Содержание
Семантическое ранжирование — Azure Cognitive Search
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
- Чтение занимает 3 мин
-
Важно!
Семантический поиск предоставляется в общедоступной предварительной версии и к нему применяются дополнительные условия использования. Его можно использовать на портале Azure, через REST API предварительной версии или пакеты SDK бета-версии. Эти функции являются платными. Дополнительные сведения об этом см. в разделе Доступность и цены.
Его можно использовать на портале Azure, через REST API предварительной версии или пакеты SDK бета-версии. Эти функции являются платными. Дополнительные сведения об этом см. в разделе Доступность и цены.
Семантические ранжирование — это расширение конвейера выполнения запросов, которое повышает точность путем повторного ранжирования верхней части списка совпадений исходного результирующего набора. Семантические ранжирование поддерживается большими сетями на основе преобразователя, обученными для захвата семантического значения условий запроса, в отличие от лингвистического сопоставления по ключевым словам. В отличие от алгоритма ранжирования сходства по умолчанию, семантическое ранжирование использует контекст и значение слов для определения релевантности.
Семантические ранжирование требует ресурсов и времени. Чтобы завершить обработку в пределах ожидаемой задержки операции запроса, входные данные для семантического ранжирования объединяются и сокращаются, чтобы можно было как можно быстрее выполнить базовые операции формирования сводных данных и повторного ранжирования.
Предварительная обработка
Перед оценкой релевантности содержимое сокращается до умеренного количества входов, которое можно эффективно обработать семантическим ранжированием.
Сокращение содержимого начинается с начального набора результатов, возвращаемого алгоритмом ранжирования по сходству по умолчанию, который используется для поиска по ключевым словам. Результатом любого запроса может быть несколько документов (до 1000 максимум). Так как обработка большого количества совпадений займет слишком много времени, в семантическом ранжировании будут участвовать только первые 50.
Независимо от числа документов (один или 50) начальный результирующий набор определяет первую версию корпуса документа для семантического ранжирования.
Затем содержимое каждого поля в семантической конфигурации извлекается и объединяется в длинную строку.
После консолидации все слишком длинные сроки обрезаются, чтобы обеспечить соответствие общей длины требованиям к входным данным этапа формирования сводных данных.

В этом упражнении по обрезке важно добавлять поля в семантическую конфигурацию в порядке приоритета. В очень больших документах с полями, содержащими большие объемы текста, все данные, превышающие лимит, игнорируются.

Каждый документ теперь представлен одной длинной строкой.
Примечание
В версии 2020-06-30-preview для определения используемых полей используется параметр searchFields, а не семантическая конфигурация. Для достижения наилучших результатов рекомендуется выполнить обновление до версии API 2021-04-30-preview.
Строка состоит из токенов, а не символов или слов. В строке может быть максимум 128 уникальных токенов. Для оценки можно предположить, что 128 токенов примерно эквивалентны строке длиной 128 слов.
Примечание
Разметка определяется в зависимости от назначения анализатора в полях с возможностью поиска. Если вы используете специализированный анализатор, например nGram или EdgeNGram, может потребоваться исключить это поле из searchFields. Чтобы получить представление о том, как строки размечены, можно проверить выходные данные токена анализатора с помощью анализатора тестов REST API.
Чтобы получить представление о том, как строки размечены, можно проверить выходные данные токена анализатора с помощью анализатора тестов REST API.
После обрезки строк можно передать сокращенные входные данные с помощью моделей машинного чтения и распознавания языка, чтобы определить, какие предложения и фразы лучше всего соответствуют документу с учетом запроса. На этом этапе извлекается содержимое из строки, которая затем будет проходить семантическое ранжирование.
Входы для формирования сводных данных — это длинные строки, получаемые для каждого документа на этапе подготовки. В каждой строке модель формирования сводных данных находит наиболее репрезентативный объект. Она также создает семантический заголовок для документа. Каждый заголовок доступен в виде простой текстовой версии и версии с выделением, и часто составляет менее 200 слов на документ.
