| ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
| © 2006-2023 Издательство ГРАМОТА разработка и создание сайта, поисковая оптимизация: | ||||||||||
 Бесплатный просмотрщик PDF-файлов можно скачать здесь.
Бесплатный просмотрщик PDF-файлов можно скачать здесь. с англ. К. Голубович, К. Чухрукидзе, Т. Дмитриева. М.: Логос, 2000. 448 с.
с англ. К. Голубович, К. Чухрукидзе, Т. Дмитриева. М.: Логос, 2000. 448 с. ru
ruранжирование требований и анализ поведенческих переменных — Офтоп на vc.ru
Казалось бы, ваши копирайтеры хорошо постарались и изложили на сайте всю возможную информацию о продукте и его использовании, которая может интересовать потребителя. Но в техподдержку продолжает поступать большое количество звонков по самым рутинным вопросам, ответы на которые точно есть в разделе «Помощь». Возможно, пользователи просто заблудились в дебрях информационной архитектуры сайта компании.
1092
просмотров
Как выявить «узкие места» и с помощью методики ранжирования требований вывести посетителя из этого информационного лабиринта, расскажем в статье.
Проблема, задачи и выбор методики решения
Заказчик из банковской сферы обратился к нам с проблемой: его клиенты при возникновении вопросов не приходят в соответствующий раздел сайта, а обращаются в лучшем случае – на горячую линию техподдержки, в худшем – ко внешним источникам. В итоге колл-центр загружен вопросами, которые должен был решить соответствующий раздел сайта. А пользователи, не находя там ответов на свои вопросы, вынуждены покинуть сайт и искать решение вовне, иногда попадая в неблагонадежные руки. Стоит ли говорить, что это ведёт заказчика к потере потенциальных клиентов?
В итоге колл-центр загружен вопросами, которые должен был решить соответствующий раздел сайта. А пользователи, не находя там ответов на свои вопросы, вынуждены покинуть сайт и искать решение вовне, иногда попадая в неблагонадежные руки. Стоит ли говорить, что это ведёт заказчика к потере потенциальных клиентов?
Перед бизнесом встали следующие задачи:
- задержать клиента на сайте,
- увеличить конверсию (долю посетителей сайта, воспользовавшихся банковским продуктом),
- предотвратить мошенничество и обращение клиентов ко внешним источникам,
- уменьшить количество звонков в техническую поддержку сайта, тем самым сократить нагрузку на специалистов,
- повысить лояльность клиента за счет решения его вопросов и обеспечить повторное посещение сайта.
Для решения поставленных задач мы применили подход ранжирования требований. Подробнее о нем можно прочитать в своде знаний для бизнес-аналитиков BABOK.
Для использования этой методики у нас было всё необходимое:
- Набор пользовательских кейсов, который определили в соответствии с полученной информацией о посетителях сайта и их действиях. Он был необходим для кластеризации персонажей.
- Набор данных по сайту (метрики о полезности статей, о количестве переходов, о переходах по формам, а также SEO-метрики). По ним можно было судить о проблемах клиентов и строить гипотезы.
Нам потребовалось выполнить следующие действия:
- составить Customer Journey Map и выявить узкие места,
- кластеризовать персонажей, т.е.определить группы пользователей,
- выявить основные требования пользователей, т.е. проблемы, которые у них возникают при взаимодействии с UI сайта, определить их вес и проранжировать,
- предложить пути решения.
Итак, обо всем по порядку.
Составление Customer Journey Map и выявление узких мест
Для визуализации клиентского опыта пользования сайтом и выявления узких мест составили Customer Journey Map.
На основании имеющихся на входе метрик и информации по обращениям в службу технической поддержки мы определили три основных «точки входа» пользователя.
- Звонок в контакт-центр (КЦ).
- Поиск в Google.
- Поиск ответа на сайте.
Схема позволила нам выделить следующие узкие места:
- Текущая информационная архитектура контента на сайте сложная и нелинейная. На основе обратной связи мы установили, что пользователи, пытаясь найти ответ, начинают ходить по разным разделам и могут потеряться.
- Информационная перегруженность сайта заказчика пугает пользователя. Он приходит с проблемой, но видит, что сначала ему придется разобраться в интерфейсе. А это прибавляет ситуации напряженности. Главная страница раздела “Помощь” охватывает большое количество контента и предлагает посетителю совершить множество действий. Но её цель – успокоить пользователя, дать понять, что его проблему решить легко, и предложить выполнить всего одно или два действия.

- На странице помощи с формой составления обращения отсутствовали какие-либо инструкции. Пользователи отмечали, что им непонятно, что нужно делать.
- При неудачном совершении операции на сайте клиенты не получали информации о том, что именно пошло не так, и инструкции, что делать в этом случае. Таким образом, нарушен принцип UX-writing (компактно, понятно, полезно) – пользователь остается наедине с нерешенной проблемой и сообщением «Ошибка платежа, платеж отклонен».

Кластеризация персонажей
На основании уже имеющихся данных мы выделили следующие группы пользователей:
- Потенциальный клиент: еще не пользуется продуктами банка, но интересуется ими.
- Неактивный клиент: использует продукты банка очень редко.
- Активный клиент: широко использует продукты банка в повседневной жизни и для бизнеса.
В вашем случае персонажей может быть больше, но в той ситуации нам было достаточно трех. Если их получается много, и вы не знаете, какие группы исключить, можно построить дендрограммы. Если достаточно очевидно, что один персонаж может поглотить другого, можно обойтись без схем.
