Содержание
Оптимизированный Robots.txt для Opencart и других CMS на 2019-2020 год
войти в систему
Добро пожаловат!Войдите в свой аккаунт
Ваше имя пользователя
Ваш пароль
Вы забыли свой пароль?
завести аккаунт
Зарегистрироваться
Добро пожаловат!Зарегистрируйтесь для создания учетной записи
Ваш адрес электронной почты
Ваше имя пользователя
Пароль будет выслан Вам по электронной почте.
восстановление пароля
Восстановите свой пароль
Ваш адрес электронной почты
Я заканчиваю доделывать интернет магазин одному из своих заказчиков на платформе opencart3 и перед выкладкой его в интернет и началом его индексирования поисковыми системами решил посмотреть на официальном форуме по Opencart как там дела обстоят с robots.txt к третьей версии, да и вообще почитать что и кто там порекомендует основываясь на своем опыте. Честно скажу, был немного удивлен, потому как там, информация был из серии:
используйте стандартный робот из коробки и все дела!
как вы понимаете этот вариант может устроить если тех, кто вообще не разбирается и у кого есть впереди свободных пару лет на тесты и изучение поведения паучков)
Следующим шагом решил попытать счастье у своих коллег, но был и там опечален, потому как даже те, кто позиционирует себя как веб студия выкладывали один и тот же скопированный у другого robots без каких то либо пояснений и обоснований — что очень опечалило меня и в итоге буду писать статью на свой стандартный robots. txt который себя зарекомендовал на многих сайтах и ни один год уже в работе и пока не знаю с ним бед!
txt который себя зарекомендовал на многих сайтах и ни один год уже в работе и пока не знаю с ним бед!
Итак, представляю Вам идеальный и правильный файл robots.txt для Opencart, WordPress, Bitrix, Joomla, Shop-Script, MODX, NetCat, UMI.CMS, Drupal оптимизированный под СЕО продвижение в Яндексе и Гугле!
Фал Robots.txt
User-agent: *
Disallow: /admin
Disallow: /system
Disallow: /login
Disallow: /forgot-password
Disallow: /index.php?*
Disallow: /*route=*
Disallow: /*?*
Disallow: /*&*User-agent: YandexImages
Disallow: /
Allow: /image/User-agent: Googlebot-Image
Disallow: /
Allow: /image/Sitemap: https://site/sitemap.xls
Данный ROBOTS.TXT работает при условии:
- что у вас включено ЧПУ для всех ссылок
- стоят canonical на всех ненужных для индексации страницах
- есть четкое понимание, что должно быть в индексе, а что нет!
Но что бы объяснить Вам почему мой файл в разы меньше чем те, которые представлены в интернете прошу Вас прочитать весь текст ниже.

User-agent: *
На всех сайтах я постоянно вижу да и что говорить на моем блоге https://www.nibbl.ru/robots.txt висит тоже «детище» какого то очень «высоко квалифицированного» блогера который рекомендовал делать именно такие роботсы на wordpress, но так как это было ну очень давно, а я блогом особо не занимаюсь и успеваю только писать статьи мне некогда заняться его оптимизацией.
Так вот, все рекомендуют делать директиву User-agent: для всех и каждой поисковой системы) Тоесть все инструкции начинаются с того, что сначала идет блок правил:
- User-agent:*
- User-agent: Yandex
- User-agent: Google
- и т.д.
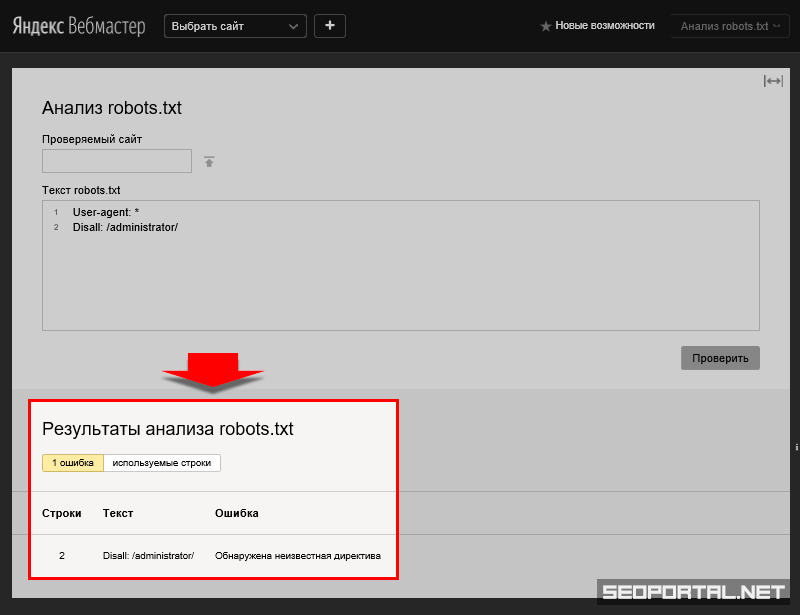
и самое смешное что правила одни и те же для каждого паука! Для наглядности посмотрим на скрин с яндекс помощи:
Комментарий:
- Фиолетовый маркер — в них учитываются подстроки Yandex (регистр значения не имеет) или * — тут четко дается понять, что яндексу все равно, что будет указанно, главное должно быть или-или
- Зеленый маркер — Если обнаружена строка User-agent: Yandex, то строка User-agent: * не учитывается — соответственно это правило действует и наоборот! Если обнаружена User-agent: * то яндекс не будет учитывать User-agent: Yandex
Тоесть тут уже четко дано понять, что для яндекса все равно будет это звездочка или Yandex он будет учитывать первую считанную директиву и с ней работать!