Семантический ответ также возвращается, если был указан параметр «Ответы», если запрос был создан как вопрос и если в длинной строке присутствует объект, который, скорее всего, отвечает на вопрос.
Семантическое ранжирование
Заголовки оцениваются с точки зрения концептуальной и семантической релевантности относительно предоставленного запроса.
На следующем рисунке показана схема «семантической релевантности». Рассмотрим термин «капитал», который может использоваться в контексте финансов, законодательства, географии или грамматики. Если запрос содержит термины из одного и того же векторного пространства (например, «капитал» и «инвестиции»), то документ, который также содержит токены в том же кластере, получит более высокий ранг, чем остальные.
Объект @search.rerankerScore назначается каждому документу на основе семантической релевантности заголовка. Оценки варьируются от 4 до 0 (высокий к низким), где более высокий балл указывает на более сильное совпадение.
После оценки все документы отображаются в порядке убывания по оценке и включаются в полезные данные ответа на запрос. Полезные данные включают в себя ответы, обычный текст и выделенные заголовки, а также все поля, помеченные как извлекаемые или указанные в предложении выбора.

Дальнейшие действия
Семантические ранжирование доступно на стандартных уровнях обслуживания в определенных регионах. Дополнительные сведения о доступности и регистрации см. в статье Доступность и цены. Новый тип запроса обеспечивает ранжирование и структуру запросов семантического поиска. Чтобы приступить к работе, настройте семантическое ранжирование.
Кроме того, ознакомьтесь со следующими статьями о ранжировании по умолчанию. Семантические ранжирование зависит от результатов ранжирования по сходству. Знание структуры запросов и ранжирования позволит вам получить общее представление о работе всего процесса.
- Полнотекстовый поиск в когнитивном поиске Azure
- Сходство и оценка в Когнитивном поиске Azure
- Анализаторы для обработки текста в когнитивном поиске Azure
Ранжирование — глоссарий КСК ГРУПП
Вокруг темы ссылочного ранжирования ходит множество всяких разговоров, циркулирует множество слухов и распространяется множество легенд. Некоторые легенды настолько убедительны, что давно перешли в разряд непререкаемых постулатов. Однако это не мешает им оставаться всего лишь красивыми выдумками, не имеющими с реальностью ничего общего. Дело в том, что эти выдумки невозможно ниспровергнуть, но не потому, что нельзя доказать их ложность, а потому, что поддержание их в виде постулатов очень выгодно капитанам СЕО-индустрии и прочим специалистам в теме продвижения сайтов во всех известных сегодня поисковых системах. В этом деле все решает конкуренция, а профессионалам конкуренты не нужны.
Некоторые легенды настолько убедительны, что давно перешли в разряд непререкаемых постулатов. Однако это не мешает им оставаться всего лишь красивыми выдумками, не имеющими с реальностью ничего общего. Дело в том, что эти выдумки невозможно ниспровергнуть, но не потому, что нельзя доказать их ложность, а потому, что поддержание их в виде постулатов очень выгодно капитанам СЕО-индустрии и прочим специалистам в теме продвижения сайтов во всех известных сегодня поисковых системах. В этом деле все решает конкуренция, а профессионалам конкуренты не нужны.
Итак, что можно сказать о ссылочном ранжировании сайтов?
По идее, ссылочное ранжирование обозначает такой важный аспект определения качества любого сайта, как «цитирование» его другими сайтами. И это правильно. Ведь если один сайт сослался на другой, то это значит, что владелец первого сайта счел второй сайт обладателем очень важной и интересной информации, которая хорошо дополняет материалы его сайта, но которую он не имеет возможности разместить на своем сайте. И Google, и Яндекс в свое время ввели специальные «знаки отличия» в виде PR и ТиЦ, которые присваивали всем сайтам в зависимости от их ссылочной массы, и назывались эти отметки «индекс цитирования». Соответственно величине этого «индекса цитирования» и определялось качество сайтов, что достаточно сильно влияло на их позиции в выдаче.