Если их получается много, и вы не знаете, какие группы исключить, можно построить дендрограммы. Если достаточно очевидно, что один персонаж может поглотить другого, можно обойтись без схем.
Для решения этого кейса нам не требовалось описание персонажей. Но, как правило, чтобы дальше работать над целевой аудиторией, на каждого из них нужно составить карточку, обрисовать портрет (место работы, возраст, привычки и т.п.). К тому же, это может быть полезным при проработке отдельных процессов и улучшении UX сайта.
Выявление основных проблем пользователей при взаимодействии с UI сайта
На основе данных метрик и обращений в техподдержку мы составили таблицу.
Обращения проранжировали по фразам, несущим смысловую нагрузку. Учитывались только данные по тем пользователям, которые перед звонком в техподдержку пытались найти ответ на свой вопрос на сайте, но не смогли из-за его сложной структуры или отсутствия релевантного контента.
Больше всего обращений пользователей содержали слова «Перевод», «Карты», «Оплата», «Пополнение». Реже встречались «Идентификация», «Информация о банке». Практически не встречались «Авторизация», «Регистрация», «Безопасность». Это говорило о том, что с данным разделом всё в порядке, и пользователь знаком с ним.
Данные по SЕО-метрикам, переходам по статьям и формам также оказались полезными для анализа. С учетом имеющихся сведений мы сделали вывод, что в поисковых запросах люди в основном искали следующее: «Что это», «(наименование банка) – это», «Что такое (наименование банка)». По ним они и переходили на соответствующую статью на сайте.
И если взглянуть на данные метрик переходов по статьям, становится понятно, что пользователи не обращались за помощью по запросам, на которые больше всего информации представлено на главной странице банка. В нашем случае: «Идентификация», «Регистрация», «Мобильное приложение».
После анализа данных у нас появились основные поведенческие переменные. Под этим термином мы подразумеваем то или иное требование пользователя, т.е. потребность, за удовлетворением которой он приходил на сайт заказчика. Далее мы работали именно с ними.
Под этим термином мы подразумеваем то или иное требование пользователя, т.е. потребность, за удовлетворением которой он приходил на сайт заказчика. Далее мы работали именно с ними.
На следующем шаге нам нужно было определить вес каждой поведенческой переменной с точки зрения определенных ранее персонажей (в нашем случае использовалась шкала от 0 до 3). Этот показатель обозначает, насколько та или иная переменная значима для конкретной группы пользователей. Например, для сегмента «Активный клиент» авторизация более важна, чем для «Потенциального клиента», так как у активного есть потребность в регулярном использовании данной фичи, а у потенциального нет.
Расчет веса требования пользователя (от 0 до 3)
Коэффициент ценности группы показывает, насколько важна та или иная группа пользователей с точки зрения бизнеса, какой вклад она вносит. Этот показатель мы распределили на основании гипотезы:
- потенциальный клиент вносит средний вклад;
- неактивный клиент – самый минимальный вклад;
- активный клиент – основной вклад.
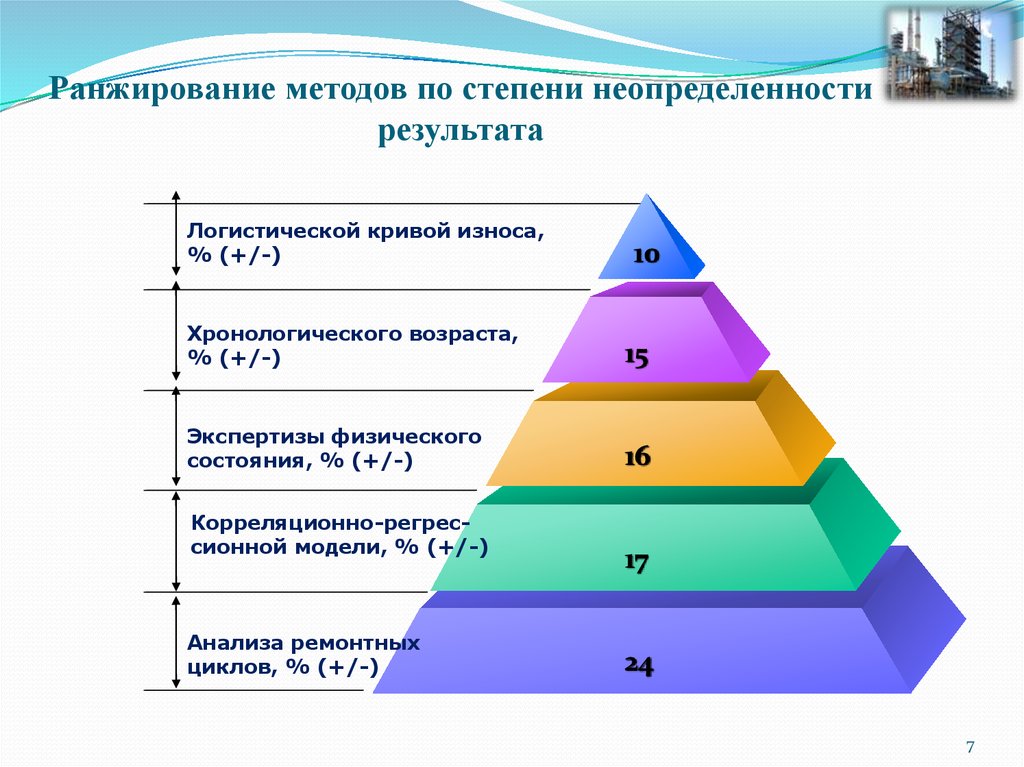
Далее переменные были умножены по каждому сегменту (Вес требования х Коэффициент ценности). Результат мы суммировали по горизонтали. После выполнения несложных математических действий у нас получилась следующая картина.
