Содержание
Исключенные страницы: документ является неканоническим
Содержание
- Ресурс не найден
- Документ запрещен в файле robots.txt
- Документ является неканоническим
- Читаем из Помощи Яндекса
- Атрибут rel=»canonical» тега <link>
Очень странная произошла вещь с одним сайтом, созданном на OpenCart. Все страницы выпали из индекса Яндекса — осталось только одна — главная. Первая мысль — сайт попал под фильтр. Но это не обычный сайт, а интернет-магазин, который, кстати, приносит доход его владельцу.
Я впервые написал Платону Щукину с просьбой указать причину происшедшего.
Что же это могло произойти? Описание товаров почти все уникальные, сайт еще не продвигался и обратных ссылок пока нет.
baranq / Shutterstock.com
В панели Яндекс.Вебастера в разделе «Исключенные страницы» находится информация о страницах, которые не были проиндексированы роботом.
В этом разделе находится информация о страницах, которые не были проиндексированы роботом при посещении сайта.
Часто индексирование страниц намеренно запрещается вебмастером – это не является ошибкой и исправления не требует. Иногда могут возникать неполадки на стороне вашего сервера или сайта, что ведет к нежелательному исключению страниц, в этом случае проблему рекомендуется устранить.
В настройках вы самостоятельно можете указать, к какой категории относится та или иная причина исключения.
 Часто индексирование страниц намеренно запрещается вебмастером – это не является ошибкой и исправления не требует. Иногда могут возникать неполадки на стороне вашего сервера или сайта, что ведет к нежелательному исключению страниц, в этом случае проблему рекомендуется устранить.
Часто индексирование страниц намеренно запрещается вебмастером – это не является ошибкой и исправления не требует. Иногда могут возникать неполадки на стороне вашего сервера или сайта, что ведет к нежелательному исключению страниц, в этом случае проблему рекомендуется устранить.| Страницы запрещены к индексированию вебмастером или не существуют | ||||
|---|---|---|---|---|
| HTTP-статус: Ресурс не найден (404) | 1 | |||
| Документ запрещен в файле robots.txt | 21 | |||
| Документ является неканоническим | 109 | |||
Я проверил все три категории
Ресурс не найден
Там все ОК, судя по всему кто-то набирал УРЛ в адресной строке и ошибся.
Документ запрещен в файле robots.txt
Я проверил, здесь всё правильно, эти страницы индексировать не нужно.
/index.php?route=account/account |
/index.php?route=account/address |
/index.php?route=account/download |
/index.php?route=account/edit |
/index.php?route=account/forgotten |
/index.php?route=account/login |
/index.php?route=account/newsletter |
/index.php?route=account/order |
/index.php?route=account/password |
/index.php?route=account/register |
/index.php?route=account/return |
/index.php?route=account/return/insert |
З/index.php?route=account/transaction |
/index.php?route=account/wishlist |
/index.php?route=affiliate/account |
/index. |
/index.php?route=checkout/checkout |
/index.php?route=checkout/quickcheckout |
/index.php?route=checkout/voucher |
/index.php?route=product/search |
/index.php?route=product/search&filter_tag=Product Name |
 php?route=checkout/cart
php?route=checkout/cart
Документ является неканоническим
А вот тут уже интересно.
В коде документа в тэге содержится параметр rel=»canonical», содержащий канонический адрес страницы, по которому она индексируется роботом. Как правило, тег с атрибутом rel=»canonical» прописывают на дублирующих страницах сайта, в этом случае ничего исправлять не требуется.
Если страницы дублями не являются и должны индексироваться роботом, то вам необходимо убрать атрибут из их исходного кода. Более подробную информацию об использовании rel=»canonical» вы можете прочитать на следующей странице нашей Помощи.
Также в этом разделе могут присутствовать страницы, содержащие в коде документа мета-тег, и поэтому вместо них индексируются html-версии. Подробнее об индексировании AJAX-сайтов вы также можете прочитать в нашей Помощи.
Далее идет список УРЛ карточек продуктов (здесь их приводить не буду).
Теперь давайте размышлять вместе. Значит так. Что мы имеем? >Недоработку в OpenCart или странную реакцию Яндекса?
Смотрим что находится в коде страницы товара. Да там есть тег <link> с параметром rel=»canonical».
