Содержание
Профилирование уже запущенных программ / Хабр
Все мы пользуемся профайлерами. Традиционная схема работы с ними такова, что приходится изначально запускать программу «под профайлером» а затем, после окончания ее работы, анализировать сырой дамп с помощью дополнительных утилит.
А что делать если мы не имея root’а хотим запрофилировать уже работающую программу, которая долго работала «как надо», а сейчас что-то пошло не так. И хотим это сделать быстро. Знакомая ситуация?
Тогда рассмотрим наиболее популярные профайлеры и принципы их работы. А затем профайлер, который решает именно указанную задачу.
Если вы знаете принципиально другой — напишите о нем в комментах. А пока рассмотрим эти 4:
I. gprof
Старый-добрый UNIX профайлер который, по словам Кирка МакКузика, был написан Биллом Джоем для анализа производительности подсистем BSD. Собственно, профайлер «предоставляется» компилятором — он должен расставить контрольные точки в начале и в конце каждой функции. Разница между двумя этими точками и будет временем ее исполнения.
Разница между двумя этими точками и будет временем ее исполнения.
Стоит отметить, что gprof в данном случе точно «знает» и то, сколько раз была вызвана каждая функция. И хотя это может быть необходимым в некоторых ситуациях, это также имеет отрицательный эффект — overhead от замеров может быть сравним или даже больше чем само тело функции. Поэтому, например, для при компиляции C++-кода используют оптимизации приводящие к inline.
Так или иначе, но gprof не работает с уже запущеными программами.
II. Callgrind
Callgrind является частью Valgrind’а — отличного фреймворка для построения средств динамического анализа кода. Valgrind запускает программу «в песочнице», фактически используя виртуализации. Callgrind производит профилирование основываясь на брейкпоинтах на инструкциях типа call и ret. Он значительно замедляет анализируемый код, как правило, от 5 до 20 раз. Таким образом, для анализа на больших данных в runtime он, как правило, не годен.
Однако инструмент очень популярен, и простой формат графа вызовов поддерживается отличными средствами визуализации, например, kcachegrind.
III. OProfile
OProfile is a system-wide profiler for Linux systems, capable of profiling all running code at low overhead.
OProfile является общесистемным профайлером. Т.е. он не нацелен на работу с отдельными процессами, профилируя вместо этого всю систему. OProfile собирает метрики считывая не системный таймер, как gprof или callgrind, а счетчики CPU. Поэтому для запуска демона он требует привелегий.
Однако это незаменимое средство когда Вам необходимо разобраться с работой всей системы, всего сервера сразу. И особенно незаменимое при профилировании области ядра.
Новая версия OProfile 0.9.8
Для версий 0.9.7 и в более ранних профайлер состоял из драйвера ядра и демона для сбора данных. С версии 0.9.8 этот метод заменен на использование Linux Kernel Performance Events (требует ядро 2. 6.31 или более свежее). Релиз 0.9.8 также включает в себя программу ‘operf’, позволяющую непривилегированным пользователям профилировать отдельные процессы.
6.31 или более свежее). Релиз 0.9.8 также включает в себя программу ‘operf’, позволяющую непривилегированным пользователям профилировать отдельные процессы.
IV. Google perftools
Этот профайлер является частью набора Google perftools. Я не нашел на хабре его обзора, поэтому очень кратко опишу.
Набор включает серию библиотек нацеленых на ускорение и анализ C/C++ — приложений. Центральной частью является аллокатор tcmalloc, который помимо ускорения распределения памяти несет средства для анализа классических проблем — memory leaks и heap profile.
Второй частью является libprofiler, который позволяет собирать статистику использования CPU. Важно остановиться на том, как он это делает. Несколько раз в секунду (по-умолчанию 100) программа прерывается на сигнал таймера. В обработчике этого сигнала раскручивается стек и запоминаются все указатели инструкций. По-окончанию сырые данные сбрасываются в файл, по которому уже можно строить статистику и граф вызовов.
Здесь некоторые детали того как это делается
1. По-умолчанию сигналом таймера выбирается таймер ITIMER_PROF, который тикает лишь при использовании программой CPU. Ведь, как-правило, нам не очень интересно где была программа ожидая ввод с клавиатуры или поступления данных по сокету. А если все же интересно, используйте env CPUPROFILE_REALTIME=1
2. Стек вызова раскручивается либо с помощью libunwind, либо вручную (что требует —fno-omit-framepointer, всегда работает на x86).
3. Имена функций впоследствии узнаются с помощью addr2line(1)
4. Как и прочие средства Google perftools, профайлер может быть слинкован явно, а может быть и предзагружен средствами LD_PRELOAD.