Вывод: Не нужно плодить блоки директив для каждой поисковой системы достаточно все сделать в User-agent: *
Исключение: как вы понимаете бывают и исключения, если вам надо, что бы в одной поисковой системе это индексировалось, а в другой нет — тогда имеет смысл распределять правила для каждого поискового бота! Но это из разряда какого то мистицизма или шизофрении))))
Allow и Disallow :
Директивы которые позволяют нам дать запрет на показ или индексирование разделов или страниц сайта!
Сразу хочу пояснить что эти директивы не означают, что поисковики не будут ходить по этим ссылкам!!! Они только означают, что эти страницы не попадут в индекс! Все поисковые роботы сканируют Ваш сайт вдоль и поперек и знают о нем больше чем вы!
По правилам логики разрешения и запрета сперва должны идти разрешающие правила Allow, а только потом идет Disallow (у запрета всегда больший приоритет) , это можно увидеть на самом сайте яндекса https://yandex. ru/robots.txt
ru/robots.txt
блок строк:
Allow: /local Disallow: /local/api Disallow: /local/create Disallow: /local/profile Disallow: /local/*?event_id
Мы разрешаем индексировать категорию local, НО страницы или подкатегории с именами: api, create, profile и event_id Запрещено!
Для более подробного разбора можно почитать в яндекс помощи (читать)
если почитать инструкцию яндекса, то можно данный код оптимизировать и упростить в несколько строк, для примера в опенкарте есть стандартный страницы:
https://сайт/index.php?route=account/wishlist
https://сайт/index.php?route=checkout/simplecheckout
https://сайт/index.php?route=account/account
https://сайт/index.php?route=account/simpleregister
https://сайт/index.php?route=account/login
https://сайт/index.php?route=product/manufacturer
https://сайт/index.php?route=product/special
https://сайт/index.php?route=information/sitemap
https://сайт/index.php?route=product/compare
https://сайт/index. php?route=account/simpleedit
php?route=account/simpleedit
https://сайт/index.php?route=account/password
https://сайт/index.php?route=account/address
и т.д.
что бы не засорять файл robots перечислениями мы просто пропишем повторяющееся элемент во всех этих строках и закроем его к индексации.
Disallow: /*route=*
таким образом у нам не будут индексироваться данные страниц и все остальные которые имеют в своем url текст route= что бы подкрепить мои слова фактами, вот берем стандартную утилиту яндекс вебмастера, в которой можно проверить на индексацию страницы запрещены она или нет:
Как видите, все страницы запрещены к индексации, тогда как рабочие страницы индексируются нормально!
и все эти правила можно оптимизировать для всех популярных CMS на сегодняшний день:
Виде Бонуса выкладываю стандартные robots.txt для самых популярных CMS России и Мира
HOST
от 20 марта 2018 года на официальном блоге яндекс вебмастеров выложена статья по поводу прекращения поддержик директивы host — статья
где черным по белому сказано:
её можно удалить из robots.
txt или оставить, робот её просто игнорирует
 txt или оставить, робот её просто игнорирует
txt или оставить, робот её просто игнорирует
Sitemap
Файл sitemap.xml — это файл или как его еще называют карта сайта, который содержит все актуальные страницы сайта которые необходимо показать поисковым роботам для улучшения индексации. С помощью sitemap мы сообщаем поисковым системам (Яндексу и Гуглу), какие страницы Вашего сайта нужно индексировать, как часто обновляется информация на сайте, а также индексирование каких страниц наиболее важно.
Это очень важный файл для интернет магазинов у которых количество страниц очень большое и есть проблемы с индексацией — карта сайта эту проблему решает!
noindex
Это конечно не относится к самому файлу robots.txt но имеет прямое отношение к индексации сайта! Это использование метатег <meta name=»robots» content=»noindex, follow»> который четко запрещает к индексации страницы сайта, а также передачу ссылочного веса.
С помощью этого метатега вы можете полностью контролировать и управлять поисковыми роботами на каждой отдельной странице сайта:
- noindex — Не индексировать текст страницы.