<link href="//site.ru/product-name" rel="canonical" />
Дело в том, что УРЛ, указанный в теге <link> совпадает с УРЛ самой страницы. Она что камикадзе? Что за суицит такой? Я понимаю, если бы УРЛ страницы, в коде которой был бы этот тег, указывающий на оригинал, тогда вопросов нет.
Теперь проверяем страницу этого поста моего блога, который работает на Вордпресс.
<link rel="canonical" href="//www. fortress-design.com/isklyuchennye-stranicy-dokument-yavlyaetsya-nekanonicheskim/" />
fortress-design.com/isklyuchennye-stranicy-dokument-yavlyaetsya-nekanonicheskim/" />
И что? И чем отличаются теги на этих двух страницах? Только тем, что у OpenCart rel="canonical" после ссылки, у WordPress — вначале. Но при этом мой блог отлично индексируется. Почему так? Где логика?
Значит Яндекс думает, что в Опенкарт эти карточки товара неканонические, а являются дублями оригинальных страниц. Но они как раз и являются оригиналами. Мда, наверное придется убирать из кода этот тег. Зачем мне проблемы? То что не нужно, я и сам закрою от индексации в robots.txt.
Читаем из Помощи Яндекса
Атрибут rel=»canonical» тега <link>
Если на сайте присутствуют группы схожих по контенту страниц, вебмастер может указать для каждой страницы группы предпочитаемый (канонический) адрес, который будет участвовать в поиске. Например, страница доступна по двум адресам:
<code>www.site.ru/pages?id=2 www.site.ru/blog</code>
Если предпочитаемый адрес — /blog, это нужно отразить в коде страницы /pages?id=2:
<code><link rel="canonical" href="//www.
 examplesite.ru/blog"/></code>
examplesite.ru/blog"/></code>Робот считает ссылку с атрибутом rel=»canonical» не строгой директивой, а предлагаемым вариантом, который учитывается, но может быть проигнорирован.
Например, робот может не использовать указанный вами адрес, если:
- Документ по каноническому адресу недоступен для индексирования.
- В качестве канонического адреса указывается URL в другом домене или поддомене.
- Вы указали несколько канонических адресов.
как указывать атрибут правильно и зачем он нужен
Главное об атрибуте rel = «canonical”: что это такое, зачем и где указывать, какие ошибки часто допускают оптимизаторы.
Разбираемся, что нужно знать оптимизатору о работе с каноническими тегами. Материал для начинающих или тех, кто хочет освежить знания в памяти.
В статье:
Что такое rel canonical и для чего он нужен
Когда нужно прописывать канонический тег
Как настроить canonical правильно: 6 способов указать основной URL
Что такое rel canonical и для чего он нужен
Одинаковый контент на разных страницах — плохо, за это следуют санкции. Но есть случаи, когда дубли оправданы. К примеру, одна и та же страница может входить в несколько категорий, один и тот же сайт может быть доступен с www и без, а еще в каталогах товаров есть сортировка и фильтрация.
Но есть случаи, когда дубли оправданы. К примеру, одна и та же страница может входить в несколько категорий, один и тот же сайт может быть доступен с www и без, а еще в каталогах товаров есть сортировка и фильтрация.
Страницы могут быть не полностью одинаковыми. К примеру, на одной включен фильтр товаров по сезона, а на другой — сортировка по цене. Тем не менее, от включенных фильтров уникальными они не станут.
Фильтр в каталоге сайта www.asos.com
В таких случаях нужно указывать, какой вариант страницы роботу считать основным, то есть каноническим, а какие дублями. Для этого придумали канонический тег — rel = «canonical», он решает проблему дублирования контента.
Каноническая страница — это основной URL. Атрибут rel = «canonical» добавляют на страницы-дубли и в нем указывают адрес канонической страницы, чтобы дать боту знать, какую страницу они повторяют.
Зачем указывать основную версию страницы?
Причины указывать canonical:
избежать санкций поисковиков за дублирование контента;
корректно передавать ссылочный вес на нужную версию сайта и страницы;
из контента, доступного по нескольким URL, выбрать страницу, которая будет получать все сигналы и показываться в выдаче;
не тратить краулинговый бюджет на дубли.
Краткая информация о канонических URL из первых уст есть в справке Google и Яндекса.