И Google, и Яндекс в свое время ввели специальные «знаки отличия» в виде PR и ТиЦ, которые присваивали всем сайтам в зависимости от их ссылочной массы, и назывались эти отметки «индекс цитирования». Соответственно величине этого «индекса цитирования» и определялось качество сайтов, что достаточно сильно влияло на их позиции в выдаче.
Однако продолжалось это недолго. Появилось слишком много оборотистых дельцов, которые стали предлагать ссылки со своих сайтов на продажу, и очень быстро этот бизнес приобрел такой размах, что в корне изменил отношение пользователей Интернета к поисковым системам. Топы оказались забиты сайтами низкого качества, владельцы которых не поскупились на приобретение ссылок. Предложение настолько превысило спрос, что ссылки очень сильно подешевели, и теперь их мог закупать в больших количествах даже самый финансово несостоятельный веб-мастер. Более того, появилось множество так называемых «ссылочных бирж», которые торговали ссылками оптом и в разницу, самого разного качества и категории. В то же время активизировались адепты различных спам-рассылок, массированно наладившие выпуск специальных программ, которые могли осуществлять сбор ресурсов, в которые можно автоматически производить спам ссылок без всякой модерации.
В то же время активизировались адепты различных спам-рассылок, массированно наладившие выпуск специальных программ, которые могли осуществлять сбор ресурсов, в которые можно автоматически производить спам ссылок без всякой модерации.
В общем, ссылочное ранжирование оказалось совсем не тем фактором, с помощью которого поисковые системы могли бы определять качество сайтов. Начали срочно разрабатываться другие алгоритмы, а сфера ссылочной массы претерпела существенные изменения. Во-первых, поисковые системы стали бороться с продавцами ссылок, но так как эта борьба была весьма неэффективной, то ссылочное ранжирование было вообще отменено. Вернее, оно не перестало играть роль, но теперь далеко не все ссылки стали учитываться. Как и в случае с сайтами, были установлены критерии качества ссылок самыми «очевидными» способами. Например, качественной ссылкой могла быть признана только та ссылка, по которой совершаются регулярные переходы посетителей, то есть людей с реальными IP-адресами, а не ботов-накрутчиков. Однако и тут вышло не все гладко, потому что очень часто реального посетителя от посетителя-накрутчика отличить очень трудно, а то и вовсе невозможно. Пришлось поисковым системам еще больше сжать диапазон учета и признавать только те ссылки, которые ведут с проверенных, авторитетных, «жирных» сайтов.
Однако и тут вышло не все гладко, потому что очень часто реального посетителя от посетителя-накрутчика отличить очень трудно, а то и вовсе невозможно. Пришлось поисковым системам еще больше сжать диапазон учета и признавать только те ссылки, которые ведут с проверенных, авторитетных, «жирных» сайтов.
Конечно, это тоже не в полной мере гарантировало качество ссылки, особенно в свете того обстоятельства, что очень многие «жирные» сайты взламываются хакерами и на них устанавливаются ссылки на сайты, которые качеством уж совсем не блещут. Более того, участились случаи продажи «жирных» сайтов в третьи руки, а вот уже эти «третьи» руки в ряде случаев превращают свои приобретения в «линкофермы». Так что и тут оказалось не все так гладко, как хотелось бы поисковым системам. Ссылочная масса потеряла всякий смысл, и не потому, что концепция продвижения сайтов в топы с ее помощью неверна в принципе, а потому, что имеет многочисленные технические изъяны, с которыми поисковые системы бороться оказались не в состоянии.
На данный момент любой новый сайт может гарантированно продвинуться в топы только одним путем: постоянное добавление контента и его регулярное обновление. Ссылки для нового сайта нужны только для того, чтобы на него смогли перейти поисковые роботы и проиндексировать страницы. Постоянное наращивание ссылок давно уже не приводит к неуклонному продвижению в топы, разве что по малоконкурентным ключевым запросам, да и то не факт. Для того чтобы в этом убедиться, достаточно посетить топы Яндекса или Google по каким-нибудь запросам средней популярности и понаблюдать за сайтами, которые там расположились. Абсолютно все они имеют не так уж и много ссылок, ведущих на них с других сайтов, зато можно заметить, что обновляются они ежедневно.