Интересен принцип действия — программа прерывается лишь N раз в секунду, где N достаточно мало. Это т.н. сэмплирующий профайлер. Его преимущество в том, что он не оказывает существенного влияния на анализируемую программу, сколько бы мелких функций там не вызывалось. Ввиду особенностей работы, он, однако, не позволяют ответить на вопрос «сколько раз вызывалась данная функция».
Ввиду особенностей работы, он, однако, не позволяют ответить на вопрос «сколько раз вызывалась данная функция».
В случае с google profiler есть еще несколько неприятностей:
- этот профайлер также не предназначен для работы с уже работающими программами
- последние версии не работают с fork(2), порой затрудняя его использование в демонах
Как и обещал, теперь про другой профайлер, который написан именно для решения обозначенной выше проблемы — легкое профилирование уже запущенных процессов.
Он собирает стек вызовов и выводит наиболее «горячие» части в консоль по нажатию ENTER. Также он умеет сохранять граф вызова в упомянутом ранее формате callgrind. Работает быстро, и как любой другой сэмплирующий профайлер не зависит от сложности вызовов в профилируемой программе.
Некоторые детали работы
В основном, crxprof работает также как perftools, но использует внешнее профилирование через ptrace(2). Подобно perftools он использует libunwind для раскрутки стека, а вместо тяжелой работы по преобразованию в имена функций, вместо addr2line(1) используется libbfd.
Подобно perftools он использует libunwind для раскрутки стека, а вместо тяжелой работы по преобразованию в имена функций, вместо addr2line(1) используется libbfd.
Несколько раз в секунду программа останавливается (SIGSTOP) и с помощью libunwind «снимается» стек вызова. Загрузив при старте crxprof карту функций профилируемой программы и связанных с ней библиотек, мы можем быстро найти какой функции пренадлежит каждый отделый IP (instruction pointer).
Параллельно выстраивается граф вызова, полагая что есть некая центральная функция — точка входа. Обычно это __libc_start_main из библиотеки libc.
Исходный код доступен на github. Т.к. утилита создавалась для меня и моих коллег, я вполне допускаю что она может не соответствовать Вашему use-case’у. Так или иначе, спрашивайте.
Соберем crxprof и посмотрим на пример его использования.
Сборка
Что необходимо: Linux (2.6+), autoconf+automake, binutils-dev (включает libbfd), libunwind-dev (у меня он называется libunwind8-dev). C для завершения. Crxprof также выведет профайл и по выходу программы.
C для завершения. Crxprof также выведет профайл и по выходу программы.
crxprof: ptrace(PTRACE_ATTACH) failed: Operation not permitted
Если вы видите эту ошибку, значит ptrace на вашей системе «залимитирован». (Ubuntu ?)
Подробней можно прочитать здесь
Если кратко, то либо пускайте с sudo, либо (лучше) выполните в консоли:
$ echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
Как все unix-утилиты, crxprof выводит usage при вызове с ключом —help. Подробную информацию см. в man crxprof.
crxprof —help
Usage: crxprof [options] pid Options are: -t|--threshold N: visualize nodes that takes at least N% of time (default: 5.0) -d|--dump FILE: save callgrind dump to given FILE -f|--freq FREQ: set profile frequency to FREQ Hz (default: 100) -m|--max-depth N: show at most N levels while visualizing (default: no limit) -r|--realtime: use realtime profile instead of CPU -h|--help: show this help --full-stack: print full stack while visualizing --print-symbols: just print funcs and addrs (and quit)
Реальный пример
Для того чтобы привести реальный, но не сложный пример я использую этот код на C. C pressed
C pressed
По выведенной на консоль статистике видно что:
- main() вызывает heavy_fn() (и это самый «тяжелый» путь)
- heavy_fn() вызывает fn()
- main() также вызывает fn() непосредственно
- heavy_fn() занимает половину времени CPU
- fn() занимает оставшееся время CPU
- main() сама по себе не потребляет ничего
Визуализация делается по схеме «наибольшие поддеревья — первыми». Таким образом, даже для больших реальных программ можно использовать простую визуализацию в консоли, что должно быть удобно на серверах.
Для визуализации сложных графов вызова удобно использовать KCachegrind:
$ kcachegrind /tmp/test.calls
Картинка, которая получилась у меня, представлена справа.
