Содержание
Использование индексов в СУБД MySQL
В СУБД MySQL индексы являются основным средством ускорения доступа к содержимому таблиц; особенное это касается запросов, включающих объединение нескольких таблиц.
СУБД MySQL использует индексы в нескольких аспектах:
- индексы используются для поиска строк, соответствующих условиям предложения
WHERE, или строк, имеющих соответствия в других таблицах при выполнении объединения. - для ускорения поиска максимального или минимального значения индексируемого столбца при работе с функциями
MIN()илиMAX(). - для ускорения сортировки с помощью конструкции
ORDER BYиGROUP BY. - иногда СУБД может избежать чтения из файла данных вообще, при выборке только индексированного столбца.
Существуют достаточно гибкие способы создания индексов:
- таблицу можно индексировать по одному или нескольким столбцам
- индексу может быть задан режим содержания повторяющихся или уникальных значений
- для оптимизации различных запросов одна таблица может иметь более одного индекса, опирающегося на различные столбцы (комбинации столбцов)
- любой строковый тип (кроме
ENUMиSET) можно индексировать по первымnсимволам слева (нельзя создавать индексы по столбцам типаBLOBиTEXT, пока не задана длина префикса).
- для таблиц типа
InnoDBиндекс может строиться на внешних ключах, то есть значения в индексе должны соответствовать значениям, представленным в другой таблице.

При использовании индексов существуют ограничения, но по мере развития СУБД они сужаются. Свои особенности накладывают выбранные механизмы хранения, например, если применить индекс FULLTEXT, необходимо использовать только таблицы типа MyISAM, а если требуется установить внешние ключи, то необходимо работать с таблицами типа InnoDB.
Для создания индекса index_name по таблице table_name необходимо выполнить запрос:
CREATE [ UNIQUE | FULLTEXT | SPATIAL ] INDEX index_name [ USING = index_type ] ON table_name (index_columns)
Ключевые слова UNIQUE, FULLTEXT и SPATIAL могут добавляться для отображения специфический свойств индекса. Если ни одно из них не задано, создается не уникальный индекс. Оператор
Оператор CREATE INDEX не может быть использован для создания индекса PRIMARY KEY, для этого необходимо использовать оператор ALTER TABLE.
ALTER TABLE table_name ADD PRIMARY KEY (index_columns) ALTER TABLE table_name ADD INDEX [index_name] (index_columns) ALTER TABLE table_name ADD FULLTEXT [KEY | INDEX] [index_name] (index_columns) ALTER TABLE table_name ADD UNIQUE (index_name) (index_columns) ALTER TABLE table_name ADD SPATIAL [KEY | INDEX] [index_name] (index_columns)
Если указано несколько столбцов, то из имена следует разделять запятыми. Если имя индекса index_name не определено, оно создается автоматически на основе первого индексируемого столбца. Кроме того, оператор ALTER TABLE позволяет удалять индексы:
ALTER TABLE table_name DROP [KEY | INDEX] index_name ALTER TABLE table_name DROP PRIMARY KEY
Индексы можно удалять с помощью оператора DROP INDEX:
DROP INDEX index_name ON table_name DROP INDEX `PRIMARY` ON table_name
Для определения алгоритма индексирования можно использовать оператор USING.
TYPE является синонимом USING, для таблиц типа MyISAM и InnoDB это может быть BTREE. Для таблиц типа MEMORY это может быть HASH или BTREE.
У составных индексов существует особенность использования, которая определяется тем, что при наличии такого индекса, например, для столбцов (col1, col2, col3), любой крайний левый префикс может быть использован для поиска. То есть нет необходимости дополнительно создавать индексы (col1) и (col1, col2).
Несмотря на все преимущества индексирования, эта операция имеет и недостатки. Во-первых, индексы ускорять поиск данных, но замедляют операции добавления, удаления и модификации в индексируемых столбцах. Это связано с тем, что чем больше индексов имеет таблица, тем больше замедление операций над записями. Во-вторых, индексных файл занимает определенное дисковое пространство. При создании большого количества индексов размер такого файла может быстро достичь максимально возможного (для современных систем максимальный размер файла может быть очень большим).
При создании большого количества индексов размер такого файла может быстро достичь максимально возможного (для современных систем максимальный размер файла может быть очень большим).
Список использованных источников:
- Поль Дюбуа, MySQL, 3-е издание.
- Официальный сайт MySQL
При полном или частичном использовании любых материалов с сайта вы обязаны явным образом указывать ссылку на handyhost.ru в качестве источника.