Однако также можно заметить и то, что продажа ссылок посредством ссылочных бирж по-прежнему популярна. Владельцы многих сайтов и сегодня тратят большое количество денег на приобретение ссылок для продвижения своих сайтов, и это дает основания полагать, что ссылочное ранжирование все же не умерло окончательно. Однако торговля ссылками — это очень прибыльный бизнес, об этом говорилось выше. И владельцы этого бизнеса вовсю поддерживают миф о ссылочном ранжировании, чтобы не потерять хорошую прибыль. Тут в действие вступает так называемая теория больших чисел, которая дополнительно подпитывается фактором случайности.
Однако торговля ссылками — это очень прибыльный бизнес, об этом говорилось выше. И владельцы этого бизнеса вовсю поддерживают миф о ссылочном ранжировании, чтобы не потерять хорошую прибыль. Тут в действие вступает так называемая теория больших чисел, которая дополнительно подпитывается фактором случайности.
Дело в том, что наряду с покупкой ссылок многие веб-мастера занимаются и внутренней оптимизацией своих сайтов, и когда сайт начинает занимать хорошие позиции в топах, то это приписывают действию купленных ссылок, хотя на самом деле эффект дали не ссылки, а правильно проведенная внутренняя оптимизация. Такие случаи мгновенно становятся «достоянием общественности», о них трубят на каждом углу, и создается впечатление, что сайт помогли продвинуть именно купленные ссылки. Те же случаи, когда сайт «не сдвинулся с места», просто замалчивают, приписывая всё ошибкам, допущенным при создании сайта. Это очень распространенный прием, который использовался монополиями всегда и везде при продвижении заведомо негодного продукта, поэтому удивляться тут нечему.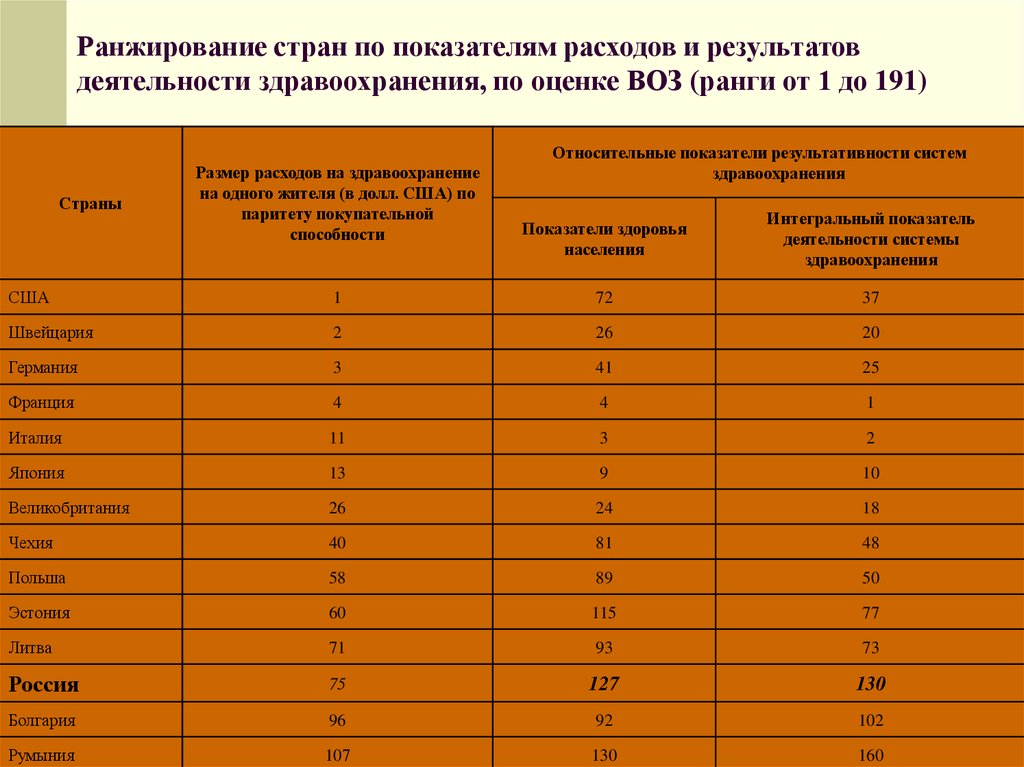 Реклама — двигатель торговли, причем успешно может рекламироваться даже то, что не приносит никому никакой пользы. В случае со ссылочным ранжированием действует как раз тот же самый эффект: люди покупают ссылки, одновременно работая над сайтом, и все успехи записывают насчет ссылок, а неуспехи — только насчет своих неправильных действий по оптимизации. Обвинять в собственных проблемах продавцов ссылок ни у кого не повернется язык.