Вместо заключения, напомню что профайлером пока пользуются лишь несколько моих коллег и я сам.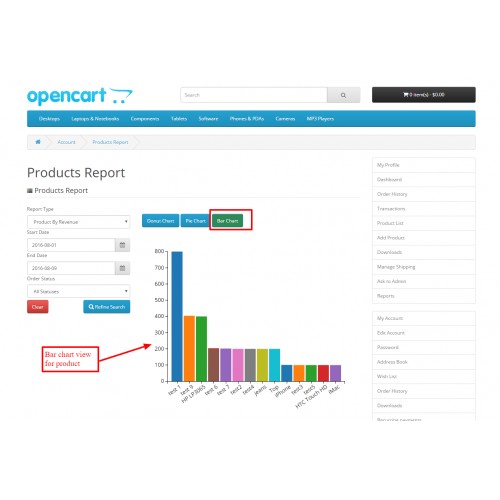 Надеюсь, он будет также полезен и Вам.
Надеюсь, он будет также полезен и Вам.
Opencart, Ocstore. Скорость загрузки за 7 000 руб., исполнитель Игорь (codee) – Kwork
Бесконечные бесплатные правки в рамках технического задания и условий заказа. Платить нужно только за те изменения, которые выходят за рамки первоначального заказа. Подробнее
codee
- 5.0
- (2512)
Выбор Kwork
Выберите вариант кворка
Эконом
7 000 ₽
Стандарт
11 000 ₽
Бизнес
17 000 ₽
ЭкономСтандартБизнес
Эконом
Стандарт
Бизнес
Краткое описание
Начальная оптимизация
Базовая оптимизация
Комплексная оптимизация
Оптимизация html
Оптимизация CSS, JS
Настройка кеширования
Сокращение запросов
Графика
Сжатие CSS, JS
База данных
Количество правок
Не ограничено
Не ограничено
Не ограничено
Срок выполнения
7 дней
7 дней
7 дней
Об этом кворке
Opencart, Ocstore 1. 5 — 4.0
5 — 4.0
- Бесплатная консультация
Описание:
Проверить оптимизацию скорости загрузки сайта на Opencart, Ocstore по шагам:
- перейти по ссылке: https://developers.google.com/speed/pagespeed/insights/?hl=ru
- ввести URL сайта Вводите адрес Вашего магазина
- если показатели ниже 90 (пк), 65 (моб) — необходима оптимизация сайта.
Информация:
Отчет предоставляется в формате до/после со списком проведенных работ.
Проверка сайта на Opencart, Ocstore осуществляется по главной странице сайта, вывод сайта в конкретные показатели (зоны) — не заявляется.
Что входит в услугу:
1. Эконом. Начальная оптимизация:
- Подключение динамического сжатия HTML
- Минимизация JS
- Минимизация CSS
2. Стандарт. Базовая оптимизация:
- + Настройка GZIP сжатия
- + Настройка кеширования статических файлов
- + Оптимизация графических элементов сайта (логотипы, иконки)
- + Подключение динамического сжатия CSS, JS
- + Минимизация кол-во запросов к серверу
3. Бизнес. Комплексная оптимизация:
Бизнес. Комплексная оптимизация:
- + Оптимизация базы данных *
* включает:
- Индексирование таблиц БД
- Профилирование SQL-запросов
- Поиск медленных SQL-запросов
- Минимизация SQL-запросов БД (страница категории, страница товара)
<p><strong>Opencart, Ocstore 1.5 — 4.0</strong></p><ol><li><strong>Бесплатная консультация</strong></li></ol><p><strong>Описание:</strong></p><p>Проверить оптимизацию скорости загрузки сайта на Opencart, Ocstore по шагам:</p><ol><li>перейти по ссылке: https://developers.google.com/speed/pagespeed/insights/?hl=ru</li><li>ввести URL сайта Вводите адрес Вашего магазина</li><li>если показатели ниже 90 (пк), 65 (моб) — необходима оптимизация сайта.</li></ol><p><strong>Информация:</strong></p><p>Отчет предоставляется в формате до/после со списком проведенных работ. </p><p>Проверка сайта на Opencart, Ocstore осуществляется по главной странице сайта, вывод сайта в конкретные показатели (зоны) — не заявляется.