Расчет ценности группы (от 0 до 3)
Разработка рекомендаций для клиента
Метрики и полученные данные позволили нам сделать вывод о том, что больше всего пользователей волнуют следующие вопросы:
- пополнение,
- оплата,
- перевод,
- карты и информация о банке (продуктах банка).
Полученные результаты позволили:
- Сформировать структуру раздела «Помощь» из трех уровней: категории, тематики, статьи.
- На основе запросов пользователей определить тематики и статьи.
- Обозначить порядок верхнего уровня (категорий) и состав тематик по каждой категории. При формировании категорий мы учли, что при просмотре страницы фокус внимания направлен на центральную часть, а затем перемещается слева-направо.
- Описать состав каждой категории.
 При формировании категорий мы учли, что при просмотре страницы фокус внимания направлен на центральную часть, а затем перемещается слева-направо.
При формировании категорий мы учли, что при просмотре страницы фокус внимания направлен на центральную часть, а затем перемещается слева-направо.При проработке структуры разделов учли, что у бизнеса могут быть свои требования и ограничения. В нашем случае было необходимо сохранить блоки «Безопасность» (требование законодательных актов) и «Идентификация» (приоритет услуги с точки зрения бизнеса).
Итоговая структура раздела «Помощь» приняла следующий вид:
- Пополнение и платежи.
- Карты.
- Информация о счёте.
- Безопасность.
- Идентификация.
- Другие продукты.
По итогам проекта заказчик отметил, что поставленные цели были достигнуты: сократилось количество обращений в техподдержку и возросла удовлетворённость клиентов продуктом, пользователи получили возможность быстро и без усилий находить на сайте ответы на актуальные для них вопросы.
В ходе работы с этим клиентом мы применяли и другие виды исследований UX. Подробнее можете прочитать в наших прошлых статьях. Например, о принципах UI/UX или о том, как подготовить UX-интервью.
А 11 декабря с 12:00 (по мск) приглашаем вас присоединиться к секции Analytics & Design на Big Stream. Наши эксперты расскажут, какой аналитик нужен сегодня в разработке и как собрать качественные требования в формате онлайн, как найти свой продукт (идеи, стратегии и методологии запуска), а также развенчают 7 мифов о работе веб-дизайнера и др. Приходите, будет интересно и полезно.
Иерархия данных исследований – от хорошо проведенного метаанализа до серии небольших случаев .
Доказательную медицину описывают как «добросовестное, явное и разумное использование наилучших современных доказательств при принятии решений о лечении отдельных пациентов». 1 Это включает в себя оценку качества наилучших доступных клинических исследований путем критической оценки методов, описанных исследователями в их публикациях, и интеграции этого с клиническим опытом. Хотя это вызвало споры, иерархия доказательств лежит в основе процесса оценки.
Хотя это вызвало споры, иерархия доказательств лежит в основе процесса оценки.
Ранжирование дизайнов испытаний
Иерархия показывает относительный вес, который можно присвоить конкретному дизайну исследования. Как правило, чем выше рейтинг методологии, тем более надежной она считается. В верхней части находится метаанализ — синтез результатов ряда подобных испытаний для получения результата с более высокой статистической мощностью. На другом конце спектра лежат отчеты об отдельных случаях, которые, как считается, обеспечивают самый слабый уровень доказательств.
Было предложено несколько возможных методов ранжирования дизайнов исследований, но один из наиболее широко распространенных приведен ниже. 2 Информацию о дизайне отдельных исследований можно найти в другом месте в Разделе 1A.
- Систематические обзоры и метаанализы
- Рандомизированные контролируемые испытания
- Когортные исследования
- Исследования случай-контроль
- Поперечные обследования
- Серия случаев и отчеты о случаях
Проблемы и предостережения
Иерархия широко распространена в медицинской литературе, но были высказаны опасения по поводу ранжирования доказательств по сравнению с тем, что наиболее актуально для практики. Особые опасения выделены ниже.
Особые опасения выделены ниже.
- Техники ниже по рангу не всегда лишни. Например, связь между курением и раком легких первоначально была обнаружена в ходе исследований случай-контроль, проведенных в 1950-х годах 3 . Хотя рандомизированные контролируемые испытания (РКИ) считаются более надежными, во многих случаях проводить РКИ было бы неэтично. Например, при изучении воздействия фактора риска вам потребуется когорта, подвергшаяся воздействию фактора риска случайно или по личному выбору.
- Иерархия также не является абсолютной. Хорошо проведенное обсервационное исследование может предоставить более убедительные доказательства эффективности лечения, чем плохо проведенное РКИ.
- Иерархия в основном сосредоточена на количественных методологиях. Тем не менее, снова важно выбрать наиболее подходящий дизайн исследования для ответа на вопрос. Например, часто невозможно установить, почему люди выбирают тот или иной образ действий, не используя качественный метод, такой как опрос.

Были предложены альтернативы традиционной иерархии доказательств. Например, система GRADE (степени рекомендации, оценки, разработки и оценки) классифицирует качество доказательств не только на основе дизайна исследования, но и потенциальных ограничений и, наоборот, обнаруженных положительных эффектов. Например, обсервационное исследование может быть определено как доказательство низкого качества. Однако они могут быть понижены до «очень низкого» качества, если в дизайне исследования есть явные ограничения, или могут быть повышены до «умеренного» или «высокого» качества, если они показывают большую величину эффекта или градиент доза-реакция.