Индексы в PostgreSQL
Виталий Сушков
Full Stack Developer в DataArt
В статье я расскажу о предназначении и основах принципов работы объектов баз данных — индексов. На примере СУБД PostgreSQL коротко рассмотрим несколько разных типов индексов и классов задач, для которых они применимы. В конце материала поделюсь ссылками на статьи с более глубоким описанием внутреннего устройства индексов в PostgreSQL.
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Предназначение индексов
Простейший метод решения задачи поиска записей в базе данных, удовлетворяющих определенному критерию, — полный перебор. Но с ростом количества записей производительность такого подхода будет заметно падать. Для повышения производительности поиска создаются вспомогательные структуры — индексы. Используя индексы, можно существенно поднять скорость поиска, потому что данные в индексе хранятся в форме, позволяющей нам в процессе поиска не рассматривать области, которые заведомо не могут содержать искомые элементы.
Если провести аналогию между базой данных и книгой, индексами можно считать оглавление книги и предметный указатель. Действительно, если бы у нас не было таких «индексов», для поиска конкретной главы или для поиска определения какого-то понятия пришлось бы листать и читать всю книгу целиком, пока не найдем то, что нужно. Имея оглавление и предметный указатель, нам нужно просмотреть существенно меньший объем данных, после чего мы точно узнаем номер страницы книги, на которой находится то, что мы ищем. Индексы в базах данных по сути устроены так же, как оглавление или как предметный указатель книги.
Индексы в базах данных по сути устроены так же, как оглавление или как предметный указатель книги.
Важно, что использование индексов не только сокращает время поиска в абсолютном выражении, но и уменьшает алгоритмическую сложность процесса поиска. Это значит, что время, необходимое на поиск с помощью индексов, при росте объема базы данных будет расти существенно медленнее, чем при использовании полного перебора.
В качестве примера рассмотрим задачу поиска в списке чисел. Используя перебор элементов списка, в худшем случае, нам придется просмотреть список целиком. Алгоритмическая сложность такого метода — O(n). Но если мы будем хранить наши числа особым образом — отсортированными по возрастанию или по убыванию — сможем использовать алгоритм бинарного поиска.
2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
Допустим, необходимо определить, содержит ли этот отсортированный список число 158. Для этого:
- Смотрим на число в середине списка — 114. Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
 Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.
Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.- Теперь делаем то же самое для правой половины списка. В середине у нее число 134, значит, мы снова можем отбросить элементы левее.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Делаем то же самое для элементов правее 134. В середине у них число 158 — искомый элемент. Поиск закончен.
В итоге метод бинарного поиска дал нам результат всего за три шага. При полном переборе с начала списка нам потребовалось бы 16 шагов. Бинарный поиск имеет алгоритмическую сложность O(log(n)). Используя формулы алгоритмической сложности O(n) и O(log(n)), мы можем оценить, как будет меняться приблизительное количество операций при поиске разными способами с ростом объема данных:
Результат впечатляет. Храня данные в отсортированном виде, мы не только снизили скорость поиска по ним, но и колоссально сократили скорость замедления поиска при росте объема данных.
Храня данные в отсортированном виде, мы не только снизили скорость поиска по ним, но и колоссально сократили скорость замедления поиска при росте объема данных.
Использование индексов в базе данных дает аналогичный результат. Принцип работы одного из важнейших индексов в базе данных (индекс на основе B-дерева) основан именно на рассмотренном нами выше принципе — возможности хранить данные в отсортированном виде.
Индексы в PostgreSQL
В базах данных, таких как PostgreSQL, индекс формируется из значений одного или нескольких столбцов таблицы и указателей на строки этой таблицы.
Рассмотрим запрос:
SELECT * FROM table_name WHERE P(column_name) = 1
Здесь выражение P(column_name) = 1 означает, что значение в колонке column_name удовлетворяет некоторому условию (предикату) P.
В отсутствии индекса для колонки column_name, PostgreSQL для выполнения этого запроса был бы вынужден просмотреть таблицу table_name целиком, вычисляя для каждой строки значение предиката P и, если значение истинно, добавлял бы строку к результатам запроса.
Имея индекс для колонки column_name, PostgreSQL может быстро, не просматривая таблицу целиком, получить из индекса указатели на строки таблицы, которые удовлетворяют условию P, и затем уже по этим указателям прочитать данные из таблицы и сформировать результат. Это аналогично тому, как мы, вместо того чтобы просматривать всю книгу целиком, смотрим только ее оглавление, читаем номера страниц, соответствующие интересующим нам главам, а затем переходим на эти страницы.
Предикат P может вычисляться от значения нескольких колонок. В этом случае для ускорения запроса используется индекс, построенный не для одной колонки, а для нескольких. Такие индексы называют составными.