Реклама — двигатель торговли, причем успешно может рекламироваться даже то, что не приносит никому никакой пользы. В случае со ссылочным ранжированием действует как раз тот же самый эффект: люди покупают ссылки, одновременно работая над сайтом, и все успехи записывают насчет ссылок, а неуспехи — только насчет своих неправильных действий по оптимизации. Обвинять в собственных проблемах продавцов ссылок ни у кого не повернется язык.
Конечно, не все так плохо: существуют, конечно же, ссылки, которые «работают». Но, как правило, это ссылки с очень авторитетных сайтов, которые или не продаются, или стоят так дорого, что используются наемными СЕО-оптимизаторскими компаниями для продвижения сайтов наиболее состоятельных своих клиентов. В качестве примера, чтобы не быть голословным, можно упомянуть такие площадки, как DMOZ или Яндекс-каталог, откуда ссылку получить не так-то и просто, а если и повезет, то это будет по-настоящему хорошая, «жирная» ссылка, которая учитывается всеми поисковиками без всяких ограничений.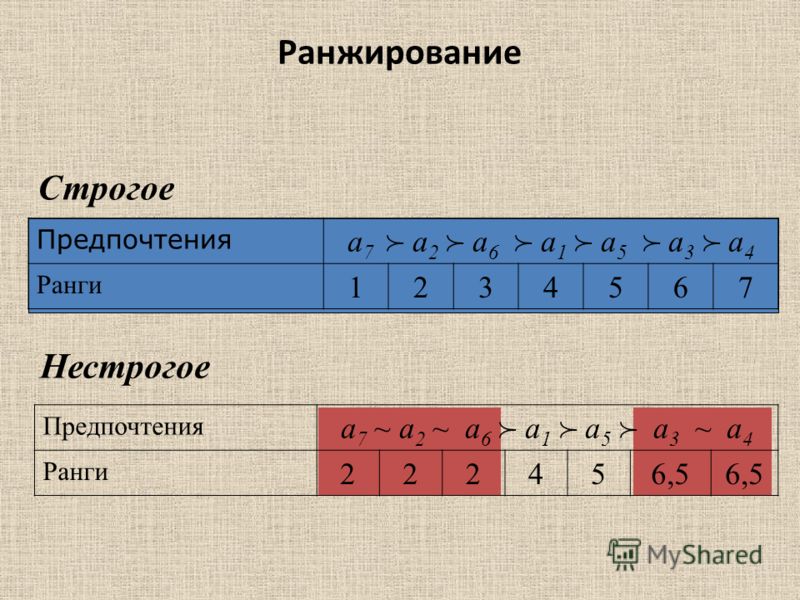 Дело в том, что на этих ресурсах осуществляется настолько жесткая модерация, что «левые» сайты, которые способны заняться продажей ссылок, проникнуть туда просто не в силах. А те, которые все же занимаются продажей, действуют настолько осторожно, что заподозрить их в продаже просто невозможно.