- nofollow — Не переходить по ссылкам на странице
- none — Соответствует директивам noindex, nofollow
- noarchive — Не показывать ссылку на сохраненную копию в результатах поиска
- noyaca — Не использовать сформированное автоматически описание
- all — Соответствует директивам index и follow — разрешено индексировать текст и ссылки на странице

Бонус
Стандартный robots.txt для Opencart
Посмотреть стандартный robots.txt для Ocstore
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.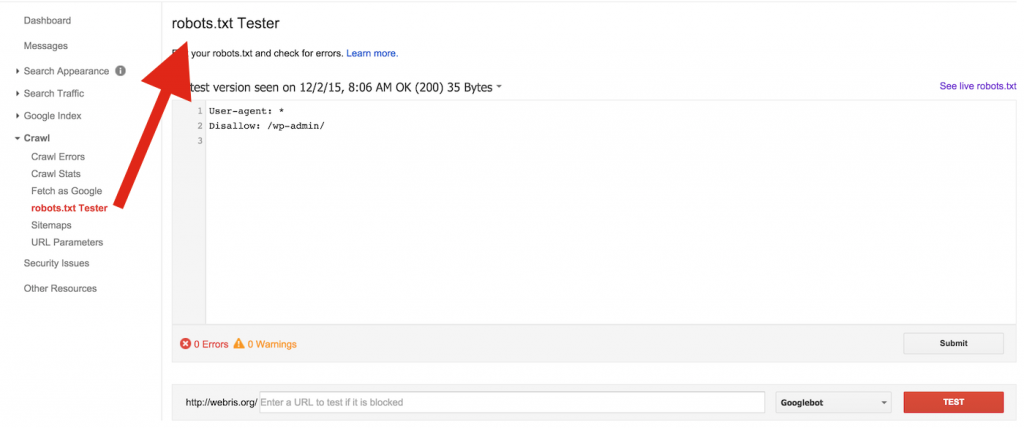 php?route=product/product*&manufacturer_id=
php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Clean-param: tracking
Стандартный robots.txt для WordPress
Посмотреть стандартный robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /*?*
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: */attachment/*
Стандартный robots.
 txt для Bitrix
txt для Bitrix
Скачать стандартный robots.txt для Bitrix
User-agent: *
Disallow: /bitrix/
Disallow: /search/
Allow: /search/map.php
Disallow: /auth/
Disallow: /auth.php
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*index.php$
Стандартный robots.txt для Umi-cms
Скачать стандартный robots.txt для umi-cms
User-Agent: Googlebot
Disallow: /?
Disallow: /dlya_vstavki/
Disallow: /admin
Disallow: /index.php
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /emarket/gateway
Disallow: /go-out.php
Disallow: /cron.php
Disallow: /filemonitor. php
php
Disallow: /search
User-Agent: Yandex
Disallow: /?
Disallow: /dlya_vstavki/
Disallow: /admin
Disallow: /index.php
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /emarket/gateway
Disallow: /go-out.php
Disallow: /cron.php
Disallow: /filemonitor.php
Disallow: /search
User-Agent: *
Disallow: /?
Disallow: /dlya_vstavki/
Disallow: /admin
Disallow: /index.php
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /emarket/gateway
Disallow: /go-out.php
Disallow: /cron.php
Disallow: /filemonitor.php
Disallow: /search
Host: http://ваш сайт
Sitemap: http://ваш сайт
Crawl-delay: 3
Стандартный robots.txt для Webasyst / Shop-Script
Скачать стандартный robots.txt для Webasyst или shop-script
User-agent: *
Crawl-delay: 2
Стандартный robots.txt для Joomla
Скачать стандартный robots.txt для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /modules/
Disallow: /plugins/
Disallow: /tmp/
На этом все! Надеюсь что моя статья была Вам полезна, если у вас есть чем дополнить или покритиковать пишите в комментариях.
Последние
Subscribe
I’ve read and accept the Privacy Policy.
Похожие статьи:
Related
Opencart, Ocstore. Настройка robots.txt и sitemap за 500 руб., исполнитель Алексей (Akinak57) – Kwork
Бесконечные бесплатные правки в рамках технического задания и условий заказа. Платить нужно только за те изменения, которые выходят за рамки первоначального заказа. Подробнее
К сожалению, продавец временно приостановил продажу данного кворка.
Смотрите похожие кворки в разделе Внутренняя оптимизация.
Akinak57
- 4.7
- (58)
К сожалению, продавец временно приостановил продажу данного кворка.
Смотрите похожие кворки в разделе Внутренняя оптимизация.
Об этом кворке
Я профессионально настрою robots.txt и и sitemap.xml с учетом всех современных стандартов, и особенностей OpenCart OcStore 2 и 3 версии. В этот кворк входит:
В этот кворк входит:
- Настройка robots.txt:
- Секции правил для Yandex, Google и др.
- Составление с учетом структуры сайта
- Запрет индексации дублей и системных страниц
- Директивы Allow
- Адаптация с учетом последних стандартов
- Указание карты сайта для поисковых систем
Настройка Sitemap:
- Подключение автогенерируемой карты сайта
- Соответствие sitemap.xml всем рекомендациям Google и Yandex ( с датой c в формате W3C Datetime для XML sitemaps, обновление раз в сутки оповещение (ping) Google и Yandex)
- Проверка на валидность файла в поисковиках и подключение его в Я. Вэбмастер и Google Search Console.
Настройка . htaccess (опционально):
- Настройка кеширования статических файлов
- Настройка 301 редиректов с \’www\’ на \’без www\’, или наоборот
- Настройка 301 редиректов с \’http\’ на \’https\’, или наоборот
- Настройка редиректов для устранения дублей главной страницы
<p>Я профессионально <strong>настрою robots. txt и и sitemap.xml</strong> с учетом всех современных стандартов, и особенностей OpenCart OcStore 2 и 3 версии. В этот кворк входит:</p><ol><li><strong>Настройка robots.txt:</strong></li><li>Секции правил для Yandex, Google и др. </li><li>Составление с учетом структуры сайта</li><li>Запрет индексации дублей и системных страниц</li><li>Директивы Allow</li><li>Адаптация с учетом последних стандартов</li><li>Указание карты сайта для поисковых систем</li></ol><p><strong>Настройка Sitemap:</strong></p><ol><li>Подключение автогенерируемой карты сайта</li><li>Соответствие sitemap.xml всем рекомендациям Google и Yandex ( с датой c в формате W3C Datetime для XML sitemaps, обновление раз в сутки оповещение (ping) Google и Yandex) </li><li>Проверка на валидность файла в поисковиках и подключение его в Я. Вэбмастер и Google Search Console.