Если мы хотим ускорить выполнение запроса, условие которого вычисляется по одной или нескольким колонкам, в PostgreSQL нам необходимо создать для этих колонок индекс с помощью команды CREATE INDEX:
CREATE INDEX index_name ON table_name (column_name_1, column_name_2,.
 ...)
...)Эта команда имеет большой перечень дополнительных параметров, с полным списком которых можно ознакомиться в документации.
Например, индекс может поддерживать ограничение на уникальность и не допускать появления в таблице нескольких строк, значения индексируемых столбцов у которых совпадают. Для этого при создании индекса указывают ключевое слово UNIQUE:
CREATE UNIQUE INDEX index_name ON table_name (column_name_1, column_name_2,....)
Или мы можем создать индекс не по полю таблицы, а по функции или скалярному выражению с одной или несколькими колонками таблицы (такие индексы называют функциональными или индексами по выражению). Это позволяет быстро находить данные в таблице по результатам вычислений. Например, мы хотим ускорит запрос регистронезависимого поиска по текстовому полю:
SELECT * FROM table_name WHERE lower(text_field) = 'some_string_in_lower_case'
Если мы создадим обычный индекс по полю text_field, он нам никак не поможет, т.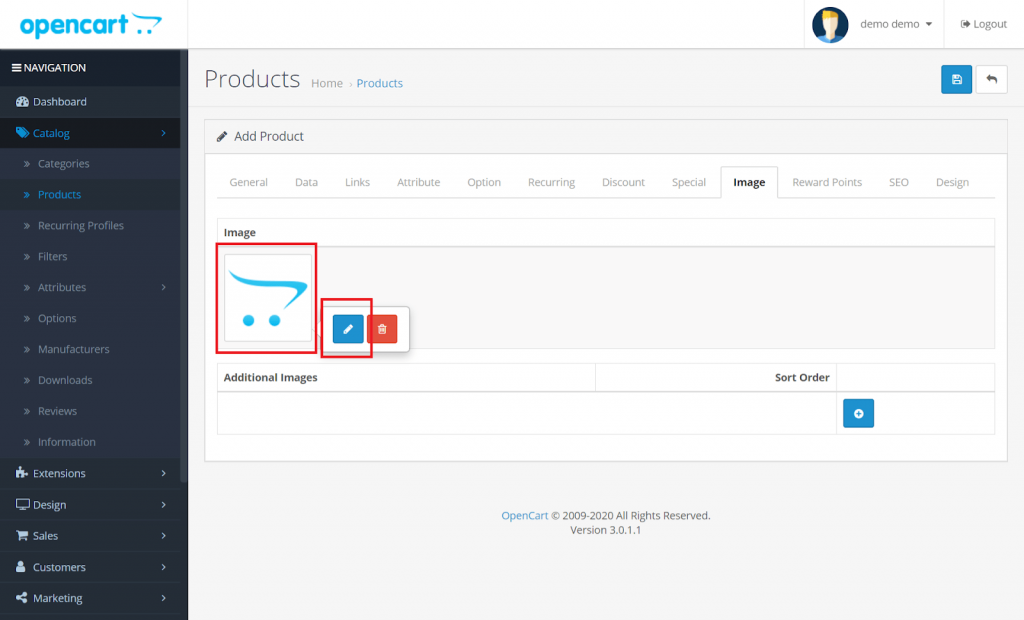 к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции
к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции lower. Однако мы можем создать индекс по результатам вычисления выражения lower(text_fields):
CREATE INDEX index_name ON table_name(lower(text_field))
И такой индекс уже может успешно применяться для ускорения нашего запроса.
В зависимости от типа индексируемых данных, для индексирования применяются разные подходы. По умолчанию при создании индекса используется индекс на основе B-дерева. Но PostgreSQL поддерживает разные типы индексов для очень широкого круга задач, и при необходимости мы можем указать другой тип индекса, отличный от B-tree. Для этого перед списком индексируемых полей необходимо указать директиву USING <тип_индекса>. Например, для использования индекса типа GiST:
CREATE INDEX index_name ON table_name USING GIST (column_name)
B-tree
Этот тип индекса используется по умолчанию и покрывает очень широкий круг задач (базы данных большинства приложений успешно могут обходиться только индексами на основе B-деревьев).
С помощью B-дерева можно проиндексировать любые данные, которые могут быть отсортированы, т. е. для которых применимы операции сравнения больше/меньше/равно. Сюда можно отнести числа, строки, даты и время, логический тип и любые данные, которые можно ими закодировать.