Дело в том, что на этих ресурсах осуществляется настолько жесткая модерация, что «левые» сайты, которые способны заняться продажей ссылок, проникнуть туда просто не в силах. А те, которые все же занимаются продажей, действуют настолько осторожно, что заподозрить их в продаже просто невозможно.
Таким образом, мы видим, что на смену ссылочному ранжированию пришли совсем другие способы успешного продвижения сайтов в топы выдачи всех крупных поисковых систем. И необходимость применения этих способов очень значительно очистила выдачу поисковых систем от всякого веб-мусора. Ведь не каждый веб-мастер способен постоянно обновлять и расширять свой сайт. Те хитрецы, которые ранее не занимались улучшением своих сайтов, используя в качестве двигателя исключительно ссылки, теперь должны или потрудиться, или исчезнуть. Впрочем, продажа ссылок будет процветать еще долго, но это уже касается не темы СЕО-продвижения сайтов в топы поисковых систем, а сферы мошенничества в сети.
Возврат к списку
ИТ-услуги 25 2022 | Brand Value Ranking League Table
2022 | 2021 | Name | Country | 2022 | 2021 | 2022 | 2021 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | акцент | США | $36,190M | $26,028M | AAA | AAA | |
| 2 | 3 | TCS | India | $16,786M | $14,924M | AAA- | AAA- | |
| 3 | 4 | Infosys | India | $12,777M | $8,402M | AAA- | AAA- | |
| 4 | 2 | IBM Consulting | United States | $10,582M | $16,057M | AAA | AAA- | |
| 5 | 5 | Cognizant | United States | $8,735M | $8,032M | AA | AA+ | |
| 6 | 6 | Capgemini | France | $8,166M | $6,750M | AA | AA | |
| 7 | 9 | Wipro | India | $6,364M | $4,301M | AA+ | AA+ | |
| 8 | 7 | HCL | India | $6,102M | $5,524M | AA+ | AA+ | |
| 9 | 8 | Ntt Data | Япония | $ 5,760M | $ 5 081 мл.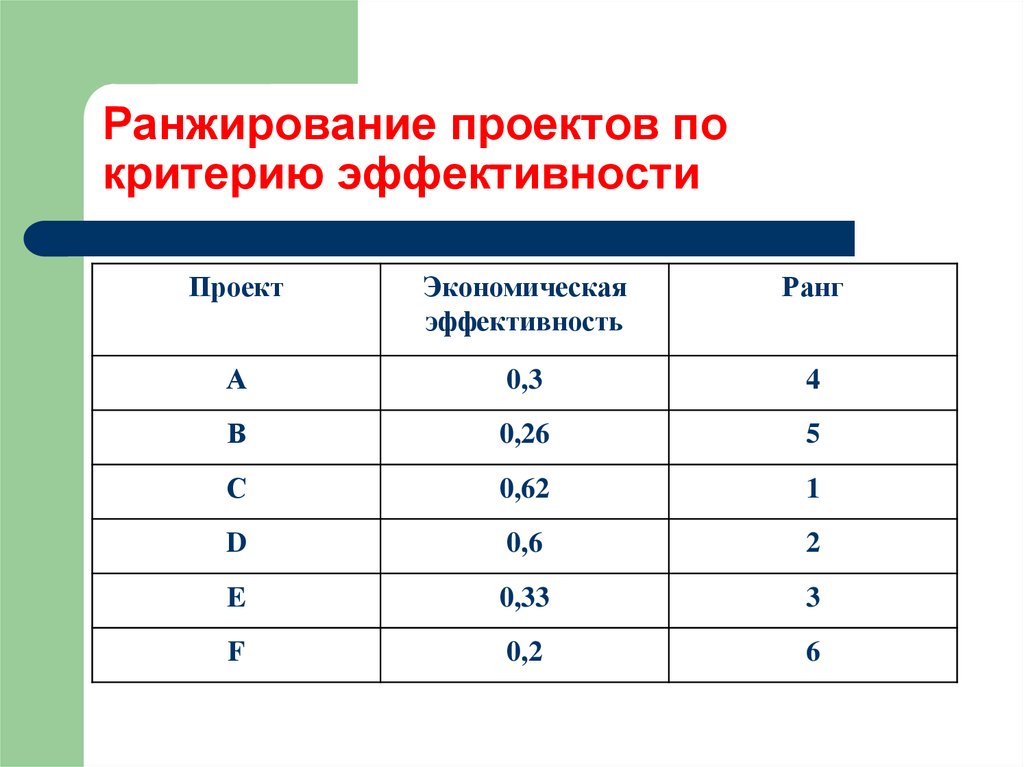 | AA | AA | |