txt и и sitemap.xml</strong> с учетом всех современных стандартов, и особенностей OpenCart OcStore 2 и 3 версии. В этот кворк входит:</p><ol><li><strong>Настройка robots.txt:</strong></li><li>Секции правил для Yandex, Google и др. </li><li>Составление с учетом структуры сайта</li><li>Запрет индексации дублей и системных страниц</li><li>Директивы Allow</li><li>Адаптация с учетом последних стандартов</li><li>Указание карты сайта для поисковых систем</li></ol><p><strong>Настройка Sitemap:</strong></p><ol><li>Подключение автогенерируемой карты сайта</li><li>Соответствие sitemap.xml всем рекомендациям Google и Yandex ( с датой c в формате W3C Datetime для XML sitemaps, обновление раз в сутки оповещение (ping) Google и Yandex) </li><li>Проверка на валидность файла в поисковиках и подключение его в Я. Вэбмастер и Google Search Console.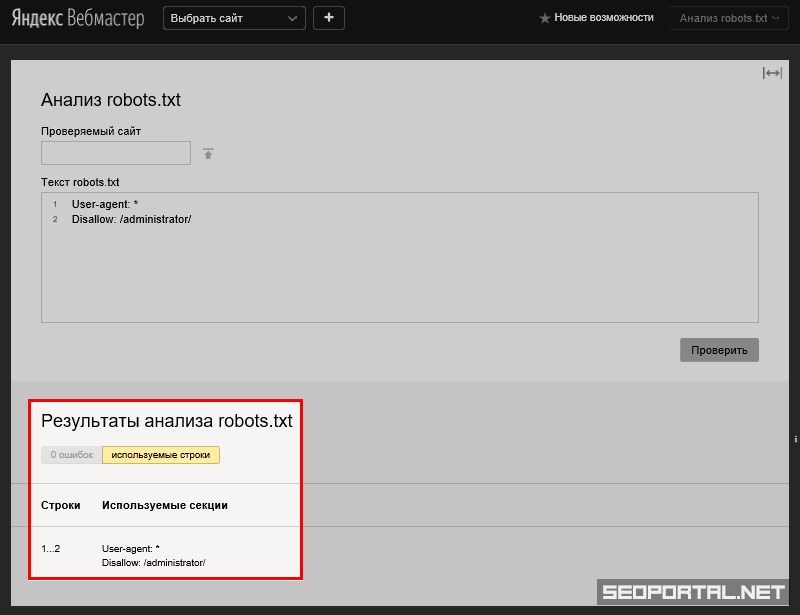 </li></ol><p><strong>Настройка . htacces</strong>s (опционально):</p><ol><li>Настройка кеширования статических файлов</li><li>Настройка 301 редиректов с ‘www’ на ‘без www’, или наоборот</li><li>Настройка 301 редиректов с ‘http’ на ‘https’, или наоборот</li><li>Настройка редиректов для устранения дублей главной страницы</li></ol>
</li></ol><p><strong>Настройка . htacces</strong>s (опционально):</p><ol><li>Настройка кеширования статических файлов</li><li>Настройка 301 редиректов с ‘www’ на ‘без www’, или наоборот</li><li>Настройка 301 редиректов с ‘http’ на ‘https’, или наоборот</li><li>Настройка редиректов для устранения дублей главной страницы</li></ol>
Язык перевода:
Объем услуги в кворке: Robots.txt и sitemap.xml для 1 сайта
Развернуть Свернуть
Гарантия возврата
Средства моментально вернутся на счет,
если что-то пойдет не так. Как это работает?
Расскажите друзьям об этом кворке
Обманчиво важный файл, который нужен всем веб-сайтам
Файл robots.txt помогает основным поисковым системам понять, где им разрешено находиться на вашем веб-сайте.
Но, несмотря на то, что основные поисковые системы поддерживают файл robots. txt, не все они одинаково придерживаются правил.
txt, не все они одинаково придерживаются правил.
Ниже рассмотрим, что такое файл robots.txt и как его можно использовать.
Что такое файл robots.txt?
Каждый день ваш сайт посещают боты, также известные как роботы или пауки. Поисковые системы, такие как Google, Yahoo и Bing, отправляют этих ботов на ваш сайт, чтобы ваш контент можно было просканировать, проиндексировать и отобразить в результатах поиска.
Боты — это хорошо, но в некоторых случаях вы не хотите, чтобы бот бегал по вашему сайту, сканировал и индексировал все. Вот где на помощь приходит файл robots.txt.
Добавляя определенные директивы в файл robots.txt, вы указываете ботам сканировать только те страницы, которые вы хотите сканировать.
Однако важно понимать, что не каждый бот будет соблюдать правила, указанные в файле robots.txt. Google, например, не будет слушать никаких указаний, которые вы поместите в файл о частоте сканирования.
Вам нужен файл robots.
 txt?
txt?
Нет, для веб-сайта файл robots.txt не требуется.
Если бот заходит на ваш сайт, а у него его нет, он просто просканирует ваш сайт и проиндексирует страницы, как обычно.
Файл robot.txt нужен только в том случае, если вы хотите лучше контролировать то, что сканируется.