Какой тип запросов может быть ускорен с помощью B-дерева? На самом деле, практически любой запрос, условие которого является выражением, состоящим из полей входящих в индекс, логических операторов и операций равенства/сравнения. Например:
- Найти пользователя по его email:
SELECT * FROM users WHERE email='[email protected]'
- Найти товары одной из двух категорий:
SELECT * FROM goods WHERE category_id = 10 OR category_id = 20
- Найти количество пользователей, зарегистрировавшихся в конкретный месяц:
SELECT COUNT(id) FROM users WHERE reg_date >= 01.01.2021 AND reg_date <= 31.01.2021
Выполнение этих и многих других запросов может быть ускорено с помощью B-дерева. Кроме того, индекс на основе B-дерева ускоряет сортировку результатов, если в
Кроме того, индекс на основе B-дерева ускоряет сортировку результатов, если в ORDER BY указано проиндексированное поле.
Принцип работы индекса на основе B-дерева основан на рассмотренном нами ранее алгоритме бинарного поиска: т. к. все значения упорядочены, мы можем быстро определять области, в которых гарантированно не может быть данных, удовлетворяющих запрос, существенно снижая таким образом количество перебираемых записей.
Однако хранить индекс просто в виде отсортированного массива мы не можем, т. к. данные могут модифицироваться: значения могут меняться, записи — удаляться или добавляться. Чтобы эффективно поддерживать хранение индексируемых данных в отсортированном виде, индекс хранят в виде сбалансированного сильно ветвящегося дерева, называемого B-деревом (B-tree).
Корневой узел B-дерева содержит в упорядоченном виде несколько значений из общего набора, допустим, t элементов. Тогда все остальные элементы можно распределить по t+1 дочерним поддеревьям по следующему правилу:
- Первое поддерево будет содержать элементы, которые меньше, чем 1-й элемент корневого узла (на рисунке выше первое поддерево содержит числа, меньшие 30).
- Второе поддерево будет содержать элементы, которые находятся между 1-м и 2-м элементами корневого узла (на рисунке выше второе поддерево содержит числа между 30 и 70).
- И т. д. — последнее поддерево будет содержать элементы, большие элемента корневого узла с номером t (на рисунке выше третье поддерево содержит элементы, большие 70).
Каждое поддерево, в свою очередь, тоже является B-деревом, имеет корневой элемент и строится далее рекурсивно по такому же принципу.
За счет того что элементы в каждом узле отсортированы, при поиске мы сможем быстро определить, в каком поддереве может находиться искомый элемент, и не рассматривать вообще другие поддеревья. Допустим, нам нужно найти число 67:
- Корневой узел содержит числа 30 и 70, значит, искомый элемент следует искать во втором поддереве, т.к. 67 > 30 и 67 < 70.
- Корневой узел второго поддерева содержит элементы 40 и 50. Т. к. 67 > 50, искомый элемент следует искать в третьем потомке этого узла.
- На третьем шаге мы получили узел, не имеющий потомков, среди элементов которого находим искомое число 67.
Таким образом, при поиске в B-дереве необходимо максимум h раз выполнить линейный или бинарный поиск в относительно небольших списках, где h — это высота дерева. Т.к. B-дерево — сильно-ветвящееся и сбалансированное (т. е. при его построении и модификации применяются алгоритмы, сохраняющие его высоту минимальной, см. статью), число h обычно совсем невелико, и при росте общего количества элементов оно растет логарифмически. Как мы уже видели ранее, это приносит очень хорошие результаты.
Кроме того, важное и полезное свойство B-дерева при его использовании в СУБД — возможность эффективно хранить его во внешней памяти. Каждый узел B-дерева обычно хранит такой объем данных, который может быть эффективно записан на диск или прочитан за одну операцию ввода-вывода. B-дерево даже может не помещаться целиком в оперативной памяти. В этом случае СУБД может держать в памяти только узлы верхнего уровня (которые вероятно будут часто использоваться при поиске), читая узлы нижних уровней только при необходимости.
Индекс на основе B-дерева может ускорять запросы, которые используют не целиком входящие в индекс поля, а любую часть, начиная с начала. Например, индекс может ускорить запрос LIKE для поиска строк, которые начинаются с заданной подстроки:
SELECT * FROM table_name WHERE text_field LIKE 'start_substring%'
Если индекс построен по нескольким колонкам, он может ускорять запросы, в которых фигурируют одна или несколько первых колонок. Поэтому важен порядок, в котором мы указываем колонки при создании индекса. Допустим, у нас есть индекс по колонкам col_1 и col_2. Тогда он может использоваться в том числе для ускорения запроса вида:
SELECT * FROM table_name WHERE col_1 = 123
И нам не нужно создавать отдельный индекс для колонки col_1. Будет использоваться составной индекс (col_1, col_2).
Однако для запроса только по колонке col_2 такой составной индекс уже использовать не получится.
Подробнее, как индекс на основе B-дерева реализован в PostgreSQL, см. статью.