| 10 | 11 | FUJITSU (ИТ -услуги) | Япония | 0 | 0999999999999989999999999999999999999999999999999999999999999999999999999999999999999999999999995S | 99999999999999999999999999999999999999995S.M | AA | A+ |
| 11 | 12 | DXC Technology | United States | 🔒 | 🔒 | 🔒 | 🔒 | |
| 12 | 14 | CGI | Canada | 🔒 | 🔒 | 🔒 | 🔒 | |
| 13 | 10 | Samsung SDS | South Korea | 🔒 | 🔒 | 🔒 | 🔒 | |
| 14 | 13 | Atos | France | 🔒 | 🔒 | 🔒 | 🔒 | |
| 15 | 15 | Tech Mahindra | India | 🔒 | 🔒 | 🔒 | 🔒 | |
| 16 | null | EPAM | United States | 🔒 | 🔒 | 🔒 | 🔒 | |
| 17 | 17 | HPE (IT Services) | United States | 🔒 | 🔒 | 🔒 | 🔒 | |
| 18 | 16 | Xerox | United States | 🔒 | 🔒 | 🔒 | 🔒 | |
| 19 | 19 | NEC (IT Services) | Japan | 🔒 | 🔒 | 🔒 | 🔒 | |
| 20 | 18 | SAIC | United States | 🔒 | 🔒 | 🔒 | 🔒 | |
| 21 | 22 | Sopra Steria | France | 🔒 | 🔒 | 🔒 | 🔒 | |
| 22 | 21 | LTI | India | 🔒 | 🔒 | 🔒 | 🔒 | |
| 23 | 25 | Globant | Argentina | 🔒 | 🔒 | 🔒 | 🔒 | |
| 24 | null | Thoughtworks | United States | 🔒 | 🔒 | 🔒 | 🔒 | |
| 25 | 20 | CTC | Japan | 🔒 | 🔒 | 🔒 | 🔒 |
Идет загрузка. ..
..
Занять место! (комплект 1) | Всемирная Книга
Главная > Все > Наборы книг > Читатель поневоле >
С яркими красочными страницами, организованными в двухстраничные развороты, Rank It! Серия для учащихся 4–6 классов знакомит с шестью различными темами, представляющими большой интерес для юных читателей. В этих научно-популярных книгах информация о динозаврах, бейсболистах и баскетболистах, бойцах смешанных единоборств и водителях серийных автомобилей, а также спецподразделениях легко понятна юным читателям. Полезные диаграммы, диаграммы и глоссарий в каждом томе выделяют самую важную информацию для юных учащихся. Помогите юным читателям в вашей жизни продвинуться вперед — и получайте от этого удовольствие — с помощью World Book’s Ранжируйте! Серия !
