Содержание
Правильный файл robots.txt для сайта на Opencart в 2022
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Пример;
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Пример правильного файла robots.txt для сайта на Opencart
- User-agent: *
- Disallow: /*route=account/
- Disallow: /*route=affiliate/
- Disallow: /*route=checkout/
- Disallow: /*route=product/search
- Disallow: /index.php?route=product/product*&manufacturer_id=
- Disallow: /admin
- Disallow: /catalog
- Disallow: /system
- Disallow: /*?sort=
- Disallow: /*&sort=
- Disallow: /*?order=
- Disallow: /*&order=
- Disallow: /*?limit=
- Disallow: /*&limit=
- Disallow: /*?filter=
- Disallow: /*&filter=
- Disallow: /*?filter_name=
- Disallow: /*&filter_name=
- Disallow: /*?filter_sub_category=
- Disallow: /*&filter_sub_category=
- Disallow: /*?filter_description=
- Disallow: /*&filter_description=
- Disallow: /*?tracking=
- Disallow: /*&tracking=
- Disallow: *page=*
- Disallow: *search=*
- Disallow: /cart/
- Disallow: /forgot-password/
- Disallow: /login/
- Disallow: /compare-products/
- Disallow: /add-return/
- Disallow: /vouchers/
- Host: https://seopulses.
 ru
ru - Sitemap: https://seopulses.ru/sitemap_index.xml
 ru
ruГде можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
https://ru.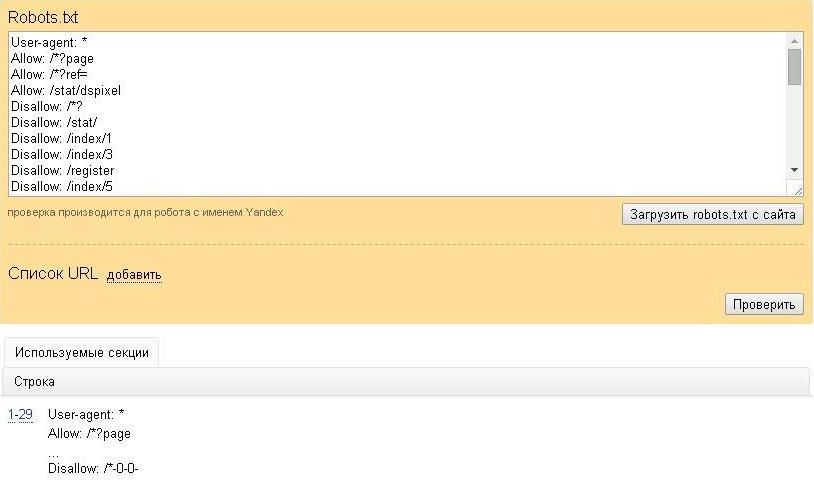 wordpress.org/plugins/pc-robotstxt/
wordpress.org/plugins/pc-robotstxt/
- Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site. ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.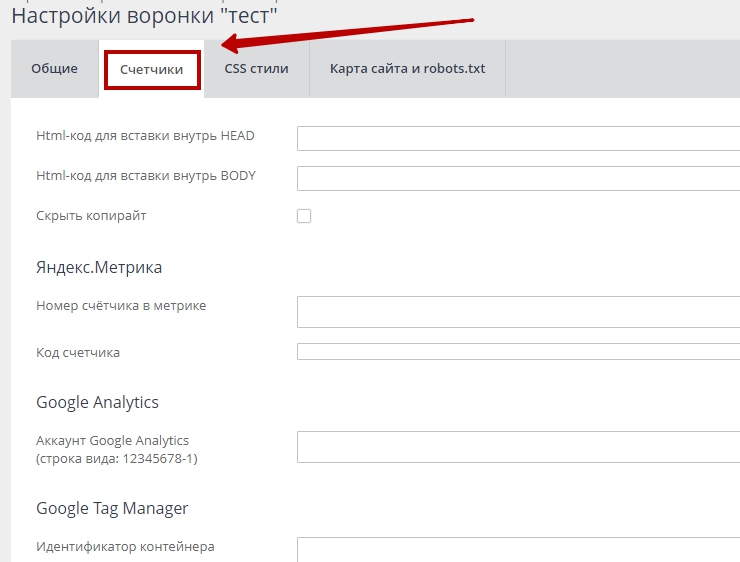
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Идеальный robots.txt для OpenCart 2.3\3.x (ocStore)
Для самых нетерпеливых готовый robots.txt для вашего магазина на Opencart лежит в конце статьи. Не забудьте поменять site.ru на ваш домен!