Некоторые преимущества его наличия включают:
- Помощь в управлении перегрузками сервера
- Предотвратить бесполезное сканирование ботами, которые посещают нежелательные для вас страницы
- Сохранять конфиденциальность определенных папок или субдоменов
Может ли файл robots.txt препятствовать индексированию содержимого?
Нет, вы не можете запретить индексацию содержимого и его отображение в результатах поиска с помощью файла robots.txt.
Не все роботы будут следовать инструкциям одинаково, поэтому некоторые из них могут индексировать содержимое, которое вы запретили сканировать или индексировать.
Кроме того, если содержимое, которое вы пытаетесь запретить показывать в результатах поиска, имеет внешние ссылки на него, это также приведет к его индексации поисковыми системами.
Единственный способ гарантировать, что ваш контент не проиндексирован, — это добавить на страницу метатег noindex. Эта строка кода выглядит так и будет отображаться в html вашей страницы.
Важно отметить, что если вы хотите, чтобы поисковые системы не индексировали страницу, вам необходимо разрешить ее сканирование в файле robots.txt. .
Где находится файл robots.txt?
Файл robots.txt всегда будет находиться в корневом домене веб-сайта. Например, наш собственный файл можно найти по адресу https://www.hubspot.com/robots.txt.
На большинстве веб-сайтов вы должны иметь доступ к реальному файлу, чтобы вы могли редактировать его через FTP или через файловый менеджер в CPanel вашего хоста.
В некоторых платформах CMS вы можете найти файл прямо в вашей административной области. HubSpot, например, упрощает настройку файла robots.txt из вашей учетной записи.
Если вы используете WordPress, доступ к файлу robots. txt можно получить в папке public_html вашего веб-сайта.
txt можно получить в папке public_html вашего веб-сайта.
WordPress включает файл robots.txt по умолчанию с новой установкой, которая будет включать следующее:
Пользовательский агент: *
Запретить: /wp-admin/
Запретить: /wp-includes/
Вышеприведенное указывает всем ботам сканировать все части веб-сайта, кроме любых /wp-admin/ или /wp-includes/.
Но вы можете создать более надежный файл. Давайте покажем вам, как, ниже.
Использование файла robots.txt
Может быть много причин, по которым вы хотите настроить файл robots.txt — от контроля бюджета сканирования до блокировки разделов веб-сайта от сканирования и индексирования. Давайте сейчас рассмотрим несколько причин использования файла robots.txt.
1. Блокировать все поисковые роботы
Блокировать доступ всех поисковых роботов к вашему сайту — это не то, что вы хотели бы делать на активном веб-сайте, но это отличный вариант для разрабатываемого веб-сайта. Если вы заблокируете сканеры, это поможет предотвратить показ ваших страниц в поисковых системах, что хорошо, если ваши страницы еще не готовы для просмотра.
Если вы заблокируете сканеры, это поможет предотвратить показ ваших страниц в поисковых системах, что хорошо, если ваши страницы еще не готовы для просмотра.
2. Запретить сканирование определенных страниц
Один из наиболее распространенных и полезных способов использования файла robots.txt — ограничить доступ роботов поисковых систем к частям вашего веб-сайта. Это может помочь максимизировать краулинговый бюджет и предотвратить попадание нежелательных страниц в результаты поиска.
Важно отметить, что если вы сказали боту не сканировать страницу, это не означает, что она не будет проиндексирована. Если вы не хотите, чтобы страница отображалась в результатах поиска, вам нужно добавить на страницу метатег noindex.
Образец директив файла robots.txt
Файл robots.txt состоит из блоков строк директив. Каждая директива будет начинаться с пользовательского агента, а затем правила для этого пользовательского агента будут размещены под ней.
Когда конкретная поисковая система попадает на ваш веб-сайт, она ищет пользовательский агент, который относится к ним, и читает блок, который ссылается на них.
В файле можно использовать несколько директив. Давайте сломаем их, сейчас.
1. User-Agent
Команда user-agent позволяет направлять определенных ботов или пауков. Например, если вы хотите настроить таргетинг только на Bing или Google, вам следует использовать эту директиву.
Хотя существуют сотни пользовательских агентов, ниже приведены примеры некоторых из наиболее распространенных вариантов пользовательских агентов.
Пользовательский агент: GoogleBot
Пользовательский агент: GoogleBot-Image
Пользовательский агент: Googlebot-Mobile
Пользовательский агент: Googlebots
пользователь-агент: bing: bing: bing: bing: bing: bing: bing: bing: bing: bing: bing: bing: bing: bing: bing-news
.
Агент пользователя: Baiduspider
Агент пользователя: msnbot
Агент пользователя: slurp (Yahoo)
введите их правильно.
Пользовательский агент с подстановочным знаком
Пользовательский агент с подстановочным знаком отмечен звездочкой (*) и позволяет легко применить директиву ко всем существующим пользовательским агентам. Поэтому, если вы хотите, чтобы к каждому боту применялось определенное правило, вы можете использовать этот пользовательский агент.
Агент пользователя: *
Агенты пользователя будут следовать только тем правилам, которые наиболее точно к ним относятся.
2. Disallow
Директива disallow запрещает поисковым системам сканировать или получать доступ к определенным страницам или каталогам на веб-сайте.
Ниже приведены несколько примеров использования директивы disallow.