</p><p><strong>Что входит в услугу:</strong></p><p><strong>1. </strong><strong>Эконом</strong>. Начальная оптимизация:</p><ol><li>Подключение динамического сжатия HTML</li><li>Минимизация JS</li><li>Минимизация CSS</li></ol><p><strong>2. Стандарт. </strong> Базовая оптимизация:</p><ol><li>+ Настройка GZIP сжатия</li><li>+ Настройка кеширования статических файлов</li><li>+ Оптимизация графических элементов сайта (логотипы, иконки)</li><li>+ Подключение динамического сжатия CSS, JS</li><li>+ Минимизация кол-во запросов к серверу</li></ol><p><strong>3. Бизнес. </strong> Комплексная оптимизация:</p><ol><li>+ Оптимизация базы данных *</li></ol><p>* включает:</p><ol><li>Индексирование таблиц БД</li><li>Профилирование SQL-запросов</li><li>Поиск медленных SQL-запросов</li><li>Минимизация SQL-запросов БД (страница категории, страница товара)</li></ol>
</p><p>Проверка сайта на Opencart, Ocstore осуществляется по главной странице сайта, вывод сайта в конкретные показатели (зоны) — не заявляется.</p><p><strong>Что входит в услугу:</strong></p><p><strong>1. </strong><strong>Эконом</strong>. Начальная оптимизация:</p><ol><li>Подключение динамического сжатия HTML</li><li>Минимизация JS</li><li>Минимизация CSS</li></ol><p><strong>2. Стандарт. </strong> Базовая оптимизация:</p><ol><li>+ Настройка GZIP сжатия</li><li>+ Настройка кеширования статических файлов</li><li>+ Оптимизация графических элементов сайта (логотипы, иконки)</li><li>+ Подключение динамического сжатия CSS, JS</li><li>+ Минимизация кол-во запросов к серверу</li></ol><p><strong>3. Бизнес. </strong> Комплексная оптимизация:</p><ol><li>+ Оптимизация базы данных *</li></ol><p>* включает:</p><ol><li>Индексирование таблиц БД</li><li>Профилирование SQL-запросов</li><li>Поиск медленных SQL-запросов</li><li>Минимизация SQL-запросов БД (страница категории, страница товара)</li></ol>
CMS: Opencart
Язык разработки: PHP
Фреймворк PHP: Без фреймворка
Интерфейс на JavaScript: Нет
Используется CSS: Да
Фреймворк CSS: Bootstrap, Semantic-UI, Foundation, Materialize, Material UI, Pure, Skeleton, UIKit
База данных: Предусмотрена
Тип БД: MySQL
Язык перевода:
Развернуть Свернуть
Гарантия возврата
Средства моментально вернутся на счет,
если что-то пойдет не так. Как это работает?
Как это работает?
Расскажите друзьям об этом кворке
Recurring — OpenCart Documentation
Повторяющиеся заказы — это платежи, которые вы, как администратор, устанавливаете для клиентов, которые должны выставляться на регулярной основе.
Они настраиваются из Каталог > Повторяющиеся профили > Добавить повторяющийся профиль .
Чтобы получить доступ к разделу Повторяющиеся заказы , нажмите Продажи , как показано на изображении ниже:
Этот раздел позволяет фильтровать повторяющиеся платежи, которые вы установили для повторяющихся профилей. Для получения дополнительной информации о профилях — нажмите здесь.
Идентификатор заказа : идентификатор заказа, связанного с регулярным платежом.
Ссылка на платеж : идентификатор повторяющегося профиля в PayPal Express (по умолчанию).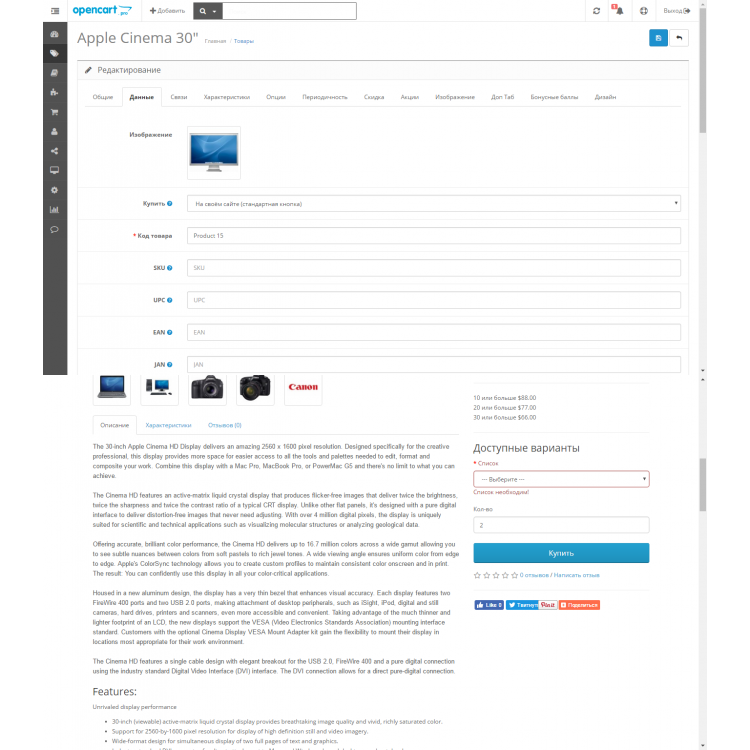
Клиент : имя вашего клиента в OpenCart.