Книги из серии BOLT 1 посвящены интересным темам, к которым учащиеся начального уровня чтения с 3-го по 5-й класс будут возвращаться снова и снова.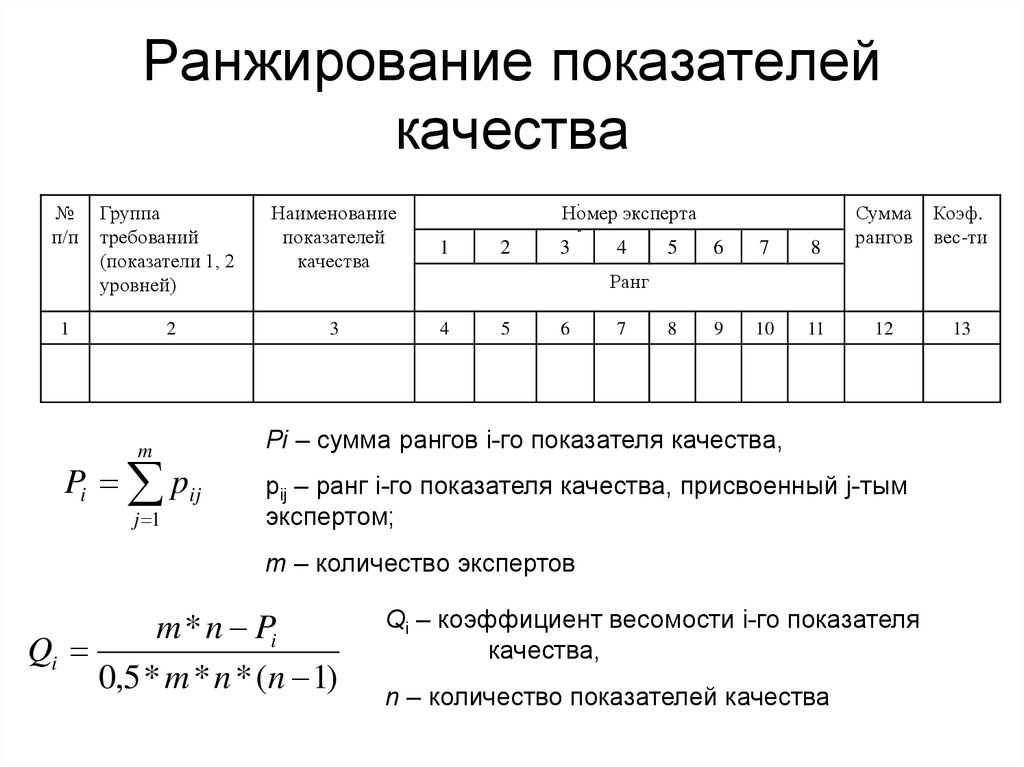 Легко читаемый текст помогает детям понять материал и получить удовольствие от чтения. Наполненные динамическими фотографиями, диаграммами, диаграммами, забавными фактами и инфографикой, привлекающих внимание заголовков BOLT обязательно заставят ваших читателей вернуться за новыми.
Легко читаемый текст помогает детям понять материал и получить удовольствие от чтения. Наполненные динамическими фотографиями, диаграммами, диаграммами, забавными фактами и инфографикой, привлекающих внимание заголовков BOLT обязательно заставят ваших читателей вернуться за новыми.
Книги серии
- Бейсбольные слаггеры
- Великие игроки баскетбола
- Динозавры
- Артисты смешанных единоборств
- Спецназ
- Водители серийных автомобилей
Артикул: 30169
ISBN: 978-0-7166-9779-4
Страниц: 32
Томов: 6
Цена: $150.00
Количество:
- Ключевые особенности
- отзывов
- О БОЛТЕ
- Используя забавный, легкий для понимания текст и инфографику, читатели быстро и легко сравнивают, как складываются темы.
- Соответствует стандартам NCSS.
- От смертоносных динозавров до мощных нападающих, посмотрите, каков рейтинг фаворитов.

BOLT поощряет широкий круг учащихся, в том числе неохотных читателей, предоставляя им книги с привлекательными темами и тщательно подготовленным текстом. Инновационная инфографика и привлекающие внимание фотографии привлекают юных читателей, а доступный, выровненный текст помогает даже самым сложным читателям понять материал и получить удовольствие от чтения. Эта надежная интеграция изображения и текста способствует пониманию и дополняет обучение в классе, помогая каждому учащемуся раскрыть свой учебный потенциал!
Invasive Species Takeover С яркими, красочными страницами, организованными в двухстраничные развороты, серия Invasive Species Takeover для…
Gearhead Garage (набор 1) Серия Gearhead Garage для учащихся с яркими красочными страницами, организованными в виде двухстраничных разворотов.