DimEmployee AS e
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.FactSalesQuota AS sq ON e.EmployeeKey = sq.EmployeeKey
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.DimSalesTerritory AS st ON e.SalesTerritoryKey = st.SalesTerritoryKey
ГДЕ SalesPersonFlag = 1 AND SalesTerritoryRegion != N'NA'
ГРУППИРОВАТЬ ПО Фамилии, Региону Территории Продаж;
Вот набор результатов.
Фамилия TotalSales SalesTerritoryRegion RankResult ---------------- --------------------------- ------------------ -- -- ------ Цофлиас 1687000.0000 Австралия 1 Сарайва 7098000.0000 Канада 1 Варгас 4365000.0000 Канада 2 Карсон 12198000.0000 Центральный 1 Варки Чудукатил 5557000.0000 Франция 1 Вальдес 2287000.0000 Германия 1 Блайт 11162000.0000 Северо-Восток 1 Кэмпбелл 4025000.0000 Северо-Запад 1 Ансман-Вулф 3551000.0000 Северо-Запад 2 Менса-Аннан 2753000.0000 Северо-Запад 3 Рейтер 8541000.0000 Юго-Восток 1 Митчелл 11786000.0000 Юго-Запад 1 Ито 7804000.0000 Юго-Запад 2 Пак 10514000.0000 Великобритания 1
 0000 Германия 1
Блайт 11162000.0000 Северо-Восток 1
Кэмпбелл 4025000.0000 Северо-Запад 1
Ансман-Вулф 3551000.0000 Северо-Запад 2
Менса-Аннан 2753000.0000 Северо-Запад 3
Рейтер 8541000.0000 Юго-Восток 1
Митчелл 11786000.0000 Юго-Запад 1
Ито 7804000.0000 Юго-Запад 2
Пак 10514000.0000 Великобритания 1
0000 Германия 1
Блайт 11162000.0000 Северо-Восток 1
Кэмпбелл 4025000.0000 Северо-Запад 1
Ансман-Вулф 3551000.0000 Северо-Запад 2
Менса-Аннан 2753000.0000 Северо-Запад 3
Рейтер 8541000.0000 Юго-Восток 1
Митчелл 11786000.0000 Юго-Запад 1
Ито 7804000.0000 Юго-Запад 2
Пак 10514000.0000 Великобритания 1
См. также
DENSE_RANK (Transact-SQL)
ROW_NUMBER (Transact-SQL)
NTILE (Transact-SQL)
Функции ранжирования (Transact-SQL)
Встроенные функции (Transact-SQL)
Введение в Ранговая функция в SQL
В SQL обычно выполняются различные агрегированные функции, такие как MIN, MAX и AVG. После выполнения этих функций вы получите вывод в виде одной строки. Чтобы определить ранги для каждого поля отдельно, SQL-сервер предоставляет функцию RANK(). Функция RANK() присваивает ранг, то есть целое число, каждой строке в группе наборов данных. Функция RANK() также известна как оконная функция. Прежде чем использовать функцию MYSQL RANK(), важно определить три вопроса:
- Ранг какой?
- В какой группе?
- По какому рангу?
Теперь давайте рассмотрим базовый синтаксис функции RANK() в SQL.
Синтаксис
ВЫБЕРИТЕ имя_столбца,
RANK() OVER (PARTITION BY… ORDER BY…) как ранг
ОТ имя_таблицы;
В этом синтаксисе:
- Имя_столбца представляет столбец, который вы хотите ранжировать в таблице
- Предложение PARTITION BY делит строки набора результатов на разделы на основе одного или нескольких параметров
- Предложение ORDER BY сортирует строки в каждом разделе, где применяется функция
Пример
Давайте рассмотрим приведенную ниже таблицу, чтобы ранжировать данное ИМЯ СТУДЕНТА на основе ОЦЕНОК СТУДЕНТОВ.
Приведенный ниже код будет ранжировать StudentName на основе StudentMarks, поскольку рейтинг будет храниться в новом столбце StudentRank.
Выход
Как видите, ученики ранжированы в соответствии с их оценками в приведенной выше таблице.
Использование функции SQL RANK() для набора результатов
В этом примере вы узнаете, как использовать функцию RANK() для набора результатов. Данный запрос используется для ранжирования всех студентов на основе их оценок.
Данный запрос используется для ранжирования всех студентов на основе их оценок.
Теперь давайте посмотрим на результат вышеуказанного запроса.
Выход
Как видно из приведенного выше примера, предложение PARTITION BY отсутствует, поэтому запрос обрабатывает весь результирующий набор как один раздел.
Предложение ORDER BY используется для сортировки строк на основе оценок учащихся. Затем функция RANK() применяла результаты в строках в порядке убывания оценок учащихся.
Использование функции SQL RANK() над разделом
Теперь, чтобы понять функцию RANK() над разделом, добавьте еще 3 строки в таблицу, которую вы создали ранее, чтобы лучше понять предложение PARTITION BY.
Теперь это таблица, к которой вы будете применять функцию RANK(). В приведенную выше таблицу вы добавили еще 3 учащихся: Питера, Боба и Ким.
Выход
Примечание: приведенная выше таблица разделена по названию класса, и каждый учащийся в каждом классе оценивается по-разному. Это означает, что предложение ORDER BY применяется к каждому разделу отдельно, как упоминалось ранее.
Это означает, что предложение ORDER BY применяется к каждому разделу отдельно, как упоминалось ранее.
Учащиеся каждого класса распределяются отдельно и ранжируются соответственно. В каждом 10-м, 4-м и 7-м классах есть только один ученик, поэтому учащиеся этих классов имеют ранг 1.
В классе 3 учатся три разных ученика, поэтому они ранжируются в порядке убывания оценок учащихся, как указано в пункте ORDER BY. Точно так же были ранжированы учащиеся 9-го класса. Поскольку у них обоих одинаковые отметки, они оба получают ранг 1.
Получите опыт работы с новейшими инструментами и методами бизнес-аналитики с помощью Программы сертификации бизнес-аналитиков. Зарегистрируйтесь сейчас!
Заключение
На этом мы подошли к концу функции Rank() в SQL. Теперь, когда вы узнали о функции Rank(), пришло время изучить и изучить другие функции и предложения, предоставляемые SQL-сервером, и стать экспертом в этой области. Если вы хотите пройти сертификацию и освоить SQL от А до Я, вы должны пройти сертификационный курс Simplilearn по SQL.