статью.
GiST и SP-GiST
GiST — сокращение от «generalized search tree». Это сбалансированное дерево поиска, точно так же, как и рассмотренный ранее b-tree. Но b-tree применимо только к тем типам данных, для которых имеет смысл операция сравнения и есть возможность упорядочивания. Но PostgreSQL позволяет хранить и такие данные, для которых операция упорядочивания не имеет смысла, например, геоданные и геометрические объекты.
Тут на помощь приходит индексный метод GiST. Он позволяет распределить данные любого типа по сбалансированному дереву и использовать это дерево для поиска по самым разным условиям. Если при построении B-дерева мы сортируем все множество объектов и делим его на части по принципу больше-меньше, при построении GiST индексов можно реализовать любой принцип разбиения любого множества объектов.
Например, в GiST-индекс можно уложить R-дерево для пространственных данных с поддержкой операторов взаимного расположения (находится слева, справа; содержит и т. д.). Такой индекс доступен в PostgreSQL и может быть полезен при разработке геоинформационных систем, в которых возникают запросы вида «получить множество объектов на карте, находящихся от заданной точки на расстоянии не более 1 км».
д.). Такой индекс доступен в PostgreSQL и может быть полезен при разработке геоинформационных систем, в которых возникают запросы вида «получить множество объектов на карте, находящихся от заданной точки на расстоянии не более 1 км».
SP-GiST похож GiST, но он позволяет создавать несбалансированные деревья. Такие деревья могут быть полезны при разбиении множества на непересекающиеся объекты. Буквы SP означают space partitioning. К такому типу индексов можно отнести kd-деревья, реализация которых присутствует в PostgreSQL. Его, как и R-дерево, можно использовать для ускорения запросов геометрического поиска. Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты, что усложняет их эффективное хранение во внешней памяти.
Кроме того, GiST и SP-GiST могут служить своеобразным фреймворком, облегчающим расширение PostgreSQL и добавление в него совершенно новых видов деревьев для индексации новых типов данных.
Подробнее об алгоритмах, лежащих в основе R- и kd-деревьев см. раз и два, а об их реализации и использовании в PostgreSQL см. в этой и этой статье.
Заключение
Индексы — важнейший инструмент баз данных, ускоряющий поиск. Он не бесплатен, создавать много индексов без лишней необходимости не стоит — индексы занимают дополнительную память, и при любом обновлении проиндексированных данных СУБД должна выполнять дополнительную работу по поддержанию индекса в актуальном состоянии.
PostgreSQL поддерживает разные типы индексов для разных задач:
- B-дерево покрывает широчайший класс задач, т. к. применимо к любым данным, которые можно отсортировать.
- GiST и SP-GiST могут быть полезны при работе с геометрическими объектами и для создания совершенно новых типов индексов для новых типов данных.
- За рамками этой статьи оказался ещё один важный тип индексов — GIN. GIN индексы полезны для организации полнотекстового поиска и для индексации таких типов данных, как массивы или jsonb. Подробнее см. в статье. Современные версии PostgreSQL имеют вариацию такого индекса под названием RUM (см. статью).
 Подробнее см. в статье. Современные версии PostgreSQL имеют вариацию такого индекса под названием RUM (см. статью).
Подробнее см. в статье. Современные версии PostgreSQL имеют вариацию такого индекса под названием RUM (см. статью).Ссылки на полезные материалы
- Создание индекса в PostgreSQL
- Алгоритмы работы с B-деревом
- Релизация B-дерева в PostgreSQL
- R-дерево
- Kd-дерево
- Индекс типа GiST в PostgreSQL
- Индекс типа SP-GiST в PostgreSQL
- Индекс типа GIN в PostgreSQL
- Индекс типа RUM в PostgreSQL
OpenCart Elasticsearch | Расширенный механизм поиска поставщиков на основе Lucene
Извлеките содержимое папки получения zip в вашей системе в соответствии с вашей версией Opencart. Извлеченная папка содержит admin , catalog , ocmod , system composer.json и cronindex.php папки. Теперь загрузите каталоги admin , catalog, system, system composer.json и cronindex.php в корневой каталог Opencart 9. 0004, как показано ниже на снимке экрана.
0004, как показано ниже на снимке экрана.
Выполнить команды
После загрузки файлов выполните следующие команды в терминале для установки файла composer.json.
curl -s http://getcomposer.org/installer | php
php composer.phar install
Примечание: – Необходимо увеличить post_max_size до 200M.
После того, как вы загрузили папки, войдите в систему с правами администратора, а затем из раздела каталога перейдите к пункту 9.0003 Extensions> Extension Installer , затем загрузите файл XML . Файл XML находится в папке ocmod в каталоге модуля. В папке ocmod выберите версию Opencart, которую вы используете, затем под ней вы найдете файл wk_elastic_search.ocmod.xml .