Статус : статус платежа в PayPal.
Электронная почта
Страна
AfghanistanAlbaniaAlgeriaAmerican SamoaAndorraAngolaAnguillaAntigua & BarbudaArgentinaArmeniaArubaAustraliaAustriaAzerbaijanAzoresBahamasBahrainBangladeshBarbadosBelarusBelgiumBelizeBeninBermudaBhutanBoliviaBonaireBosnia & HerzegovinaBotswanaBrazilBritish Indian Ocean TerBruneiBulgariaBurkina FasoBurundiCambodiaCameroonCanadaCanary IslandsCape VerdeCayman IslandsCentral African RepublicChadChannel IslandsChileChinaChristmas IslandCocos IslandColombiaComorosCongoCongo Democratic RepCook IslandsCosta RicaCote D’IvoireCroatiaCubaCuracaoCyprusCzech RepublicDenmarkDjiboutiDominicaDominican RepublicEast TimorEcuadorEgyptEl SalvadorEquatorial GuineaEritreaEstoniaEthiopiaFalkland IslandsFaroe IslandsFijiFinlandFranceFrench GuianaFrench PolynesiaFrench Southern TerGabonGambiaGeorgiaGermanyGhanaGibraltarGreat BritainGreeceGreenlandGrenadaGuadeloupeGuamGuatemalaGuernseyGuineaGuinea-BissauGuyanaHaitiHondurasHong KongHungaryIcelandIndiaIndonesiaIranIraqIrelandIsle of ManIsraelItalyJamaicaJapanJerse yJordanKazakhstanKenyaKiribatiKorea NorthKorea SouthKuwaitKyrgyzstanLaosLatviaLebanonLesothoLiberiaLibyaLiechtensteinLithuaniaLuxembourgMacauMacedoniaMadagascarMalawiMalaysiaMaldivesMaliMaltaMarshall IslandsMartiniqueMauritaniaMauritiusMayotteMexicoMidway IslandsMoldovaMonacoMongoliaMontenegroMontserratMoroccoMozambiqueMyanmarNamibiaNauruNepalNetherland AntillesNetherlandsNevisNew CaledoniaNew ZealandNicaraguaNigerNigeriaNiueNorfolk IslandNorwayOmanPakistanPalau IslandPalestinePanamaPapua New GuineaParaguayPeruPhilippinesPitcairn IslandPolandPortugalPuerto RicoQatarReunionRomaniaRussiaRwandaSaipanSamoaSamoa AmericanSan MarinoSao Tome & PrincipeSaudi ArabiaSenegalSerbiaSerbia & MontenegroSeychellesSierra LeoneSingaporeSlovakiaSloveniaSolomon IslandsSomaliaSouth AfricaSouth SudanSpainSri LankaSt BarthelemySt EustatiusSt HelenaSt Kitts-NevisSt LuciaSt MaartenSt Pierre & MiquelonSt Vincent & GrenadinesSudanSurinameSwazilandSwedenSwitzerlandSyriaTahitiTaiwanTajikistanTanzaniaThailandTogoTok elauТонгаТринидад и ТобагоТунисТурцияТуркменистанТуркс и КайкосТувалуУгандаУкраинаОбъединенные Арабские ЭмиратыВеликобританияСоединенные Штаты АмерикиУругвайУзбекистанВануатуВатиканВенесуэлаВьетнамВиргинские острова (Британия)Виргинские острова (США)Остров УэйкУоллис и ФутанаЙеменЗамбияЗимбабве
Тип
Агентство
Розничный продавец (продажи через Интернет)
Независимый разработчик
Другое
Дополнительные подписки
Избранные сторонние рекламные акции
Повторяющийся профиль Opencart Marketplace (Руководство пользователя)
Повторяющийся профиль Opencart Marketplace — это надстройка Marketplace для Opencart. Это позволяет продавцам настраивать повторяющиеся профили для своих клиентов. Продавцы могут использовать повторяющийся профиль для продуктов, которые требуют регулярных платежей. Повторяющиеся профили полезны для продуктов типа подписки и членства. Его также можно использовать для настройки схем оплаты в рассрочку. Регулярные платежи доступны ежедневно, еженедельно, ежемесячно, раз в полгода или ежегодно. Продавец может создать повторяющийся профиль для своих продуктов из внешнего интерфейса.