Система оценки суммирована в следующей таблице (воспроизведена из 4 ):
Диаграмма вставки. Медицина также разработала индивидуальные уровни доказательности в зависимости от типа клинического вопроса, на который необходимо ответить. Например, чтобы ответить на вопросы о том, насколько распространена проблема, они определяют лучший уровень доказательности как локальное и текущее случайное выборочное обследование, а систематический обзор является вторым лучшим уровнем доказательности. Полную таблицу рассмотренных типов клинических вопросов и уровней доказательности для каждого можно найти здесь. 5
Полную таблицу рассмотренных типов клинических вопросов и уровней доказательности для каждого можно найти здесь. 5
Ссылки
- Сакетт Д.Л., Розенберг В.М., Грей Дж.А., Хейнс Р.Б., Ричардсон В.С. Доказательная медицина: что это такое, а что нет. БМЖ 1996: 312:7023
- Guyatt GH, Sackett DL, Sinclair JC, Hayward R, Cook DJ, Cook RJ. Путеводители по медицинской литературе. IX. Метод классификации медицинских рекомендаций. ЯМА 1995; 274:1800-4.
- Кукла Р и Хилл АБ. Курение и рак легких. БМЖ 1950; 2:739.
- Такада Т., Страсберг С., Соломкин Дж. и др. Обновленные Токийские рекомендации по лечению острого холангита и холецистита. Журнал гепато-билиарно-панкреатических наук 2013; 20: 1-7.
- Оксфордский центр доказательной медицины. Уровни доказательности, 2011 г.
Дополнительная литература
- Гринхал Т. Как читать статью: Основы доказательной медицины. Лондон: BMJ, 2001 г.
- Guyatt G, Rennie D et al. Руководства пользователя по медицинской литературе: руководство по доказательной клинической практике. McGraw-Hill Medical, 2008.
 Лондон: BMJ, 2001 г.
Лондон: BMJ, 2001 г.© Helen Barratt 2009, Saran Shantikumar 2018
Руководство для начинающих по рейтингу. нужно знать о создании и запуске эффективного исследовательского проекта ранжирования стека пользователей.
Введение
Ранжирование стека — это исследовательский метод измерения важности или приоритета набора вариантов для группы людей. Исследование ранжирования стека превращает набор качественных утверждений в количественные результаты, помогая вам принимать более обоснованные и уверенные решения на основе реальных данных.
Ранжирование стека полезно, когда вы хотите:
Перевести свою команду из нерешительной инерции в действие, добавляя данные к процессу принятия решений.
Расставьте приоритеты, на каких проблемах клиентов или идеях по функциям следует сосредоточиться в дорожной карте вашего следующего продукта.
Определите, какие проблемы оказывают наибольшее влияние на ваших пользователей, клиентов или сообщество.
Поймите разницу в приоритетах, существующих между слоями людей.
Предоставьте своим заинтересованным сторонам активное место за столом переговоров, структурировав их мнения и отзывы.

Об этом руководстве Stack Ranking 101
Наша цель в этом руководстве — дать вам простые практические советы по эффективному ранжированию онлайн-стеков. Интернет полон полезных советов по личным модерируемым упражнениям по ранжированию, таким как сортировка карточек. Вместо того, чтобы добавлять к этому богатству информации, мы собираемся сосредоточиться конкретно на проведении исследовательских проектов онлайн-рейтинга стека.
Практический пример → как ранжирование стека спасло неудачный стартап
Лучший способ понять новую концепцию — увидеть ее в действии в реальной жизни, поэтому давайте сразу перейдем к самой лучшей части…
Еще в марте 2021 года я впервые использовал ранжирование стека, чтобы попытаться понять, почему мы не имел никакой поддержки в моем стартапе на ранней стадии через 6 месяцев после запуска..jpg) Мы разработали и запустили несколько проектов ранжирования стека всего за несколько часов. К концу той же недели вся наша таблица метрик сияла, как рождественская елка — мы умножили количество привлечений, активаций, конверсий, рефералов и количество отзывов клиентов всего за несколько дней после внедрения результатов нашего исследования ранжирования стека.
Мы разработали и запустили несколько проектов ранжирования стека всего за несколько часов. К концу той же недели вся наша таблица метрик сияла, как рождественская елка — мы умножили количество привлечений, активаций, конверсий, рефералов и количество отзывов клиентов всего за несколько дней после внедрения результатов нашего исследования ранжирования стека.
На следующей неделе я написал краткий пример из практики и пошаговое руководство, описывающее исследовательский подход, которого мы придерживались. На следующий день это тематическое исследование было одним из 10 лучших постов о стартапах за все время на Reddit, и им поделились ведущие издания, такие как Techstars и First Round Review. Мы неосознанно создали совершенно новый способ для стартапов проверять свои идеи и ценностные предложения.
Ознакомьтесь с этим примером и руководством, которое с тех пор использовалось исследователями в сотнях компаний, включая Canva, Google и Spotify — здесь .
Происхождение ранжирования стека для исследования пользователей
Когда большинство людей слышат о «ранжировании стека», они думают о старой школе вознаграждения сотрудников и отделах кадров. Однако в мае 2020 года бывший руководитель продукта в Stripe Шреяс Доши представил новое значение ранжирования стека — сравнительное исследование, используемое для понимания ранжированного приоритета набора параметров.