После загрузки XML-файла перейдите к Extensions > Modification , затем щелкните поле Refresh .
Перейдите к Система -> Пользователи -> Группы пользователей затем отредактируйте «Администратор» и выберите выберите все для обоих Доступ и Изменить разрешение для разрешения, которое вы хотите предоставить затем сохранить его.
Конфигурация модуля — OpenCart Elasticsearch
Выполнив вышеуказанные шаги, вы увидите модуль в разделе Extensions > Модули > Opencart Эластичный поиск. Здесь вы можете установить затем отредактировать модуль по мере необходимости.
Настройка заданий Cron
После установки модуля владелец магазина или администратор настроит задание Cron. Просто войдите в учетную запись панели c, затем нажмите Cron Job.
Чтобы найти путь к каталогу PHP, перейдите в терминал и войдите в свою учетную запись ssh, используя команду « ssh [email protected]/host ‘. После этого найдите путь PHP, выполнив эту команду «, где php ».
После этого найдите путь PHP, выполнив эту команду «, где php ».
Теперь скопируйте usr/bin/php и напишите
в разделе команд, за которым следует путь к файлу Webkul ElasticSearch, как показано ниже.
Нажмите кнопку редактирования , чтобы настроить модуль.
Сначала выберите магазин , для которого вы хотите реализовать эластичный поиск. Этот вариант предназначен для конфигурации с несколькими магазинами . .
Теперь администратор настроит параметры на вкладке Общие настройки —
Общие настройки
- Выберите Статус поисковой системы Elastic как Включено / 0 Требуется 1
- Введите адрес хоста Elasticsearch (IP-адрес сервера с установленным Elasticsearch)
- Введите номер порта Elasticsearch (сервер с установленным Elasticsearch)
- Префикс индекса используется для создания уникального индекса данных на эластичном сервере.
- Выберите схему Elasticsearch для использования HTTP или HTTPS
- Включите этот параметр, если вы хотите, чтобы продукты искались в соответствии с местоположением пользователя. Для этого необходимо установить Webkul Hyperlocal Extension.
- Выберите Login Authentication для Elastic Server, выбрав Enabled (необходимо ввести имя пользователя и пароль) или выберите Отключено

После этого администратор должен настроить параметры на вкладке Поиск . Здесь у вас есть еще 2 вкладки —
- Общие
Здесь настройте Общие параметры поиска –
- Введите Минимальное количество символов для поиска
- Выберите Перенаправить, если один результат , выбрав Включено или Отключено
- Для поиска В проверьте разделы, в которых вы хотите выполнить поиск на интерфейсе
- Проверьте разделы под опцией Поиск в продукте для , где вы хотите найти продукт
- Для опции Искать в категории Для отметьте разделы, где вы хотите искать
- Поиск в информации проверьте разделы, которые следует искать на информационных страницах.

А под Вкладка «Дизайн » —
«Дизайн»
Ниже приведены два варианта —
- Детали, которые будут отображаться в результатах поиска
- Заполнитель для текстового поля поиска — введите заполнитель для окна поиска переднего плана
Наконец, вы можете нажать кнопку Сохранить в правом верхнем углу, чтобы сохранить настройки конфигурации.
Администратор может щелкнуть Check Elastic Search Data , чтобы просмотреть сохраненные данные.
Он в основном показывает тип/структуру данных, хранящихся (разрешенных для хранения) на эластичном поисковом сервере на основе продуктов, категорий, производителей и информации.
Как подключиться к серверу Elasticsearch?
В разделе Общие в настройках конфигурации после ввода правильных данных нажмите кнопку Кнопка «Проверить статус» в правом верхнем углу.
Это проверяет соединение, и если соединение установлено , вы увидите сообщение с подробностями .
В противном случае, если есть какая-то проблема, вы увидите сообщение об ошибке .
Управление индексом Elastic Search
После успешной установки расширения администратору будет доступен пункт меню Elastic Search под боковой панелью администратора.
Здесь администратор выполнит индексацию для эластичного поиска. Администратор может добавить , изменить и удалить индексы для продуктов , категорий , производителей и информацию.
К добавьте указательным щелчком мыши на кнопку добавления вверху справа.
Здесь, чтобы добавить индекс, введите –
- Имя индекса (каждый символ должен быть в нижнем регистре), а также предопределен Префикс индекса , т. е. elastic_ добавляется перед именем индекса , чтобы сделать каждое поле уникальным от другого.