Это позволяет продавцам настраивать повторяющиеся профили для своих клиентов. Продавцы могут использовать повторяющийся профиль для продуктов, которые требуют регулярных платежей. Повторяющиеся профили полезны для продуктов типа подписки и членства. Его также можно использовать для настройки схем оплаты в рассрочку. Регулярные платежи доступны ежедневно, еженедельно, ежемесячно, раз в полгода или ежегодно. Продавец может создать повторяющийся профиль для своих продуктов из внешнего интерфейса.
Обратите внимание: – Поскольку это надстройка торговой площадки. У вас должно быть расширение Opencart Marketplace, чтобы повторяющийся профиль Marketplace работал.
Примечание:
1. Этот модуль поддерживает все шаблоны и темы, включая тему журнала.
2. Повторяющийся профиль Opencart Marketplace поддерживает функцию мультимагазина Opencart по умолчанию.
Ищете опытную компанию
Opencart? Подробнее
Ознакомьтесь с кратким обзором подключаемого модуля в видео, упомянутом ниже –
qo_VAPHMUt8
Особенности
- Очень простая установка и настройка
- Продавцы могут использовать повторяющийся профиль других продавцов и администратора
- Одному продукту можно назначить несколько повторяющихся профилей
- Также доступен пробный профиль
- Администратор может выбрать повторяющуюся видимость профиля для продавцов
- Уведомлять продавца, когда другой продавец редактирует свой повторяющийся профиль
- Уведомлять администратора, когда продавец добавляет/редактирует повторяющийся профиль
- Просмотр повторяющихся профилей других продавцов и администратора
- Интервал регулярных платежей – ежедневно, еженедельно, ежемесячно, раз в полгода или ежегодно
- Пользователь может просматривать сведения о доступных повторяющихся профилях
- Поддерживает перевод на несколько языков
Установка
Установка этого модуля очень проста. Во-первых, вам нужно распаковать загруженный zip-файл. После этого откройте правильную папку версии Opencart. Согласно версии Opencart, установленной в вашей системе. Затем загрузите admin и каталог папок в корневой каталог Opencart.
Во-первых, вам нужно распаковать загруженный zip-файл. После этого откройте правильную папку версии Opencart. Согласно версии Opencart, установленной в вашей системе. Затем загрузите admin и каталог папок в корневой каталог Opencart.
Теперь войдите в свою административную панель и перейдите через Extensions->Extension Installer . Нажмите кнопку Загрузить и просмотрите файл XML , этот файл находится в папке ocmod . Пожалуйста, выберите правильную папку ocmod. Согласно вашей версии Opencart, установленной в вашей системе.
Щелкните Продолжить после загрузки XML-файла.
После загрузки XML-файла перейдите к Расширения->Модификации->Список модификаций . Теперь нажмите кнопку Refresh , как показано на снимке экрана ниже. После того, как вы обновили кеш модификаций.
После этого перейдите в Система->Пользователи->Группы пользователей .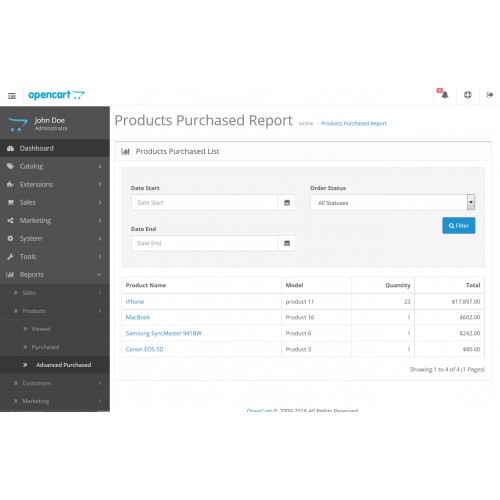 Затем отредактируйте « Администратор ». Нажмите «Выбрать все» для разрешения доступа и разрешения на изменение и «Сохранить» .
Затем отредактируйте « Администратор ». Нажмите «Выбрать все» для разрешения доступа и разрешения на изменение и «Сохранить» .
Теперь перейдите по Расширения->Модули->Список модулей . Найдите в списке Marketplace Recurring . Нажмите кнопку Установить , как показано на снимке экрана ниже.
Конфигурация модуля
Чтобы выполнить настройку модуля, войдите в административную панель. Перейдите через Extensions->Modules->Marketplace Recurring . Нажмите кнопку Edit , как показано на скриншоте.
После нажатия кнопки «Изменить» ниже откроется страница. Отсюда администратор может выполнить следующую настройку повторяющегося профиля Opencart Marketplace.