Например, есть страница, доступная по трем адресам:
site.ru/page?id=123
site.ru/blog/category/tema
site.ru/blog/tema
Допустим, мы хотим, чтобы страница site.ru/blog/category/tema ранжировалась в выдаче, получала весь положенный ей ссылочный вес и другие сигналы — считалась канонической.
Тогда эту страницу мы не трогаем, в коде страниц дублей site.ru/page?id=123 и site.ru/blog/tema указываем ее как каноническую. В коды дублей мы добавляем такую строчку:
<link rel="canonical" href="http://site.ru/blog/category/tema"/>
Неканонические страницы не попадут в индекс?
Страницы, отмеченные как неканонические, все равно могут попасть в выдачу. Яндекс отмечает:
«Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом».
В Вебмастере у всех страниц появилась пометка «каноническая», «неканоническая» и «каноническая страница не указана». Вы можно посмотреть неканонические страницы, попавшие в выдачу, для этого откройте «Страницы в поиске» и ищите строчки с пометкой «Неканоническая».
Неканоническая страница в выдаче
Google тоже заявляет, что система признает указанный канонический URL, но не всегда, поскольку тег canonical — рекомендация, а не приказ к действию. Если неканоническая покажется ему релевантнее, она и появится в выдаче.
Но если сеошник указывает этот атрибут, уменьшается риск, что Google сам определит основной не ту версию страницы.
Канонические страницы все равно появляются в поиске чаще и имеют приоритет при показе в выдаче, а ошибки с настройкой canonical могут привести к проблемам в индексировании страниц. Разберем все варианты, когда нужно использовать канонический тег.
Когда нужно прописывать канонический тег
Используйте canonical, когда одинаковый контент доступен по разным URL. Когда дублирующиеся URL создаются системой, фактически сам контент не дублируется — разные URL обслуживают одно содержимое. Тем не менее, это дубли, канонический тег стоит указать. Разберем разные случаи.
Когда дублирующиеся URL создаются системой, фактически сам контент не дублируется — разные URL обслуживают одно содержимое. Тем не менее, это дубли, канонический тег стоит указать. Разберем разные случаи.
Дублирование страниц
Дублирующиеся страницы с похожим содержанием, которые генерируются CMS. Они бывают на всех сайтах интернет-магазинов, где можно настраивать параметры выбора товара. Ссылки для навигации по каталогу, сортировка товаров, фильтрация, ссылки с UTM-метками для отслеживания, другие страницы с GET-параметрами в URL.
К примеру, если в каталоге есть несколько позиций одного дивана, отличающиеся только цветом обивки, можно выбрать самый популярный вариант и указать его каноническим. Все варианты диванов будут доступны пользователям, но ссылочный вес и другие сигналы будут идти на страницу с основным вариантом.
Другой вариант — страница товара подходит сразу под несколько категорий, так что образовываются множественные URL одного предмета. Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Страницы пагинации
Переключение страниц в каталоге рождает дубли. Иногда для всех страниц пагинации указывают первую страницу в качестве канонической — это советуют не делать, потому что тогда проиндексируется только первая страница.
Пагинация на сайте www.petshop.ru
Вариант 1
Если на странице есть «Показать все», страница со всеми вариантами и будет канонической. На каждой из страниц пагинации укажите ее в атрибуте rel = «canonical».
Например, для страницы https:=»» site.ru=»» <=»» a>category1=»» page-2″=»»>https://site.ru/category1/page-2 нужно прописать канонический URL:
<link rel="canonical" href="http://site.ru/category1/show-all">
Вариант 2
Если «Показать все» нет, для каждой страницы пагинации советуют указывать эти же страницы как канонические.
Например, на странице https://site. ru/category1/page2 нужно указать каноническую ссылку:
ru/category1/page2 нужно указать каноническую ссылку:
<link rel="canonical" href="http://site.ru/category1/page2">
Вариант 3
Есть и другое мнение: если указать canonical страницы саму на себя, все страницы пагинации пойдут в выдачу. Если вы считаете, что плохо, если у разных URL с отличающимся контентом будут одинаковые Title и Description, то не делайте так.
В таком случае не нужно проставлять canonical, а лучше закрыть страницы пагинации в noindex, follow и использовать dissalow в robots для /page. Это значит, что индексировать нельзя, а переходить по ссылкам можно.
<meta name="robots" content="noindex, follow"/>
Напомним, что noindex подходит только для Яндекса.