- Тип индекса (выберите тип индекса для этого сопоставления)
- Количество осколков (Возможность разделить индекс на несколько частей)
- Количество реплик (если узел, содержащий первичный сегмент, умирает, реплика становится первичной)
- Выберите Статус этого индекса как Включено или Выключено
- наконец, нажмите кнопку Сохранить , чтобы сохранить индекс данных
 е. elastic_ добавляется перед именем индекса , чтобы сделать каждое поле уникальным от другого.
е. elastic_ добавляется перед именем индекса , чтобы сделать каждое поле уникальным от другого.Чтобы синхронизировать индекс данных с Elastic Server, нажмите кнопку обновить справа от соответствующего индекса.
Когда данные индекса будут загружены/обновлены, вы увидите соответствующее подтверждение.
Elasticsearch at Work
В интерфейсе клиенты теперь могут использовать Elasticsearch для быстрого поиска в вашем интернет-магазине OpenCart.
Возможно, вы имели в виду: Эта функция позволяет клиентам искать нужные продукты, даже если они по ошибке ввели неправильное название продукта. В этой функции им будут предложены все продукты, которые имеют рядом такое же название продукта.
Для получения более подробной информации об этой функции вы можете перейти по этой ссылке.
Предложения по поиску: когда клиент ищет строку символов, для введенной строки предоставляются предложения. Теперь клиент может щелкнуть любое из предложений, чтобы перейти к выбранному предложению.
Полный поиск по ключевому слову: при поиске по ключевому слову; вместе с предложениями вы видите продукты, отображаемые с ключевым словом.
Описание Поиск: Покупатели также могут искать товары по их описанию.
Поиск по категориям: Клиент может легко найти нужные ему продукты, используя название категории.
Поиск по производителю: здесь клиенты могут легко искать продукты, используя названия производителей.
Поиск на основе информации: Клиент может легко найти продукты, указав заголовок информации в строке поиска, и может найти соответствующие продукты.
Поиск на основе тегов: покупатель может искать желаемые продукты, просто используя теги, связанные с продуктами.
Elasticsearch, интегрированный с Hyperlocal
Модуль помогает клиентам находить товары в зависимости от их местоположения. С помощью этой функции в результаты поиска товаров включаются товары всех тех продавцов, которые находятся в том же регионе, что и покупатель.
Как показано на изображении ниже, чтобы использовать эту функцию, администратор магазина должен включить поле Hyperlocal Status.
Добавить местоположение продавца — Elasticsearch
Во-первых, продавцу необходимо добавить свое местоположение. В результате товар продавцов региона будет виден в результатах поиска покупателей.
Для этого перейдите на панель продавца и нажмите Seller Location > Add Location. Далее просто введите локацию и нажмите Сохранить.
Далее просто введите локацию и нажмите Сохранить.
Получить местоположение клиента — гиперлокальная функция
В интерфейсе клиент может ввести свое местоположение и нажать Продолжить с местоположением.
Кроме того, клиенты могут изменить свое местоположение, как показано на рисунке ниже.
Далее покупатель может искать товары, и ему будут показаны результаты поиска в зависимости от их местонахождения, т.е. товары тех продавцов, которые присутствуют в их регионе.
По любым вопросам или предложениям/запросам на настройку обращайтесь к нам по адресу [email protected] или поднимите заявку на webkul.uvdesk.com
Полный список функций Lightning — OpenCart Lightning
Lightning пожертвовала $5898 на поддержку ВСУ (отчет)
Оптимизация движка
- оптимизированный движок TWIG, который может сэкономить до 70 мс процессорного времени на тяжелых шаблонах
- предобработка событий (система событий работает в десятки раз быстрее)
- часто используемые данные собираются в специальный пакет, который загружается при запуске OpenCart (устраняет необходимость большинства повторяющихся запросов, которые выполняются при каждом создании страницы)
- Запросы MySQL медленнее 0,05 секунды кэшируются с интеллектуальным кеширование записей при изменении данных
- многочисленные оптимизации темы Journal3
- GZIP-сжатие для административной области
- исправлена проблема с производительностью vQMod в OpenCart 3
Кэширование страниц
- кеширование важных страниц (главная, категории, производители и карта сайта) + страницы товаров
- возможность кэшировать все страницы кроме определенного типа (маршрута)
- актуальная мини-корзина монтируется в кэшированную страницу
- актуальный список желаний и номера сравнения монтируются в кешированную страницу
- страницы для авторизованных клиентов создаются из обычных кешированных страниц
- конвертация валюты по тексту кешированной страницы, что позволяет сохранить только один набор кеша с основной валютой
- возможность подгружать некоторые модули по AJAX, заставляя их отображать индивидуальную информацию о кешированных страницах (например, Last Viewed products)