Зачем нужен robots.txt?
Robots.txt это текстовый файл который содержит инструкции роботам для индексации сайта. Другими словами, мы говорим Google и Яндексу какие страницы мы хотим видеть в поисковой выдаче, а какие нет. Вот так выглядит сайт типографии с «кривым» файлом robots, в выдачу попадают макеты, технические страницы и прочий мусор. Эти некачественные страницы конкурируют с целевыми, сделанными под коммерческие запросы:
Другими словами, мы говорим Google и Яндексу какие страницы мы хотим видеть в поисковой выдаче, а какие нет. Вот так выглядит сайт типографии с «кривым» файлом robots, в выдачу попадают макеты, технические страницы и прочий мусор. Эти некачественные страницы конкурируют с целевыми, сделанными под коммерческие запросы:
Неправильный robots.txt
В случае с Opencart, нам нужно закрыть все страницы относящиеся к личному кабинету, оформлению заказа, регистрации и т.д.
Зачем еще его можно использовать
Для закрытия всего сайта при его разработке и наполнении товарами.
На этом этапе обычно url часто меняются и пересоздаються. Чтобы ваш сайт НЕ индексировался поисковиками, создаем файл следующего содержания:
User-agent: * Disallow: /
Распространённая ошибка — купить красивый домен и поставить на него голый движок с тестовыми товарами(посмотреть как все выглядит). Сайт в таком виде индексируют поисковики и сразу же пессимизируют за не уникальный контент. Обязательно нужно закрывать от индексации!
Обязательно нужно закрывать от индексации!
Для закрытия сайта от ненужных краулеров и spy-сервисов.
Если вы не хотите, чтобы ваш сайт проверяли конкуренты, например, через Ahrefs, Majestic и подобные сервисы, закрывайте им доступ. Еще робот Yahoo любит приходить на сайт по 5 раз в день и грузить сервер, но толку от Yahoo для РФ-магазина никакого.
Как создать файл robots.txt
- В Блокноте или Sublime Text создайте файл с именем robots.txt и скопируйте туда код, который лежит в конце статьи.
- Проверьте файл в Яндекс.Вебмастер и Google Search Console.
- Загрузите файл на хостинг в корневую директорию .
Как проверить, что индексируют поисковики?
Проверить, что проиндексировано Яндексом и Google можно с помощью параметра «site:» — в поисковой строке наберите «site:ваш.cайт» (для обоих поисковиков команда одинаковая). Вручную просмотрите списки страниц и добавьте ненужные в robots.txt. Если количество страниц слишком большое — воспользуйтесь Netpeak Spider или Seo Frog.
Правила написания
Директивы Disallow и Allow
Между директивами не должно быть пустых строк, пустые строки только между блоками User-agent. Порядок любой — можно сначала разрешать, а потом запрещать или наоборот, или вообще вперемешку.
Sitemap и Host
Две директивы Яндекса. Для Host указываем главное зеркало сайта, обратите внимание, что оно указывается без http://, но, если у вас протокол https, то пишем — https://. Для Sitemap — путь к карте сайта, по умолчанию он выглядит вот так:
Sitemap: https://site.ru/index.php?route=feed/google_sitemap
Clean-Param и Crawl-delay
Еще две директивы, придуманные Яндексом, Google их не воспринимает и будет выводить ошибку в Search Console, не обращайте на это внимания.
Clean-Param обязательно используем, если на сайт ведется реклама через Яндекс.Директ, Google Adwords, таргет через соц.сети или реферальные ссылки. Иначе в индексацию будут залетать страницы с «хвостом» из параметров utm-меток и создавать дубли, а это повлечет песcимизацию в Яндексе.
Пример синтаксиса:
Clean-Param: utm_source&utm_medium&utm_campaign
Crawl-delay используют для уменьшения нагрузки на сервер. Для новых магазинов не прописываем.
Что делать если у вас кириллический домен?