Статус – Установить статус этого модуля как Включен или Выключен .
Видимость настраиваемого профиля – Выберите видимость повторяющихся профилей.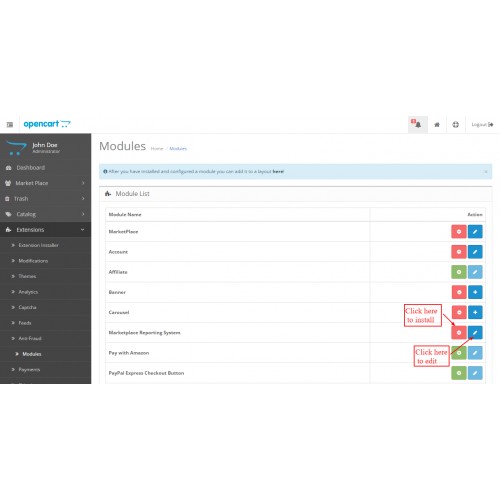
- Один продавец — Продавец может просматривать только свои повторяющиеся профили.
- Все продавцы — Продавец может просматривать повторяющиеся профили всех продавцов.
- Один продавец со значением по умолчанию — Продавец может просматривать повторяющиеся профили администратора и свои собственные.
- Все — Используйте эту опцию, чтобы разрешить всем продавцам просматривать все повторяющиеся профили торговой площадки.
Продавец может редактировать профиль — Выберите Admin , чтобы позволить продавцам редактировать повторяющиеся профили администратора. Кроме того, выберите Опция All Seller , позволяющая продавцу редактировать повторяющиеся профили других продавцов.
Почта администратору при добавлении нового повторяющегося профиля — Выберите шаблон почты для администратора. Всякий раз, когда продавец создает любой новый повторяющийся профиль.
Письмо администратору и продавцу при редактировании повторяющегося профиля — Выберите шаблон письма для администратора и продавца. Когда продавец редактирует повторяющийся профиль другого продавца или администратора.
После настройки повторяющегося профиля Opencart Marketplace нажмите кнопку Сохранить кнопку, чтобы применить изменения.
Настройка модуля Marketplace
Администратору также необходимо настроить модуль Marketplace. Пожалуйста, перейдите через Extensions->Modules->Marketplace . Нажмите кнопку Редактировать . Теперь щелкните вкладку Product , как показано ниже:
В разделе Allowed Product Tab выберите Recurring и затем щелкните Save .
Затем перейдите на вкладку Конфигурация модуля каталога . В разделе Меню разрешенных учетных записей выберите параметр Повторяющиеся профили .
Управление администратором
Администратор может управлять повторяющимися профилями, переходя через Каталог->Повторяющиеся профили . Отсюда администратор может просматривать все повторяющиеся профили на рынке.
Добавить — нажмите кнопку «Добавить», чтобы создать новый повторяющийся профиль.
Редактировать — Нажмите кнопку «Редактировать», чтобы обновить существующий повторяющийся профиль.
Удалить — для удаления повторяющегося профиля. Сначала выберите повторяющийся профиль, а затем нажмите кнопку «Удалить».
Добавить повторяющийся профиль
После того, как администратор нажмет кнопку «Добавить», появятся следующие параметры для добавления повторяющегося профиля:
Имя — Введите имя этого повторяющегося профиля. Это будет название подписки или тарифного плана.
Цена – Установите стоимость этого повторяющегося профиля. Это будет цена подписки или тарифного плана.
Это будет цена подписки или тарифного плана.
Продолжительность — Введите количество раз, которое пользователь будет совершать платежи. Установите его на 0 (ноль) для неограниченного использования. Если безлимитный, план платежей будет продолжаться до тех пор, пока не будет отменен администратором или пользователем.
Цикл — Введите платежный цикл для повторяющегося профиля.
Частота – Выберите, когда совершать платежи – День , Неделя , Месяц , Полумесяц , Год .
Статус – Выберите Включено , чтобы использовать этот повторяющийся профиль, в противном случае выберите Отключено .
Пробный профиль
Администратор также может создать пробный профиль для повторяющегося профиля. Если пробный статус включен, администратор должен предоставить следующие данные:
Цена — Установите стоимость использования пробного профиля.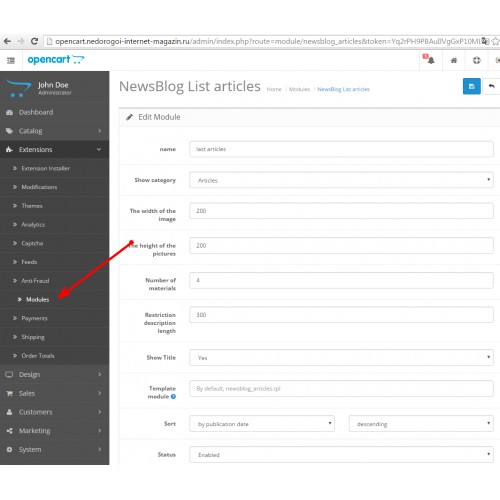
Продолжительность — Введите количество раз, которое пользователь будет совершать платежи до истечения пробного периода.