- кеширование AJAX-запросов со страниц, подлежащих кешированию
- фоновая прегенерация страниц кеша на расстояние 2 клика со стартовой или текущей страницы
- любое посещение страницы запускает фоновую прегенерацию страниц, на которые есть ссылки с этой страницы, поэтому посетитель получит следующую страницу из кеша
- необязательные отдельные страницы кеша для мобильных и планшетных устройств
- автоматическое удаление соответствующих страниц кеша при изменении или удалении товаров (отслеживание запросов к базе данных и изменения date_modified внешними скриптами)
- игнорирование параметров URL с информацией из рекламного трафика (таким образом они получают страницу из кеша, а не генерируют новую)
- ответы защиты от перегрузки ботов 503 Проверить позже, когда запрашиваемая страница не кэшируется для всех ботов, кроме Google, Bing и Яндекс, отдельным ботам можно предоставить полный доступ в интерфейсе контроля доступа
Оптимизация внешнего интерфейса (повышение оценки PageSpeed)
- Поддержка изображений WebP с устройствами Apple у всех — запуск JS контролируется куками
- автоматическая установка оптимального уровня сжатия GZIP страниц (настройка в админке игнорируется)
- правильные заголовки статических ресурсов, кеширование и сжатие прописаны в подпапках . htaccess файлы (лучше удалите такие инструкции из корневого файла .htaccess, если вы их добавили)
- Группировка и минификация ресурсов JS и CSS
- корректный перенос всех скриптов в футер страницы
- внешние ресурсы с других серверов включены в групповой файл и минифицированы (на уровнях Агрессивной оптимизации)
- автоматическое создание критических CSS — используется перед загрузкой всего CSS
 htaccess файлы (лучше удалите такие инструкции из корневого файла .htaccess, если вы их добавили)
htaccess файлы (лучше удалите такие инструкции из корневого файла .htaccess, если вы их добавили)SEO-оптимизация
- контрольные суммы всех страниц отслеживаются для обслуживания фактических заголовков Last-Modified, что значительно ускоряет индексацию поисковыми системами
- исправляет канонические, предыдущие и следующие ссылки в категориях уровня 2 и ниже, которые приводили к дублированию страниц категорий
- количество товаров на странице ограничение защиты (ограничено 100). Запросы с огромными лимитами используются для вывода магазина из
- ссылок на товары в форму shop.com/product-url (с указанием пути самой глубокой категории в хлебных крошках). Благодаря этому индексация поисковыми системами становится намного быстрее, а количество страниц, подлежащих кэшированию, резко сокращается.
- auto index.php?route=common/home исправление ссылок на главную страницу
- в robots.txt добавлены специальные инструкции, запрещающие поисковым системам индексировать ненужные страницы (с измененной сортировкой, количеством товаров на странице и т.д.) — ускоряет индексирование и снижает нагрузку от поисковых систем
 Благодаря этому индексация поисковыми системами становится намного быстрее, а количество страниц, подлежащих кэшированию, резко сокращается.
Благодаря этому индексация поисковыми системами становится намного быстрее, а количество страниц, подлежащих кэшированию, резко сокращается.Виджет Lightning в админке
- Отображение загрузки ЦП, нажатие на счетчик ЦП показывает процессы, использующие ЦП, включая обработанные URL-адреса
- кнопка Очистить кэш очищает все кэши (включая системный кэш, и кеш темы JOURNAL), кроме кеша Lightning DB, кнопка Lightning Disable очищает кеш Lightning DB
- отображение статистики — кешированные страницы, запросы AJAX и БД, оптимизированные изображения, среднее TTFB (время генерации страницы) с Lightning и без него
- отображение TTFB в реальном времени последней обслуженной страницы, что позволяет оценить » и скорость магазина
- визуальное отображение всех посещенных страниц в режиме реального времени с указанием IP, агента и времени отклика, при нажатии на него отображается подробная информация о посетителе с картой и возможностью заблокировать его
- Интерфейс управления доступом отображает все правила доступа, включая описания приходящих ботов с возможностью разрешить, заблокировать или отдать им только кешированные страницы
- свободное место на дисплее вашего сервера (помогает отреагировать до того, как ситуация станет критической)
- виджет показывается только пользователям с правом изменять настройку/настройку — таким образом вы можете скрыть виджет от менеджеров
- двойной щелчок по Lightning номер версии переводит виджет в «пользовательский режим», скрывает все, кроме кнопок Включить/Отключить и Очистить кэш вместимость
- фатальные ошибки, возникающие при работе магазина (гораздо нагляднее и информативнее, чем журнал OpenCart)
- отсутствующие файлы JS/CSS
- рекомендация перейти на PHP7, если версия сервера ниже
- рекомендация сменить robots.