HTTPS, HTTP, www
Один сайт может быть доступен по трем вариантам: http://site.ru и http://www.site.ru и https://www.site.ru. Но поисковые системы будут рассматривать все три как наборы отдельных страниц, если не указать canonical. Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Мобильный URL
Google уже давно переходит на Mobile-First Indexing, то есть при индексировании он ориентируется на мобильную версию сайта.
Представитель Google Джон Мюллер рассказал, что делать с каноническим тегом в этих условиях.
Если у вас есть мобильная версия сайта m.site.ru, обычно у нее указывают rel = «canonical», ведущий на десктопную. А для десктопной используют тег rel=alternate, ведущий на мобильную. Если вы сделали так, ничего менять не надо. Бот распознает мобильную версию как каноническую, даже если в коде канонической указана десктопная. Если и в Sitemap.xml также, то тоже можно не трогать.
URL страны
Бывает, что для конкретной страны у сайта есть несколько версий с разными URL. При этом язык один и контент одинаковый с несущественными отличиями. Тогда нужно выбрать каноническую и сделать отсылки к ней на всех дублях.
Но если речь идет о разных языковых версиях, нужно использовать hreflang, чтобы поисковики выдавали отдельные результаты. Атрибут hreflang нужен для указания дополнительных URL с аналогичным или похожим содержимым на других языках или для отдельных регионов.
Из-за перехода Google на Mobile-First Indexing, нужно правильно настроить hreflang. Десктопные hreflang-теги должны ссылаться на десктопные URL, мобильные — соответственно на мобильные URL. И редиректить пользователей на нужную версию в зависимости от устройства.
Верхний и нижний регистр
Поисковик может посчитать разными два адреса, написанные в разном регистре. При назначении URL система должна применять только нижний регистр, чтобы одни и те же ссылки были действительно одинаковыми.
Материал по теме:
Htaccess для перенаправления верхнего регистра на нижний
Итак, с помощью rel = «canonical» можно указать поисковику, какую страницу считать основной и главной среди дублей, чтобы сканировать ее, индексировать, показывать в выдаче и направлять на нее ссылочный вес. Разберемся, как настраивать тег.
Разберемся, как настраивать тег.
Как настроить canonical правильно: 6 способов указать основной URL
Для использования канонического тега нужно выбрать среди дублей основной URL, вписать его в атрибут:
<link rel="canonical" href="http://site.ru/page/">
и добавить ко всем неосновным страницам.
Для добавления есть несколько способов:
С помощью плагина CMS
Большинство CMS имеют встроенную функцию или плагины, которые позволяют автоматизировать настройку канонического URL.
К примеру:
настроить canonical на WordPress можно с помощью плагина Yoast SEO;
в OpenCart в настройках товара можно задать SEO URL;
в Joomla версии от 3 и выше можно включить функцию SEF. Тогда в код технических страниц вида /index.php?option добавится атрибут rel = «canonical» с указанием основной страницы с ЧПУ.

Для примера подробнее рассмотрим WordPress как самую популярную CMS среди наших подписчиков.
Настройка canonical WordPress
Все просто: установите плагин Yoast SEO, чтобы канонические теги добавлялись автоматически.
Настроить теги для конкретной страницы можно в разделе «Дополнительно» («Advanced»), там нужно указать основной URL:
Настройка канонического тега WordPress
Yoast SEO делает так, что если на странице появляется noindex или nofollow, тег canonical пропадает, чтобы не было проблем с представлением сайта в выдаче.
Если вы не используете CMS и не можете реализовать канонический тег плагинами, можно сделать все иначе.
Прописать между тегами любой HTML-страницы
Основной способ — прописать rel = «canonical» в секцию < head > любой страницы-копии.
Например, если для страницы https://site.ru/*utm_content= канонической будет https://site. ru/, на страницу https://site.ru/*utm_content= нужно добавить код:
ru/, на страницу https://site.ru/*utm_content= нужно добавить код:
<link rel="canonical" href="http://site.ru/">
В заголовке HTTP
У PDF и других не HTML документов нет секции < head >, так что использовать предыдущий способ не получится. Если у вас есть доступ к настройкам сервера, можно указать канонический тег в заголовке HTTP с использованием .htaccess или PHP.