Однако в мае 2020 года бывший руководитель продукта в Stripe Шреяс Доши представил новое значение ранжирования стека — сравнительное исследование, используемое для понимания ранжированного приоритета набора параметров.
Хотя введение Шреяса в ранжирование стека проблем клиентов (CPSR) вызвало волну интереса к ранжированию стека для исследования пользователей, в нем отсутствуют конкретные шаги для его использования. Это руководство использует концепцию CPSR Шреяса и превращает ее в надежный, воспроизводимый и масштабируемый метод исследования , чтобы вы могли успешно использовать ранжирование стека как часть своего инструментария исследования пользователей.
Когда использовать стековое ранжирование для исследования пользователей
Прежде чем перейти к методам сбора данных, нам сначала нужно задать себе более важный вопрос → является ли стековое ранжирование подходящим методом исследования для моего проекта?
Рейтинг стека хорошо подходит для исследовательских проектов со следующими целями:
Вы пытаетесь превратить качественные выводы в количественные данные (т.
е. смешанные методы исследования).Ваш набор данных является сравнительным, т.е. каждый вариант исходит из общей категории/темы/точки зрения и, следовательно, может быть легко сравним между участниками.
У вас есть пул участников, которых вы планируете привлечь в рамках сбора данных, будь то 3 ваших товарища по команде, 300 человек, которых вы наняли у стороннего поставщика, или 30 000 ваших собственных пользователей. Рейтинг стека не предназначен для одиночной игры.
 е. смешанные методы исследования).
е. смешанные методы исследования).Различные типы ранжирования по стеку
Ранжирование по стеку — это исследовательский метод, который предполагает, что людей просят сравнить набор утверждений и выбрать те из них, которые наиболее важны для них. В зависимости от вашей цели вы можете запустить два различных типа проектов ранжирования стека:
Рейтинг закрытого стека: Участники голосуют за заранее определенный набор утверждений, чтобы их можно было ранжировать по общей важности для группы.
Рейтинг Open Stack: Участники голосуют за существующие утверждения, но также могут отправлять новые утверждения, которые модератор может добавить в список для голосования в середине проекта. Также может называться Hybrid .
Рейтинг Stack наиболее известен результатами своего исследования — он переводит качественные параметры (утверждения, изображения, мнения) в данные с количественным ранжированием (оценка важности, измерение ценности, ранжирование по приоритетам). Поэтому существует ряд методов сбора данных, которые вы можете использовать в рамках эксперимента по ранжированию стека:
Ранг заказа: представить участникам полный список опций, которые каждый из них вручную расположит в порядке от самого высокого до самого низкого приоритета.
Парный ранг: выбирает пары опций, между которыми участник может выбирать между прямыми сравнениями, которые используются для расчета общей важности. Также может называться Попарное сравнение .
Анализ MaxDiff: представляет участникам список вариантов и просит их выбрать варианты с наивысшим и наименьшим приоритетом, обычно повторяющиеся несколько раз с автоматически меняющимся списком. Примечание. Вы не можете добавлять новые параметры в свой опрос MaxDiff в середине проекта, поэтому его можно использовать только для закрытого ранжирования стека.
Уровень ползунка: переместите ползунок, чтобы показать, какую степень важности представляет для участника каждый параметр. Этот метод сбора данных является наименее сравнительным и поэтому часто приводит к результатам с очень небольшими различиями в среднем ответе (все, как правило, получают оценку около 5,5–8 из 10). Лучше всего подходит для проектов, которые стремятся понять диапазон воспринимаемой важности каждого варианта, показывая, существует ли консенсус относительно его позиции в рейтинге.
В настоящее время единственным методом ранжирования стека, который предлагает OpinionX, является парный рейтинг (порядковый рейтинг планируется добавить в июне 2022 года).
Выбор правильного типа метода сбора данных для вашего проекта ранжирования стека
Каждый метод сбора особенно подходит для проектов с определенными характеристиками, а это означает, что метод сбора, который вы используете, не должен быть определен заранее, пока не будут поняты эти характеристики:
10 или меньше опций
Проекты с не более чем 10 вариантами ранжирования, например варианты ранжирования, предложенные на собрании небольшой группы, хорошо подходят для Ранга заказа . Как только вы пройдете 10 опций, качество и надежность пользовательского ввода резко снизятся.
10+ вариантов
Проекты ранжирования стека с более чем 10 вариантами лучше всего подходят для Парного ранга , так как это сводит к минимуму объем работы и когнитивную нагрузку, которые возлагаются на участника. Проекты Pair Rank на OpinionX, такие как упражнения по расстановке приоритетов дорожной карты, обычно объединяют более 30 вариантов ранжирования, разбивая общий список голосования на простые парные сравнения, которые в целом накапливаются в тысячи голосов, которые автоматически анализируются.
Небольшие пулы участников
Из-за алгоритмической природы проектов Pair Rank вы должны стремиться к 3-5-кратному количеству участников по сравнению с количеством вариантов (т.е. 20 вариантов означают 60+ участников). Поэтому, если у вас небольшой набор участников, ваш проект, скорее всего, лучше всего подходит для использования Order Rank .
Темы, которые не вызывают сильного отклика
Когда темы исследования не имеют широкого распространения мнений среди участников, MaxDiff Analysis помогает увеличить разницу во мнениях, сосредоточив внимание на лучшем и худшем воспринимаемых вариантах из общего набора. Например, если ваш список опций представляет собой довольно высокоуровневые категории, а не конкретные формулировки проблемы, вы должны использовать MaxDiff как форму анализа «наилучшего-худшего масштабирования».