Использование кириллицу в robots.txt запрещено. Для того чтобы замаскировать кириллицу под понятные поисковым роботам символы используйте Punycode. Адреса страниц пишите в той же кодировке, что и весь сайт. Я пользуюсь вот этим конвертором (он же пригодится и для составления правильного файла sitemap.xml)
Например:
#Неправильно: User-agent: Yandex Disallow: /регистрация #Правильно: User-agent: Yandex Disallow: /xn--80affnb7bdhj6b9f
Правильный robots.txt для магазина на Opencart
Вместо site.ru подставьте ваш домен. Обратите внимание, что после установки некоторых модулей, могут меняться url страниц. Периодически проверяйте сайт на предмет попадания ненужных страниц в индекс. Сразу исключены из индекса страницы генерируемые модулем Simple.
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Disallow: /*compare-products Disallow: /*search Disallow: /*cart Disallow: /*checkout Disallow: /*login Disallow: /*logout Disallow: /*vouchers Disallow: /*wishlist Disallow: /*my-account Disallow: /*order-history Disallow: /*newsletter Disallow: /*return-add Disallow: /*forgot-password Disallow: /*downloads Disallow: /*returns Disallow: /*transactions Disallow: /*create-account Disallow: /*recurring Disallow: /*address-book Disallow: /*reward-points Disallow: /*affiliate-forgot-password Disallow: /*create-affiliate-account Disallow: /*affiliate-login Disallow: /*affiliates Disallow: /*?filter_tag= Disallow: /*brands Disallow: /*specials Disallow: /*simpleregister Disallow: /*simplecheckout Disallow: *utm= Allow: /catalog/view/javascript/ Allow: /catalog/view/theme/*/ User-agent: Yandex Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.
 php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*compare-products
Disallow: /*search
Disallow: /*cart
Disallow: /*checkout
Disallow: /*login
Disallow: /*logout
Disallow: /*vouchers
Disallow: /*wishlist
Disallow: /*my-account
Disallow: /*order-history
Disallow: /*newsletter
Disallow: /*return-add
Disallow: /*forgot-password
Disallow: /*downloads
Disallow: /*returns
Disallow: /*transactions
Disallow: /*create-account
Disallow: /*recurring
Disallow: /*address-book
Disallow: /*reward-points
Disallow: /*affiliate-forgot-password
Disallow: /*create-affiliate-account
Disallow: /*affiliate-login
Disallow: /*affiliates
Disallow: /*?filter_tag=
Disallow: /*brands
Disallow: /*specials
Disallow: /*simpleregister
Disallow: /*simplecheckout
Disallow: *utm=
Allow: /catalog/view/javascript/
Allow: /catalog/view/theme/*/
Clean-Param: utm_source&utm_medium&utm_campaign site.
php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*compare-products
Disallow: /*search
Disallow: /*cart
Disallow: /*checkout
Disallow: /*login
Disallow: /*logout
Disallow: /*vouchers
Disallow: /*wishlist
Disallow: /*my-account
Disallow: /*order-history
Disallow: /*newsletter
Disallow: /*return-add
Disallow: /*forgot-password
Disallow: /*downloads
Disallow: /*returns
Disallow: /*transactions
Disallow: /*create-account
Disallow: /*recurring
Disallow: /*address-book
Disallow: /*reward-points
Disallow: /*affiliate-forgot-password
Disallow: /*create-affiliate-account
Disallow: /*affiliate-login
Disallow: /*affiliates
Disallow: /*?filter_tag=
Disallow: /*brands
Disallow: /*specials
Disallow: /*simpleregister
Disallow: /*simplecheckout
Disallow: *utm=
Allow: /catalog/view/javascript/
Allow: /catalog/view/theme/*/
Clean-Param: utm_source&utm_medium&utm_campaign site. ru
Host: https://site.ru
Sitemap: https://site.ru/index.php?route=feed/google_sitemap
ru
Host: https://site.ru
Sitemap: https://site.ru/index.php?route=feed/google_sitemap
Оптимизация файла Robots.txt в Opencart Marketplace
Что такое файл Robots.txt?
Robots.txt — это стандартный файл, который веб-сайты используют для инструктирования поисковых роботов или поисковых роботов, таких как Googlebot, когда они посещают ваши веб-сайты или торговые площадки.
Таким образом, вы сообщаете Google, Bing, MSN или другим основным поисковым системам, что они могут и что не могут видеть на ваших веб-сайтах. Что еще более важно, что им разрешено видеть и где им разрешено находиться на ваших веб-сайтах или торговых площадках.
Зачем нужен файл robot.txt?
Если вы не используете файл robot.txt, то многие вещи могут пойти не так с вашей торговой площадкой или веб-сайтом, например —
- Склонен к ошибкам.