Блокировать доступ к определенной папке
В этом примере мы говорим всем ботам не сканировать что-либо в каталоге /portfolio на нашем веб-сайте.
User-agent: *
Disallow: /portfolio
Если мы хотим, чтобы Bing не сканировал только этот каталог, мы должны добавить его следующим образом:
User-agent: Bingbot 0003
Запретить: /portfolio
Блокировать PDF или другие типы файлов
Если вы не хотите, чтобы ваш PDF или другие типы файлов сканировались, вам поможет приведенная ниже директива. Мы сообщаем всем ботам, что не хотим, чтобы какие-либо PDF-файлы сканировались. $ в конце сообщает поисковой системе, что это конец URL-адреса.
Итак, если у меня есть файл PDF по адресу mywebsite.com/site/myimportantinfo.pdf , , поисковые системы не получат к нему доступ.
Пользовательский агент: *
DISLAING: * .PDF $
Для файлов PowerPoint вы можете использовать:
пользовательский агент: *
Diship: *.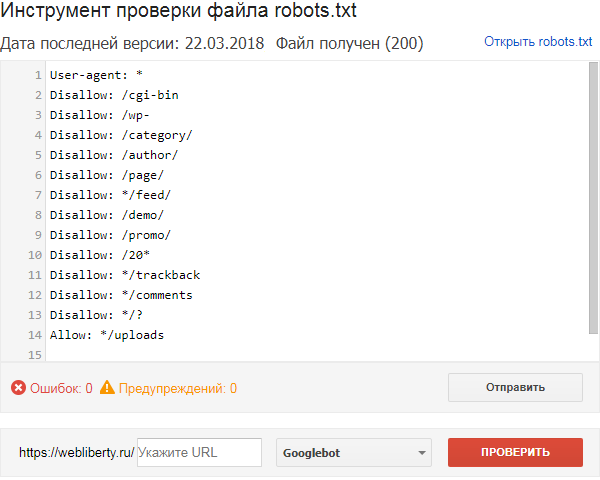 Лучшим вариантом может быть создание папки для вашего PDF или других файлов, а затем запретить сканерам сканировать ее и не индексировать весь каталог с помощью метатега.
Лучшим вариантом может быть создание папки для вашего PDF или других файлов, а затем запретить сканерам сканировать ее и не индексировать весь каталог с помощью метатега.
Блокировать доступ ко всему веб-сайту
Эта директива особенно полезна, если у вас есть веб-сайт для разработки или тестовые папки. Эта директива говорит всем ботам вообще не сканировать ваш сайт. Важно не забыть удалить это, когда вы запускаете свой сайт, иначе у вас возникнут проблемы с индексацией.
User-agent: *
Символ * (звездочка), который вы видите выше, — это то, что мы называем «подстановочным знаком». Когда мы используем звездочку, мы подразумеваем, что приведенные ниже правила должны применяться ко всем пользовательским агентам.
3. Разрешить
Директива allow может помочь вам указать определенные страницы или каталоги, которые вы хотите разрешить ботам и сканировать. Это может быть правилом переопределения параметра запрета, показанного выше.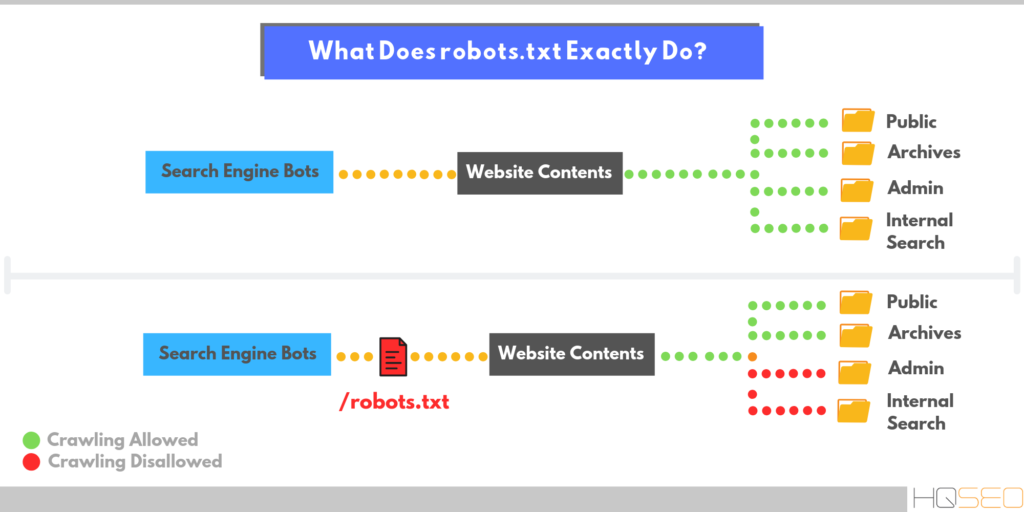
В приведенном ниже примере мы сообщаем роботу Googlebot, что не хотим, чтобы сканировался каталог портфолио, но мы хотим, чтобы был получен доступ и сканировался один конкретный элемент портфолио:
Агент пользователя: Googlebot
Запретить: /portfolio
Разрешить: /portfolio/crawlableportfolio
поисковые роботы для сканирования вашей карты сайта.
Если вы отправляете свои карты сайта непосредственно в инструменты каждой поисковой системы для веб-мастеров, то нет необходимости добавлять их в файл robots.txt.