Доверительные интервалы в качестве выходных данных
Если вас не интересует фактическое ранжирование стека для каждого варианта и вместо этого вас больше интересует измерение согласованности ранжирования, Slider Rank предлагает доверительные интервалы для среднего входного значения, помогая вам построить график диапазон приоритетов, которые участники считают по отношению к каждому варианту.
Исследовательские проекты с несколькими категориями вариантов, которые необходимо сравнить
Ранжирование стека, как описано в этом руководстве, относится к сравнению вариантов из одной темы, категории или точки зрения. Если у вас есть несколько тем, но вам нужно сравнить комбинации вариантов по темам, рассмотрите более сложный метод исследования, такой как Совместный анализ .
Рейтинг открытых и закрытых стеков
В июне 2021 года мы провели исследование всех успешных проектов ранжирования стеков, которые были запущены на OpinionX, и обнаружили, что 81% проектов завершились с отправленным пользователем мнением в топ-3 самых высоких заявления о приоритете.
Проекты ранжирования стека часто сосредоточены на количественной оценке проблем или мнений членов сообщества, и эти члены сообщества, как правило, понимают эти проблемы или могут сформулировать эти мнения лучше, чем мы, как сторонние исследователи. Поэтому неудивительно, что отчеты, собранные в середине проекта, часто занимают очень высокое место в рейтинге стека.
Open Stack Ranking использует процесс, который мы называем «краудсорсингом ваших пробелов». Это просто относится к использованию поля Open-Response в вашем рейтинговом опросе стека для сбора новых заявлений, а затем ручному добавлению любых соответствующих заявлений, представленных пользователями, в ваш список для голосования простым нажатием кнопки.
Поскольку опросы по ранжированию стека являются сравнительными, специально созданные инструменты, такие как OpinionX, используют алгоритмы для сравнения любых новых мнений с оценками старых, чтобы они могли быстро «догнать» голосование, позволяя вам добавлять новые мнения, свои или отправленные пользователями в любой момент вашего проекта ранжирования стека.
Создание списка вариантов ранжирования стека
Стремитесь к 10-30 вариантам
Хотя жесткого ограничения нет, мы рекомендуем иметь не менее 10 мнений, потому что алгоритм подсчета очков для парного рейтинга работает лучше всего, когда он имеет много разных варианты для сравнения при личном голосовании.
Мы также рекомендуем ограничиться 30 вариантами, потому что Pair Rank работает лучше всего, когда у вас в 3-5 раз больше участников, а это значит, что вам потребуется 100+ участников для проекта с более чем 30 вариантами. Кроме того, если вы ограничите себя 30 вариантами, у вас будет возможность добавлять краудсорсинговые мнения ваших участников в ваш список для голосования в середине проекта.
Советы по составлению хороших отчетов о рейтинге стека
Существует ряд простых принципов, которые следует учитывать при мозговом штурме или составлении отчетов о рейтинге стека:
Краткий
В OpinionX мы экспериментировали с длиной операторов и обнаружили, что все, что превышает 180 символов, приводит к резкому увеличению мгновенных голосов, т.е. участники быстро щелкают, чтобы пропустить упражнение по ранжированию стека.
Последовательный
Как правило, мы рекомендуем писать все утверждения от первого лица, чтобы они соответствовали точке зрения вашего участника, например. «Мне сложно ориентироваться в документации по продукту». Какой бы подход вы ни выбрали, соблюдайте его постоянство, чтобы участники рассматривали все утверждения с одной и той же точки зрения.
Анонимный
Утверждения не должны включать личные данные, иначе они не будут иметь отношения к большинству участников и будут иметь низкий рейтинг (что может ввести вас в заблуждение, заставив думать, что основная тема не важна). Это особенно актуально для новых мнений, представленных участниками, однако вам предоставляется возможность вручную редактировать любые краудсорсинговые заявления, прежде чем они будут добавлены в список для голосования.
Дискретный
Каждое утверждение должно иметь только одну уникальную переменную, чтобы участники могли сравнить его с другими вариантами. Если вы включите несколько баллов в одно утверждение, вы не будете знать, какой из них больше всего повлиял на его окончательный рейтинг.
Сфокусирован на проблеме
Идеи интерпретируют, проблемы универсальны. Если вы решите ранжировать идеи, вы обнаружите, что каждый участник дает личную интерпретацию того, какую проблему может решить эта идея. Одна идея может быть решением для 3 разных проблем, но как исследователь вы никогда не узнаете, какая проблема больше всего повлияла на голосование участников. Однако хорошо сформулированная проблема универсальна. Все участвуют в голосовании с одной и той же точки зрения, когда варианты ориентированы на проблему.
Различный
Во время прямых сравнений, которые проводятся во время голосования по парному рейтингу, важно, чтобы участник мог определить разницу между каждым вариантом. После того, как вы составили свой список утверждений, проверьте, не вызовут ли какие-либо два утверждения разочаровывающее прямое голосование, потому что они имеют слишком много одинаковых формулировок или значений.
Ранжирование стека — чрезвычайно гибкий формат исследования. Если вы не уверены в своих способностях к ранжированию стека, эти советы помогут вам оставаться на проторенном пути к действенным ранжированным данным. В противном случае не стесняйтесь изменять эти правила там, где считаете нужным 🙂 Конкретные примеры можно найти в этом руководстве по написанию примеров мнений для четырех наиболее распространенных типов проектов ранжирования стека.