- Ваши веб-сайты не будут оптимизированы для сканирования.
- Конфиденциальные данные могут быть просканированы ботами и проиндексированы в результатах поиска, а также могут стать видимыми для искателей.
- Это помогает предотвратить проблемы с дублированием контента, что важно для успеха SEO.
- Это помогает скрыть технические детали вашего сайта, т. е. журналы ошибок, файлы SVN, нежелательные страницы, страницу корзины, страницу входа в систему, страницу оформления заказа и т. д. Поскольку это предотвращено, у вас остаются чистые URL-адреса для индексации поисковые системы.
- Вы можете использовать нестандартные директивы сканирования, чтобы замедлить работу поисковых систем, например, директиву задержки сканирования, которая может замедлить поисковые системы, требующие сканирования.
У каждого сайта есть определенное количество страниц, которое будет сканировать поисковый робот, обычно называемое краулинговым бюджетом. Блокировка разделов вашего сайта от поисковых роботов позволяет вам использовать это выделение для других разделов вашего сайта.


Как создать файл robots.txt?
Во-первых, вам нужно проверить, есть ли на вашем сайте файл robots.txt, вы можете проверить это, перейдя по URL вашего сайта и добавив в конце текст robots.txt – www.example.com/robots.txt. Если у вас есть этот файл, вы его увидите, а если нет, то вы можете легко его создать.
Вы можете создать файл robots.txt , используя множество текстовых редакторов, доступных на рынке. Откройте блокнот, чтобы начать писать файл robots.txt.
После того, как вы создали этот файл с тем, что вы хотите разрешить и запретить, вы должны загрузить его в корневую папку вашего веб-сайта.
Ниже представлен снимок экрана, на котором показано, как выглядит файл Opencart robots.txt.
- Начните писать файл robots.txt, объявив что-то и указав, какой поисковый робот заходит на сайт.
Например –
Агент пользователя: *
Разрешить: /
Это говорит о том, что любые поисковые роботы, заходящие на сайт, могут сканировать все. Если вы хотите заблокировать свой веб-сайт от всех сканеров, просто замените Разрешить: / на Запретить: / в приведенном выше примере.
Если вы хотите заблокировать свой веб-сайт от всех сканеров, просто замените Разрешить: / на Запретить: / в приведенном выше примере.
Некоторые люди указывают определенные пользовательские агенты, такие как Googlebot или другие случайные агенты, на которых люди обычно действительно сосредоточены, и запускают robots.txt с User-agent: Googlebot, а затем они запрещают определенные части своих веб-сайтов.
- Допустим, на вашем веб-сайте есть папка с промежуточным номером , и в ней есть некоторые тестовые данные и другое дублированное содержимое, которое вы не хотите отображать в результатах поиска. Просто напишите —
Агент пользователя: *
Запретить: /staging/
Это всего лишь предложение любому сканеру, заходящему на сайт, не сканировать эту папку. Но если появится какой-либо вредоносный сканер, он может проигнорировать файл robots.txt и, следовательно, не является хорошим механизмом безопасности.
В этом есть свои преимущества и недостатки. Это не способ скрыть ваши конфиденциальные данные, это просто инструкция, сканировать или нет.
- Если вы хотите скрыть данные своего веб-сайта, вы можете использовать метатег . Перейдите на реальную страницу, которую нужно скрыть, и вставьте метатег в заголовок веб-страницы. Это будет что-то вроде –
.
noindex , nofollow »
Этот код будет указывать « Не индексировать этот контент », поэтому сканеры не смогут индексировать эту страницу веб-сайта и обеспечивают хороший механизм сокрытия конфиденциальных данных на вашем веб-сайте или торговых площадках от сканеров.
Таким образом, наилучшим или наиболее эффективным образом используя файл robots. txt, вы сможете создать набор правил для поисковых роботов. Правила будут указывать им, что им разрешено видеть и где им разрешено находиться на ваших веб-сайтах. Для получения дополнительной информации щелкните здесь спецификации robots.txt.
txt, вы сможете создать набор правил для поисковых роботов. Правила будут указывать им, что им разрешено видеть и где им разрешено находиться на ваших веб-сайтах. Для получения дополнительной информации щелкните здесь спецификации robots.txt.
Надеюсь, это было чем-то полезно. Оставайся на месте! для следующей статьи, которая находится на URL-адресах, удобных для поисковых систем .