Цикл — Введите цикл оплаты пробного профиля.
Периодичность — Выберите продолжительность пробной версии — День , Неделя , Месяц , Полумесяц , Год .
Пробный статус — Здесь вам нужно выбрать «Включено», чтобы использовать пробный профиль. В противном случае выберите «Отключено» и оставьте параметры пустыми.
Порядок сортировки — Здесь вы можете установить порядок повторяющегося профиля.
Когда закончите, нажмите кнопку Сохранить . Администратор увидит новый профиль, указанный на странице «Повторяющиеся профили».
Теперь, чтобы использовать этот новый повторяющийся профиль, он должен быть назначен продукту и группе клиентов.
Назначить повторяющийся профиль продукту
Чтобы назначить повторяющийся профиль продукту. Перейдите к Каталог->Продукты . Либо выберите существующий продукт и нажмите «Изменить», либо «Добавить новый продукт».
После ввода всех необходимых сведений о новом продукте. Перейдите на вкладку Recurring , как показано на снимке экрана ниже:
Сначала выберите Recurring Profile из списка. Затем выберите в меню группу клиентов .
Наконец, нажмите кнопку Сохранить , чтобы применить изменения.
Управление продавцом
После установки модуля продавцы увидят пункт меню Повторяющиеся профили в разделе Моя учетная запись.
Теперь продавцы могут управлять повторяющимися профилями отсюда. Продавец может просматривать все созданные повторяющиеся профили.
Добавить — нажмите кнопку «Добавить», чтобы создать новый повторяющийся профиль.
Редактировать — Нажмите кнопку «Редактировать», чтобы обновить существующий повторяющийся профиль.
Удалить — для удаления повторяющегося профиля. Сначала выберите повторяющийся профиль, а затем нажмите кнопку «Удалить».
Добавить повторяющийся профиль
Как только продавец нажмет кнопку Добавить , появятся следующие параметры для добавления повторяющегося профиля.
Имя — Введите имя повторяющегося имени профиля. Это будет название подписки или тарифного плана.
Цена – Установите стоимость этого повторяющегося профиля. Это будет цена подписки или тарифного плана.
Продолжительность — Введите количество раз, которое пользователь будет совершать платежи. Установите его на 0 (ноль) без ограничений. Если безлимитный, план платежей будет продолжаться до тех пор, пока не будет отменен администратором или пользователем.
Цикл — Введите платежный цикл для повторяющегося профиля.
Частота – Выберите время для осуществления платежей – День , Неделя , Месяц , Полумесяц , Год .
Статус – Выберите Включено , чтобы использовать этот повторяющийся профиль, в противном случае выберите Отключено .
Пробный профиль
Продавец также может создать пробный профиль для повторяющегося профиля. Если пробный статус включен, продавец должен предоставить следующие данные:
Цена – Установите цену за использование пробного профиля.
Продолжительность — Введите количество раз, которое пользователь будет совершать платежи до истечения пробного периода.
Цикл — Введите цикл оплаты пробного профиля.
Частота – Выберите продолжительность пробной версии — День , Неделя , Месяц , Полумесяц , Год .
Пробный статус — Здесь вам нужно выбрать «Включено», чтобы использовать пробный профиль. В противном случае выберите «Отключено» и оставьте параметры пустыми.
Порядок сортировки – Здесь вы можете установить порядок повторяющегося профиля.
Когда закончите, нажмите кнопку Сохранить . Продавец увидит новый профиль, указанный на странице «Повторяющиеся профили».
Теперь, чтобы использовать этот новый повторяющийся профиль, он должен быть назначен продукту и группе клиентов.
Назначить повторяющийся профиль продукту
Чтобы назначить повторяющийся профиль продукту. Перейдите к Учетной записи ->Список продуктов->Продукт . Либо выберите существующий продукт и нажмите «Изменить», либо «Добавить новый продукт».
После ввода всех необходимых сведений о новом продукте. Перейдите на вкладку Recurring , как показано на снимке экрана ниже:
Сначала выберите из списка повторяющийся профиль .