Набор участников и управление ими
Сколько участников вы должны набрать?
Для небольших проектов, использующих формат Order Rank, не существует минимального или максимального требования к количеству участников, которых вы должны стремиться привлечь.
Однако при наборе участников для парного рейтингового голосования мы обычно рекомендуем стремиться к как минимум 3-кратному количеству вариантов голосования, которые вы включаете. Это связано с тем, что Pair Rank по умолчанию включает только 10 прямых голосов и основан на алгоритме надежности, поэтому чем больше участников вы привлекаете, тем более уверенным будет алгоритм в результатах ранжирования.
Если у вас есть 25 вариантов парного ранга, вы должны стремиться привлечь 75-125 человек. Это важно знать заранее, потому что, если у вас есть ограниченное количество участников, вам следует соответствующим образом ограничить количество вариантов голосования.
Демографическая согласованность и сегментация
У разных людей разные проблемы, приоритеты и потребности. Если вы привлекаете людей из самых разных слоев общества, ваш рейтинг стека, скорее всего, сойдется в середине и покажет вам, что все имеет одинаковый уровень важности для ваших участников (также известный как «🤷♀️»).
Часто в подобных случаях проблема не в отсутствии интереса или мнения участников. Вместо этого исследователь привлек людей из разных сегментов, у которых были очень разные приоритеты. Используя вопросы с одним или несколькими вариантами ответов для сбора демографических данных о каждом участнике, вы можете затем использовать фильтры сегментации, чтобы сравнить различия между рейтингом для каждой подгруппы ваших участников.
Например, вы, как правило, обнаружите, что самые большие проблемы, с которыми сталкиваются ваши бесплатные пользователи с вашим продуктом, — это очень отличается от проблем, с которыми сталкиваются ваши самые платежеспособные клиенты. Заблаговременное планирование сегментации лежит в основе поиска золотых самородков в ваших результатах.
Сторонний набор
Если у вас недостаточно большая пользовательская база, у вас вообще нет клиентов, потому что вы находитесь перед запуском, или даже если вы просто хотите привлечь непредвзятого, чистого набора участников, тогда вы можете быть заинтересованы в поиске участников через стороннего рекрутера.
Привлечение участников от третьей стороны обычно требует финансового стимула для участников, что делает ваш проект более дорогим. Тем не менее, одним из преимуществ является то, что мотивированные участники с большей вероятностью останутся и выполнят более длительную исследовательскую задачу (в опросах, которые занимают более 5 минут, наблюдается резкое падение как показателей принятия, так и завершения).
Чтобы получить список рекомендуемых сторонних рекрутеров и советы о том, как сделать ваш рейтинговый опрос стека пригодным для проверки поощрений за участие, ознакомьтесь с нашим руководством по базе знаний.
Интерпретация результатов ранжирования вашего стека
Понимание оценок опционов
Хотя заманчиво полагаться на рейтинг опционов в общем наборе, фактическая оценка дает вам гораздо больше информации, чем просто ее положение на подиуме.
Для опросов с парным рейтингом все варианты начинаются с балла по умолчанию, равного 1500, а затем алгоритм рейтинга анализирует все личные голоса, чтобы каждый раз решать, дать ли этому варианту больше баллов или убрать баллы. Когда вариант получает постоянную поддержку участников как одно из наиболее важных заявлений в опросе, он обычно получает более 1800 баллов. Аналогичным образом, вариант, который постоянно проигрывает в большинстве личных голосов, будет иметь оценка 1300 и ниже.
Вместо того, чтобы просто оценивать три верхних варианта как наиболее важные для участников, видя, что разница в 200 баллов между 2-м и 3-м местом говорит вам гораздо больше о взвешивании этой важности.
Выявление идеальных интервьюируемых
Мы большие поклонники исследовательского подхода, который мы называем «Сэндвич открытий», который включает в себя три этапа исследования — обширные качественные интервью, чтобы понять ландшафт вашей «активности фокуса», за которым следует ранжирование стека для количественной оценки вариантов, определенных на этапе 1, после чего начинается второй качественный этап, чтобы исследователь мог углубиться в подтвержденные главные приоритеты.
Ранжирование стека полезно не только как упражнение по расстановке приоритетов путем количественного определения наиболее важных параметров; это также поможет вам выбрать идеальных участников для интервью на этапе 3. У каждого участника есть свой «личный рейтинг стека», который показывает, как они проголосовали за общий набор вариантов.
Сравнивая этот «личный рейтинг в стеке» с вашими окончательными результатами, вы можете определить участников, которые разделяют те же главные приоритеты, что и ваша общая группа или ключевой сегмент, а затем углубиться в них во время последующих интервью. Просто не забудьте включить блок сбора электронной почты, чтобы у вас была контактная информация, связанная с профилем каждого участника!
Пошаговое руководство по разработке проектов исследования рейтинга стека
Итак, вы теперь знаете, что такое рейтинг стека, когда его использовать, как найти участников и на что обращать внимание в результатах. Далее следует конкретный набор шагов для запуска надежных, воспроизводимых, масштабируемых исследовательских проектов ранжирования стека. Давайте углубимся в…
Activity of Focus
Критерий ранжирования
Stack Ranking Question
Опции по сегменту
Планирование для сегментации
Crowdsource Your Dief
Соберите метод контакта
1
Соберите контактный метод
.
Соберите контактный метод
.
Ключом к получению надежных данных является обеспечение того, чтобы каждый участник подходил к голосованию с одинаковой точки зрения. Для этого участникам нужен один и тот же контекст для рассмотрения каждого варианта.