При запросе дублирующего файла сервер должен отдавать в заголовке ссылку на оригинальный файл:
Link: <http://example.com/file.pdf>; rel="canonical"
К примеру, вы составили руководство, выложили его в блог и отдельно оформили в PDF-файл для скачивания, который разместили в подкаталоге http://site.ru/blog/*. HTTP-заголовок для этого руководства в PDF может выглядеть так:
HTTP/1.1 200 OK Content-Type: application/pdf Link: <http://site.ru/blog/canonical-tags/>; rel="canonical"
С другими страницами так тоже можно.
В файле Sitemap
Поисковики по умолчанию думают обо всех ссылках в XML-файле как о канонических. У Google есть требование включать в Карту сайта только канонические адреса страниц. Но Карта не свод правил для поисковых ботов, а список рекомендаций, который поисковики могут проигнорировать.
Материал по теме:
Как составить Sitemap
Через 301 редирект
Отвести трафик и ссылочный вес от дублей к канонической страницы можно с помощью 301 редиректа. Этот способ можно использовать, если сайт, к примеру, доступен по нескольким адресам:
https://site.ru/
http://site.ru/
http://www.site.ru/
https://www.site.ru/
Можно выбрать в качестве основного https://site.ru/, а со всех остальных настроить перенаправление.
Материал по теме:
Как настроить 301 редирект самостоятельно
Дополнительный сигнал — ссылки
Представитель Google Джон Мюллер в этом видео перечислял все сигналы, которые поисковик использует для определения канонического адреса.
К примеру, между адресами HTTPS и HTTP Google выберет HTTPS, а еще он может предпочесть привлекательный с его точки зрения URL. В числе сигналов каноникализации числятся ссылки с одной страницы на другую. Если вы указали канонической одну страницу, а по совокупности факторов другая кажется поисковику более подходящей, он не будет вас слушать.
Неправильной настройкой можно навредить индексированию страниц. Разберем несколько типичных ошибок оптимизаторов.
Неправильно указан canonical: популярные ошибки настройки
Использование нескольких канонических ссылок для одной страницы
Для одной страницы нужно указать один канонический адрес. Если указано несколько, бот либо проигнорирует страницу вообще, либо примет к сведению первый указанный URL.
Проверяйте, как плагин CMS реализует canonical, иногда из-за неправильной настройки он может указывать несколько адресов.
Настройка разных канонических URL одной странице
Похожий пункт, но речь идет не о нескольких канонических адресах для одной страницы, а в о разных, указанных разными способами.
Если вы используете несколько способов указать канонический тег, например, в HTTP-заголовке и в секции < head >, ссылка на основную страницу должна быть одна и та же.
Настройка цепочки канонических URL
Бот не будет учитывать канонический адрес, если для страницы, которую вы указали основной, настроена какая-то своя основная страница. Например, для адреса site.ru/1 канонической ссылкой указана site.ru/2, а для нее указана site.ru/3.
Размещение rel = «canonical» не в секции head
Тег rel = «canonical» должен находиться только в секции < head >. Если указать его в < body > документа, боты его проигнорируют. Или даже могут проигнорировать всю страницу.
Лучше перепроверить: даже если вы поставили canonical ближе к началу документа, секция < head > может закрыться раньше, например, из-за вставок JavaScript, контейнеров < iframe > или незакрытых парных тегов. Тогда canonical окажется за пределами < head > в секции < body >.
Указание первой страницы пагинации как канонической
Если для всех страниц пагинации канонической указать первую, бот не проиндексирует остальные. Выше мы писали, как лучше сделать, есть три варианта:
сделать канонической страницу «Показать все», если она есть;
для каждой страницы поставить ее же URL в качестве канонической, если нет общей страницы.
Но если вы считаете, что наличие всех страниц пагинации в выдаче плохо повлияет из-за повторяющихся Title и Description, не ставьте канонический тег вообще и закройте их для индексации. Используйте noindex, follow для страниц пагинации и для /page укажите disallow в файле robots. Такая настройка означает, что индексировать нельзя, а переходить по ссылкам можно.
Использование канонических URL вместо 301 редиректа
Тег canonical и 301 редирект кажутся похожими — перенаправляют бота на основную страницу. Но не стоит использовать canonical вместо редиректа. Редирект переводит весь трафик на один URL, а при использовании rel = «canonical» страница откроется, будет активной и сможет получать трафик, но не появится в индексе.