Это все для оптимизации файла Robots.txt В Opencart Marketplace все еще есть какие-либо проблемы, не стесняйтесь добавлять билеты и сообщать нам свое мнение, чтобы сделать модуль лучше, свяжитесь с нами.
Opencart Marketplace SEO оптимизация оптимизация Оптимизация файла robots.txt robots.txt Оптимизация
| Агент пользователя: * | |
| Запретить: /*route=account/ | |
| Запретить: /*route=affiliate/ | |
| Запретить: /*route=checkout/ | |
| Запретить: /*route=product/search | |
Запретить: /index. php?route=product/product*&manufacturer_id= php?route=product/product*&manufacturer_id= | |
| Запретить: /admin | |
| Запретить: /каталог | |
| Запретить: /скачать | |
| Запретить: /экспорт | |
| Запретить: /система | |
| Запретить: /*?sort= | |
| Запретить: /*&sort= | |
| Запретить: /*?order= | |
| Запретить: /*&order= | |
| Запретить: /*?limit= | |
| Запретить: /*&limit= | |
| Запретить: /*?filter_name= | |
| Запретить: /*&filter_name= | |
| Запретить: /*?filter_sub_category= | |
| Запретить: /*&filter_sub_category= | |
| Запретить: /*?filter_description= | |
| Запретить: /*&filter_description= | |
| Запретить: /*?tracking= | |
| Запретить: /*&tracking= | |
| Запретить: /*?page= | |
| Запретить: /*&page= | |
| Запретить: /список желаний | |
| Запретить: /логин | |
Запретить: /index.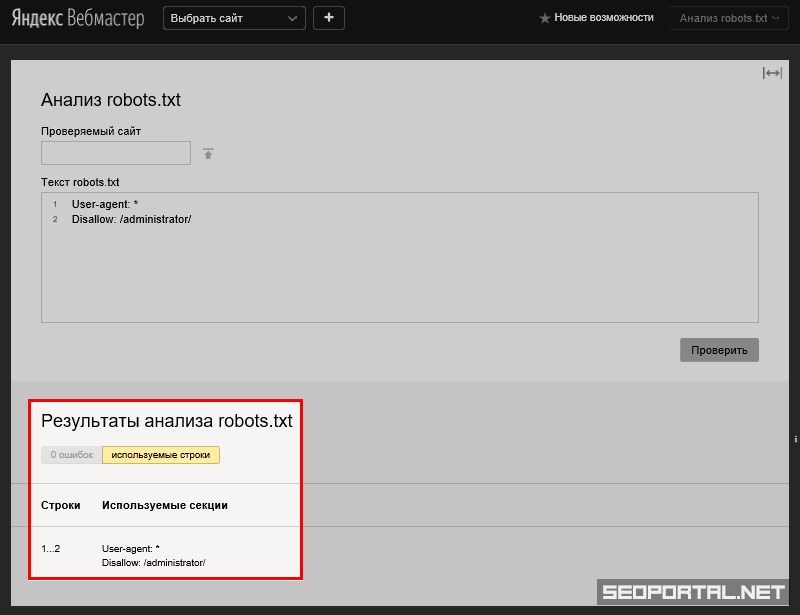 php?route=product/manufacturer php?route=product/manufacturer | |
| Запретить: /index.php?route=product/compare | |
| Запретить: /index.php?route=product/category | |
| Карта сайта: http://royalgraff.com//index.php?route=feed/google_sitemap | |
| User-agent: Яндекс | |
| Запретить: /*route=account/ | |
| Запретить: /*route=affiliate/ | |
| Запретить: /*route=checkout/ | |
| Запретить: /*route=product/search | |
Запретить: /index. php?route=product/product*&manufacturer_id= php?route=product/product*&manufacturer_id= | |
| Запретить: /admin | |
| Запретить: /каталог | |
| Запретить: /скачать | |
| Запретить: /экспорт | |
| Запретить: /система | |
| Запретить: /*?sort= | |
| Запретить: /*&sort= | |
| Запретить: /*?order= | |
| Запретить: /*&order= | |
| Запретить: /*?limit= | |
| Запретить: /*&limit= | |
| Запретить: /*?tracking= | |
| Запретить: /*&tracking= | |
| Запретить: /*route=product/search | |
| Запретить: /*?page= | |
| Запретить: /*&page= | |
| Запретить: /список желаний | |
| Запретить: /логин | |
Запретить: /index.
|