Обычно это принимает форму «активности фокуса» — общего действия или цели, которая служит контекстом для участников при интерпретации вариантов в вашем рейтинговом списке стека. Например, UX-дизайнер, запускающий проект ранжирования стека, целью которого является улучшение опыта адаптации своего продукта, сосредоточится на действии по подписке на продукт.
Существует множество общих категорий «Фокусной активности», которые я встречал в опросах по ранжированию стека, например:
Категория продукта: сосредоточение внимания на конкурентных альтернативах для понимания разочарований/недостатков и определения возможностей рыночной категории (например, «разочарования в вашей текущей CRM»).
Случай: использование конкретного события или повторяющегося обстоятельства для понимания потребностей, выходящих за рамки предложений продуктов (например, «проблемы, возникающие в конце финансового года»).
Вариант использования: понимание особенностей продукта приоритеты клиента на протяжении всего варианта использования, на который вы ориентируетесь (например, «трудности с проведением обзоров производительности»).
Существующее использование: вовлечение ваших существующих клиентов/сообщества, чтобы понять потребности, которые ваш продукт удовлетворяет для них, или почему они решили попробовать ваш продукт в первую очередь (например, «при использовании функции экспорта на OpinionX») .
Шаг 2: Критерий ранжирования
Что вы пытаетесь понять с помощью исследования ранжирования стека?
Возможно, вы пытаетесь выяснить, какие неудовлетворенные потребности ваши пользователи считают наиболее болезненными для решения, какие существующие функции ваши клиенты считают наиболее ценными для них, или какие проблемы группа людей считает наиболее важными. самые важные решить.
Формулировка цели вашего исследования позволяет вам определить ваш критерий ранжирования — валюту, которую ваши участники будут использовать для оценки ваших вариантов при голосовании парами.
Шаг 3: Вопрос ранжирования стека
Этот шаг довольно прост — мы хотим объединить наш Критерий ранжирования и Активность фокуса вместе, чтобы создать наш Вопрос ранжирования стека.
Например, с критерием ранжирования « разочарование » и «сотрудничеством с товарищами по команде над нашим продуктом» в качестве основного вида деятельности мы получаем вопрос → «Какой вариант более разочаровывает при попытке сотрудничать с товарищами по команде над нашим продуктом?» продукт?»
Этот пример подходит для проекта Pair Rank, в то время как вопрос Order Rank может начинаться с «Рассортируйте варианты от наиболее до наименее разочаровывающих при попытке сотрудничать с товарищами по команде над нашим продуктом».
Шаг 4: Заданные опционы
Прежде чем мы сможем ранжировать наш стек опционов, нам нужен набор записанных опционов. Если вы пропустили его, прокрутите страницу вверх до раздела « Создание списка параметров ранжирования стека» ’ для конкретных советов по написанию этих заполненных опций.
Шаг 5: Планирование сегментации
Возможно, самое ценное в ранжировании стека — это не просто количественный список приоритетов людей; это способность понимать различия в приоритетах между разными группами людей.
Используя простые вопросы с несколькими вариантами ответов, вы можете связать демографические данные или данные о клиентах с профилем каждого участника, например, его должность, размер компании или ценовой уровень. Затем эти данные могут помочь вам сравнить ранжированные результаты различных сегментов, таких как пользователи freemium и самые высокооплачиваемые клиенты, чтобы увидеть, как различаются их потребности, ценности или приоритеты.
Дополнительные советы по сегментации см. в нашей публикации «Сегментация на основе потребностей: пошаговое руководство».
Шаг 6. Обсудите свои пробелы с помощью краудсорсинга
Как уже упоминалось в разделе «Рейтинг открытых и закрытых стеков» этого поста, предоставление участникам возможности представить новые мнения, которые вы можете рассмотреть в каждом конкретном случае, помогает чтобы заполнить любые неожиданные пробелы в вашем списке опций.
Эта часть на самом деле довольно проста; вы просто хотите включить в дизайн своего проекта блок открытых ответов, который позволяет участникам по желанию отвечать на вопрос, например « У вас есть мнение, которое вы не увидели при голосовании? Отправьте его ниже, чтобы мы могли добавить его в список. ” Если вы хотите узнать больше о мнениях участников краудсорсинга, ознакомьтесь с этой статьей базы знаний.
Шаг 7. Найдите контактный метод
Стековое ранжирование — отличный способ сузить набор вариантов до проверенного списка приоритетов. Но прежде чем приступить к созданию чего-то нового, я рекомендую следовать подходу Discovery Sandwich — проведите несколько качественных интервью с подтвержденными приоритетами, чтобы как можно глубже понять контекст этой проблемы, идеи или потребности.
Вы хотите брать интервью только у людей, которые также разделяют те же главные приоритеты, что и вся ваша группа или ключевой сегмент. Собирая контактный метод во время опроса о ранжировании стека, например адрес электронной почты, вы можете затем определить участников с наиболее подходящим «личным рангом стека», чтобы запросить последующие подробные интервью.
Шаг 8: Результаты
Рейтинг стека — это надежный, действенный и масштабируемый формат исследования. Но если вы не выберете правильный подход, у вас может возникнуть головная боль, связанная с углубленным анализом. По словам Мики Ричардсона, старшего менеджера по продуктам в Animoto, этот расширенный анализ, как правило, просто не стоит усилий:
» У меня есть количественные навыки, но я не аналитик данных, и моя команда не имела доступа к ним для этого проекта.