Но не стоит использовать canonical вместо редиректа. Редирект переводит весь трафик на один URL, а при использовании rel = «canonical» страница откроется, будет активной и сможет получать трафик, но не появится в индексе.
Выбор главной как канонической для всех страниц
Ошибкой будет указать главную страницу в качестве канонической для всего сайта. Боты могут проигнорировать все страницы, кроме главной.
Закрытие канонической страницы от индексирования
Если канонический URL закрыт от индексирования или по другой причине недоступен для поискового бота, он не сможет участвовать в формировании выдачи. В этом случае бот возьмет доступный неканонический URL.
Как проверить canonical
Проверить, для каких страниц вы настроили canonical и какие канонические страницы указали, можно с помощью сервиса Screaming Frog SEO Spider.
Результаты проверки страниц краулером
Узнать, какую страницу Google считает основной для конкретного URL, можно через инструмент проверки URL.
Проверить, как поступил Яндекс, можно в Вебмастере: если вы верно указали каноническую страницу, дубли пропадут из поиска. Посмотрите страницу «Индексирование» — «Страницы в поиске». Если страницу исключили из результатов, она будет в блоке «Исключённые страницы».
Проверка наличия дубля в выдаче
Рассказывайте, о каких необходимых вариантах использования canonical мы забыли, и какие еще ошибки настройки вы встречали в своей практике!
apache — Не работает URL-адрес поисковой оптимизации со старого http на https для названия продукта, а канонические URL-адреса по-прежнему находятся на http вместо https
Раньше у нас был хороший SEO-адрес, такой как domain.com/productname, но в прошлом месяце мы приобрели ssl-сертификат для нашего сайта, теперь все URL-адреса теперь имеют версию https, поэтому эти страницы продуктов изменили свой формат, например, с http: //domain.com/productname, если вы нажмете на ссылку, она станет беспорядочной, как https://www. domain.com/index.php? маршрут = название товара в opencart.
domain.com/index.php? маршрут = название товара в opencart.
Я просто хочу удалить этот index.php? route = параметры URL, чтобы все ссылки стали domain.com/productname. Я также попытался получить GWT, чтобы увидеть, что это не URL-адрес перенаправления. Я также проверил статус заголовка 200.
Канонические URL-адреса по-прежнему находятся в http а не https , и некоторые ссылки на продукты все еще указывают на http вместо https .
До сих пор у меня не было проблем со страницей типа о нас, свяжитесь с нами, они работают нормально. 9?]*) index.php?_route_=$1 [L,QSA]
Также обязательно проверьте это в новом браузере, чтобы избежать кешей старого браузера.
4
другое решение состоит в том, чтобы сделать ssl частью конфигурации вашего веб-сайта, а также разрешить переопределение www/html/ваш_домен. com/public_html»>
com/public_html»>
Разрешить переопределить все
Требовать все предоставленные
внутри
.....
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
канонических URL-адресов в OpenCart
Опубликовано Полом 21 февраля 2014 г.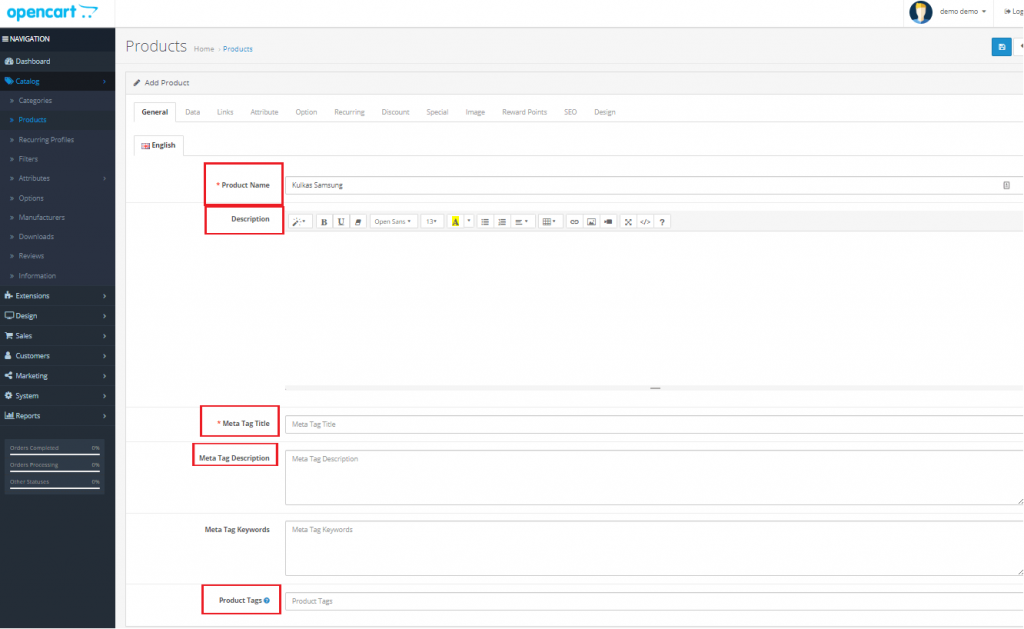
Если вы изучали SEO на любом уровне, вы, вероятно, слышали о канонических URL-адресах. Поэтому мы постараемся ответить на несколько вопросов о них.