карта сайта: https://yourwebsite.com/sitemap.xml
5. Задержка сканирования
Задержка сканирования может заставить бота замедлить сканирование вашего веб-сайта, чтобы ваш сервер не перегружался.
Это директива, с которой вы должны быть осторожны. На очень большом веб-сайте это может значительно минимизировать количество URL-адресов, сканируемых каждый день, что было бы контрпродуктивно. Однако это может быть полезно на небольших веб-сайтах, где боты посещают слишком много.
Однако это может быть полезно на небольших веб-сайтах, где боты посещают слишком много.
Примечание. Задержка сканирования равна не поддерживается Google или Baidu . Если вы хотите попросить их сканеры замедлить сканирование вашего веб-сайта, вам нужно будет сделать это с помощью их инструментов .
Что такое регулярные выражения и подстановочные знаки?
Сопоставление с образцом — это более продвинутый способ управления тем, как бот сканирует ваш веб-сайт с использованием символов.
Есть два общих выражения, которые используются как Bing, так и Google. Эти директивы могут быть особенно полезны на веб-сайтах электронной коммерции.
Звездочка: * рассматривается как подстановочный знак и может представлять любую последовательность символов
Знак доллара: $ используется для обозначения конца URL-адреса
Хороший пример использования подстановочного знака * приведен в сценарии где вы хотите запретить поисковым системам сканировать страницы, на которых может быть вопросительный знак. Приведенный ниже код говорит всем ботам игнорировать сканирование любых URL-адресов, в которых есть вопросительный знак.
Приведенный ниже код говорит всем ботам игнорировать сканирование любых URL-адресов, в которых есть вопросительный знак.
Агент пользователя: *
Запретить: /*?
Как создать или отредактировать файл robots.txt
Если на вашем сервере нет файла robots.txt, вы можете легко добавить его, выполнив следующие действия.
- Откройте нужный текстовый редактор, чтобы создать новый документ. Распространенными редакторами, которые могут существовать на вашем компьютере, являются Блокнот, TextEdit или Microsoft Word.
- Добавьте директивы, которые вы хотите включить в документ.
- Сохраните файл с именем «robots.txt»
- Проверьте свой файл, как показано в следующем разделе
- Загрузите файл .txt на свой сервер с помощью FTP или в CPanel. Способ загрузки зависит от типа вашего веб-сайта.
В WordPress вы можете использовать такие плагины, как Yoast, All In One SEO, Rank Math для создания и редактирования вашего файла.
Вы также можете использовать генератор robots.txt , который поможет вам подготовить файл, который поможет свести к минимуму количество ошибок.
Как протестировать файл robots.txt
Прежде чем вы начнете использовать созданный вами код файла robots.txt, вам нужно будет запустить его через тестер, чтобы убедиться, что он действителен. Это поможет предотвратить проблемы с неправильными директивами, которые могли быть добавлены.
Инструмент тестирования robots.txt доступен только в старой версии Google Search Console. Если ваш сайт не подключен к Google Search Console, вам нужно будет сделать это в первую очередь.
Посетите страницу службы поддержки Google и нажмите кнопку «Открыть тестер robots.txt». Выберите свойство, которое вы хотите протестировать, и вы попадете на экран, подобный показанному ниже.
Чтобы протестировать новый код robots.txt, просто удалите то, что сейчас находится в поле, замените его новым кодом и нажмите «Проверить». Если ответ на ваш тест «разрешен», то ваш код действителен, и вы можете пересмотреть свой фактический файл с новым кодом.
Если ответ на ваш тест «разрешен», то ваш код действителен, и вы можете пересмотреть свой фактический файл с новым кодом.
Надеюсь, этот пост заставил вас меньше бояться копаться в вашем файле robots.txt, потому что это один из способов улучшить свой рейтинг и повысить эффективность SEO.
Темы:
Техническое SEO
Не забудьте поделиться этим постом!
Отправленный URL-адрес, заблокированный Robots.txt — исправление ошибок Google Search Console
Последнее обновление 13 сентября 2022 г.
Желтые ошибки в разделе «Покрытие» Google Search Console продолжают появляться!
На этот раз я расскажу, как найти и исправить проблему « Отправленный URL-адрес, заблокированный Robots.txt ».
Почему это ошибка?
Это не просто ошибка, это потенциально может быть ОГРОМНОЙ проблемой SEO, которую нужно исправить немедленно.
Файл robots. txt сообщает Google, как вести себя при сканировании вашего веб-сайта.
txt сообщает Google, как вести себя при сканировании вашего веб-сайта.
Обычно он находится по адресу: domain.com/robots.txt
Обычно вам придется редактировать его через FTP или файловый менеджер через ваш веб-хостинг.
Если Google видит страницу как «заблокированную», это означает, что ему не разрешено ее сканировать, а когда Google не может что-то просканировать, он часто УДАЛИТ ЕГО ИЗ ИНДЕКСА ПОЛНОСТЬЮ .
Теперь это не проблема для страницы фильтра, которую вы не хотите индексировать, но если это ваша основная категория или целевая страница, то у вас большие проблемы.
Основная причина возникновения этой ошибки заключается в том, что у вас есть страница в вашей карте сайта, которая заблокирована, а это означает, что вы сообщаете Google две противоречивые вещи:
- Вот моя карта сайта, Google, пожалуйста, проиндексируйте все эти страницы.
- Вот мой файл robots.txt, пожалуйста, не сканируйте такие страницы.