Почему такое смешное имя?
Канонический URL-адрес означает 1 URL-адрес определенного веб-сайта или страницы или веб-сайта, который считается окончательным для использования. Оно происходит от слова «канон», означающего единый определенный набор правил или принципов: http://en.wikipedia.org/wiki/Canon_(basic_principle)
Как страница может иметь более одного URL?
Например, можно получить доступ к вашей домашней странице через все 4 разных URL-адреса:
- www.yoursite.com
- yoursite.com
- www.yoursite.com/index.php
- yoursite.com/index.php
Разве это не дублированный контент?
Это дублированный контент, и хотя Google достаточно умен, чтобы понять, что это не плагиат, если он находится на том же веб-сайте, Google все равно должен решить, какую ссылку использовать в результатах поиска. Лучше, если это будешь решать ты.
Лучше, если это будешь решать ты.
Что я могу сделать, чтобы предотвратить это?
Хорошей новостью является то, что OpenCart уже скрывает большинство повторяющихся ссылок в стиле /index.php (хотя в этой статье мы покажем вам, как удалить одну из них).
Но по-прежнему можно получить доступ к вашему сайту через yoursite.com и www.yoursite.com. Поэтому вам нужно изменить его, чтобы всегда перенаправлять на тот или иной. Это ваше личное предпочтение, и если вы уже приобрели сертификат SSL, вам придется придерживаться того, что там есть. Если у вас есть выбор, я бы выбрал вариант с www, потому что он более знаком большинству пользователей.
Как настроить веб-сайт для перенаправления запросов без www на www?
Если у вас есть FTP-доступ к вашему сайту, вам нужно убедиться, что www включен в ссылки в /config.php и /admin/config.php. Таким образом, вы будете на полпути — когда люди будут перемещаться по вашему сайту, они будут перенаправлены, но не раньше, чем они нажмут на ссылку. Чтобы перенаправить всех, если у них есть закладка или они перешли, например, по ссылке на внешнем сайте, вам нужно добавить строку в файл .htaccess. Опять же, вам понадобится FTP-доступ, поэтому спросите об этом своего веб-разработчика, если у вас его нет. Строка для добавления (конечно, измененная для вашего домена): 9(.*)$ «http\:\/\/www\.yoursite\.com\/$1» [R=301,L]
Чтобы перенаправить всех, если у них есть закладка или они перешли, например, по ссылке на внешнем сайте, вам нужно добавить строку в файл .htaccess. Опять же, вам понадобится FTP-доступ, поэтому спросите об этом своего веб-разработчика, если у вас его нет. Строка для добавления (конечно, измененная для вашего домена): 9(.*)$ «http\:\/\/www\.yoursite\.com\/$1» [R=301,L]
Добавление в самый низ в большинстве случаев должно быть приемлемым.
Это так просто?
По сути да, но всегда будьте очень осторожны при изменении файлов конфигурации или .htaccess. Небольшая опечатка может помешать загрузке вашего сайта, поэтому всегда убедитесь, что вы точно знаете, как это было раньше, сделав копию, чтобы вы могли вернуть ее, если она не работает.
Насколько это повлияет на мое SEO?
Совсем немного. Достаточно, чтобы Мэтт Каттс из Google написал об этом статью. Это также сделает просмотр приятным для ваших клиентов, поскольку они всегда будут видеть красивый, согласованный URL-адрес.