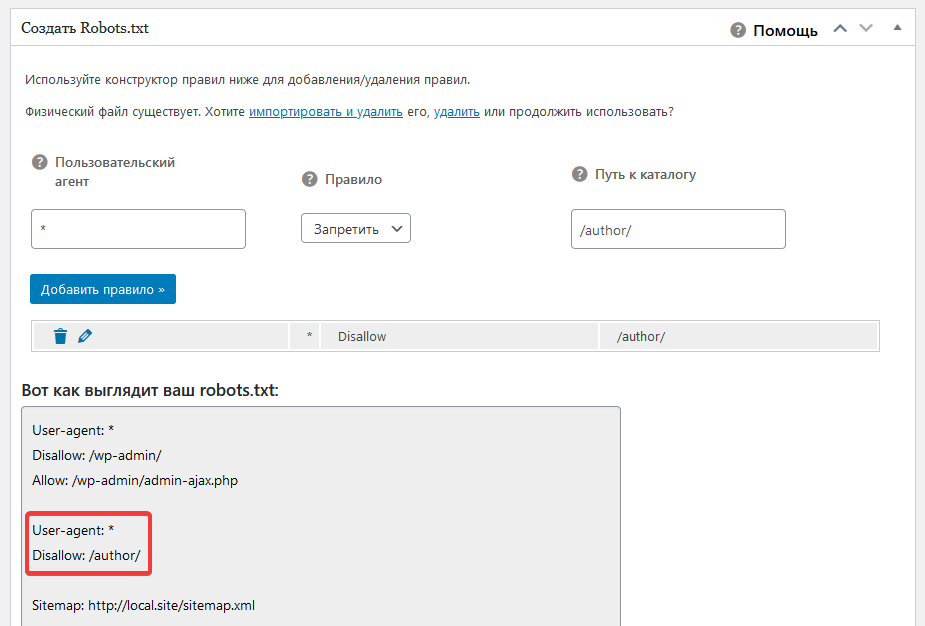
И если у вас есть эта ошибка, это означает, что одна или несколько ваших страниц отображаются в обоих этих файлах.
Как найти и исправить ошибку
Шаг 1 — убедиться, что эти страницы должны быть заблокированы.
Эта ошибка часто может определить, когда кто-то случайно заблокировал что-то, и может помочь вам исправить это, прежде чем это вызовет у вас большие проблемы с SEO.
Если страницы не должны быть заблокированы, то проанализируйте правила вашего файла robots.txt, найдите тот, который блокирует вашу главную страницу/страницы, и перепишите правило, чтобы оно не блокировало страницы (но все же блокировало то, что оно пытался заблокировать в первую очередь).
Шаг 2 — если страницы заблокированы намеренно — удалите их из карты сайта.
Способ удаления страниц из карты сайта различается в разных CMS, но вот несколько примеров:
- WordPress — плагин Yoast обычно автоматически делает это за вас в WordPress, если вы отредактировали настройки «Внешний вид в поиске», чтобы удалить определенные страницы из индекса. Отдельные страницы также можно удалить, следуя этим инструкциям: https://kb.yoast.com/kb/sitemap-shows-excluded-posts-pages/
- Shopify — в Shopify есть фантастическое приложение под названием «Sitemap & Noindex Manager», которое позволяет очень легко удалять URL-адреса из карты сайта (а также добавлять noindex на определенные страницы): https://apps.shopify.com/sitemap -noindex-менеджер
- Opencart — в Opencart сделать не просто, но можно. Я предпочитаю «Расширенный генератор карты сайта» от Geckodev, поскольку он позволяет вручную удалять типы или определенные URL-адреса из карты сайта в Opencart: https://www.opencart.com/index.php?route=marketplace/extension/ info&extension_id=32577
 Отдельные страницы также можно удалить, следуя этим инструкциям: https://kb.yoast.com/kb/sitemap-shows-excluded-posts-pages/
Отдельные страницы также можно удалить, следуя этим инструкциям: https://kb.yoast.com/kb/sitemap-shows-excluded-posts-pages/.
Нужна помощь? Мои аудиты могут помочь
Анализ и исправление ошибок Google Search Console — это небольшая часть моей службы SEO аудита и отчетов о возможностях, которая поможет вам выявить любые технические проблемы, связанные с SEO, на странице, с пользовательским интерфейсом и за пределами сайта, а также потенциальные упущенные возможности. .
.
Свяжитесь со мной по электронной почте для получения дополнительной информации – [email protected]
Насколько полезным был этот пост?
Нажмите на звездочку, чтобы оценить!
Средняя оценка 5 / 5. Количество голосов: 1
Голосов пока нет! Будьте первым, кто оценит этот пост.
Сожалеем, что этот пост не был вам полезен!
Давайте улучшим этот пост!
Расскажите, как мы можем улучшить этот пост?
Быстрые ссылки
- 1 Почему это ошибка?
- 2 Как найти и исправить ошибку
- 3 Нужна помощь? Мои аудиты могут помочь
Мэтт Джексон
Эксперт по поисковой оптимизации электронной коммерции с более чем 10-летним опытом анализа и исправления веб-сайтов онлайн-покупок. Практический опыт работы с Shopify, WordPress, Opencart, Magento и другими CMS.
Нужна помощь в SEO? Для получения дополнительной информации напишите мне по адресу info@matt-jackson.